Configure your agent to receive data from a log file data source.
Before you begin
Procedure
- On the Agent Initial Data Source page
(Figure 1) or the Data Source Location page, click Logged Data in the Monitoring Data Categories area. Figure 1. Adding a log file
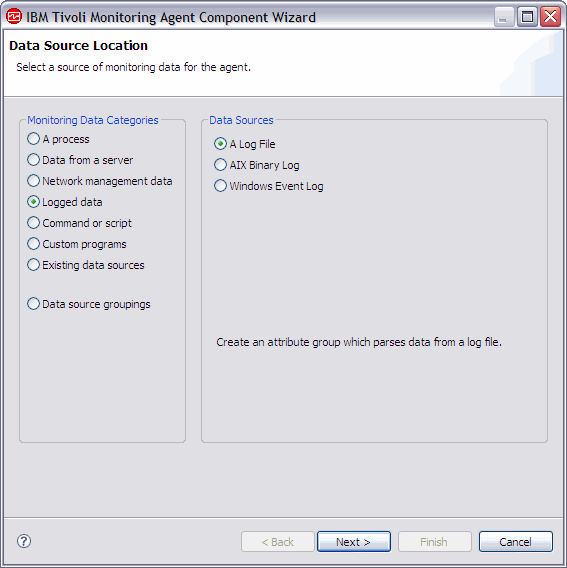
- On the Log File Information page (Figure 2), type the name of the
log file you want to monitor in the Log File Information area. The file name must be fully qualified.Figure 2. Log File Information page
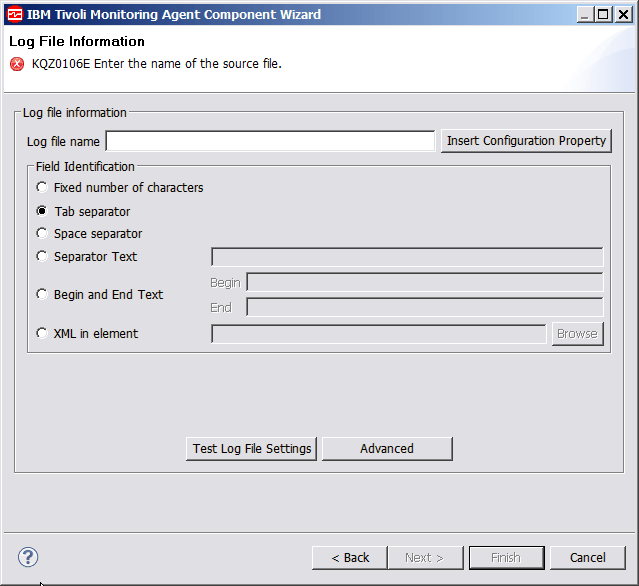
- Optional: Part of the log file name can come from a runtime configuration property. To create a log file name, click Insert Configuration Property and select a configuration property (Figure 1).
- Optional: The file can also be a dynamic file name. For more information, see (Dynamic file name support).
- In the Field Identification area, click one of the following options:
- Fixed number of characters
- When selected, limits the number of characters.
With this option, each attribute is assigned the maximum number of characters it can hold from the log file. For example, if there are three attributes A, B, and C (in that order), and each attribute is a String of maximum length 20. Then, the first 20 bytes of the log record go into A, the second 20 into B, and the next 20 into C.
- Tab separator
- When selected, you can use tab separators.
- Space separator
- When selected, multiple concurrent spaces can be used as a single separator.
- Separator Text
- When selected, type in separator text.
- Begin and End Text
- When selected, type in both Begin and End text.
- XML in element
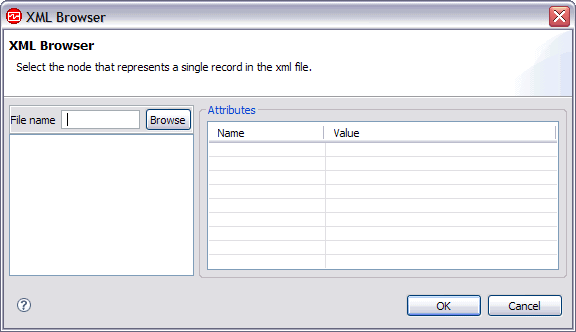
- When selected, type the name of the XML element to use as the
record, or click Browse to define the element. If you clicked Browse, the XML Browser window is displayed (Figure 3). If you use the browse function, the Agent Builder identifies all possible attributes of the record by looking at the child tags and their attributes.Figure 3. XML Browser window
Note: Unless you click Advanced and fill out the information in that window, the following assumptions are made about information that you complete:- Only a log file at a time is monitored.
- Each line of the log file contains all the fields necessary to fill the attributes to be defined.
For more information about log file parsing and separators, see (Log file parsing and separators).
- Optional: Click Advanced on the Log File Information page to do the following by using the Advanced Data Source
Properties page (Figure 4):
- Monitor more than one file, or monitor files with different names on different operating systems or monitor files with names that match regular expressions.
- Draw a set of fields from more than one line in the log file.
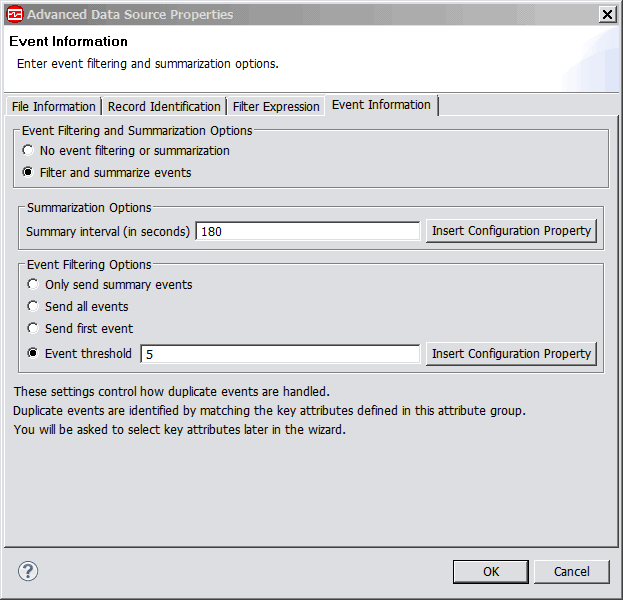
- Choose Event Filtering and Summarization Options.
- Produce output summary information. This summary produces an additional attribute group at each interval. For more information about this attribute group, see (Log File Summary). This function is deprecated by the options available in the Event Information tab.
Figure 4. Advanced Data Source Properties page, File Information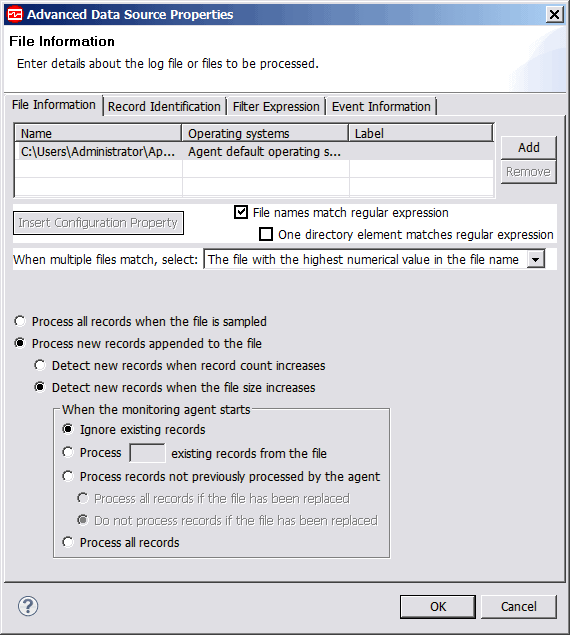
- Click the Record Identification tab (Figure 5) to interpret
multiple lines in the log file as a single logical record. Note: If you select XML in element as the field identification on the Log File Information page, the Record Identification tab does not display.
- Single line interprets each line as a single logical record.
- Separator line you can enter a sequence
of characters that identifies a line that separates one record from
another. Note: The separator line is not part of the previous or the next record.
- Rule identifies a maximum number of lines
that make up a record and optionally a sequence of characters that
indicate the beginning or end of a record. With Rule, you can specify the following properties:
- Maximum non-blank line defines the maximum number of non-blank lines that can be processed by a rule.
- Type of rule: Can be one of:
- No text comparison (The Maximum lines per record indicates a single logical record).
- Identify the beginning of record (Marks the start of the single logical record).
- Identify the end of record (Marks the end of the single logical record).
- Offset: Specifies the location within a line where the Comparison String must occur.
- Comparison Test: Can either be Equals, requiring a character sequence match at the specific offset, or Does not equal, indicating a particular character sequence does not occur at the specific offset.
- Comparison String defines the character sequence to be compared.
- Regular Expression identify a pattern that
is used to indicate the beginning or end of a record. By using Regular Expression, you can specify the following properties:
- Comparison String defines the character
sequence to be matched.
OR
- Beginning or end of record:
- Identify the beginning of record marks the start of the single logical record.
- Identify the end of record marks the end of the single logical record.
- Comparison String defines the character
sequence to be matched.
Figure 5. Advanced Data Source Properties page, Record Identification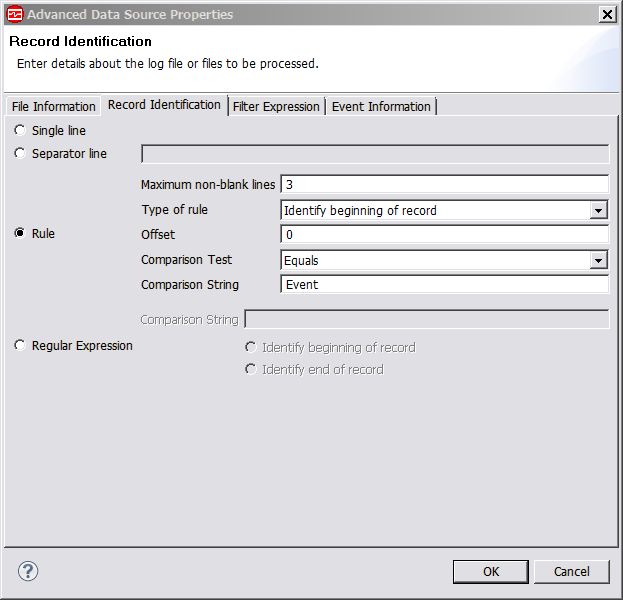
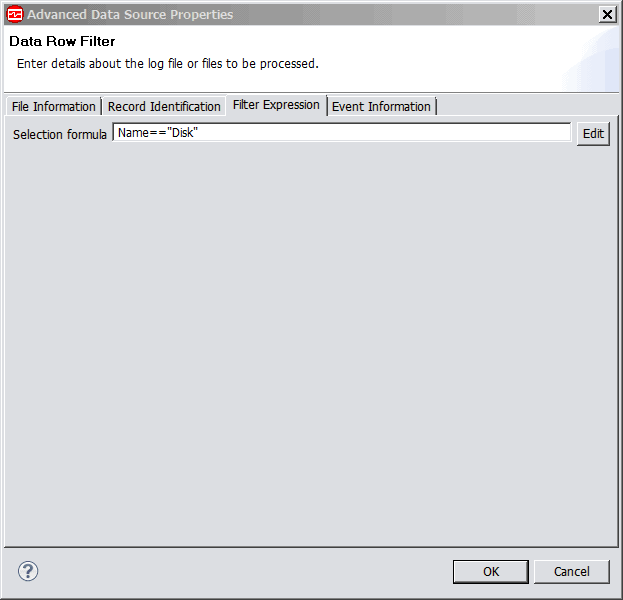
- If you did select Process all records when
the file is sampled earlier, click the Filter
Expression tab. By clicking Filter Expression you can filter the data that is returned as rows based on the values
of one or more attributes, configuration variables or both. If you selected Process new records appended to the file earlier you cannot create a filter expression. For more information
about filtering data from an attribute group, see (Filtering attribute groups). Figure 6. Advanced Data Source Properties page, Filter Expression tab
- If you selected Process new records appended
to the file earlier, click the Event Information tab Figure 7 to select Event Filtering and Summarization Options. For more information, see (Event filtering and summarization). Note: The Summary tab can be present if the agent was created with an earlier version of Agent Builder. The summary tab is now deprecated by the Event Information tabFigure 7. The Event Information tab of the Advanced Data Source Properties page,
- Use the following steps if you did
not use the test function earlier and you typed the log file name
in the Log File Information area of the Log File Information page:
- Click Next to display the Attribute Information page and define the first attribute in the attribute group.
- Specify the information, on the Attribute Information page, and click Finish.
Note: When a log file attribute group is added to an agent at the default minimum Tivoli® Monitoring version (6.2.1) or later, a Log File Status attribute group is included. For more information about the Log File Status attribute group, see (Log File Status attribute group).Figure 8. Attribute Information page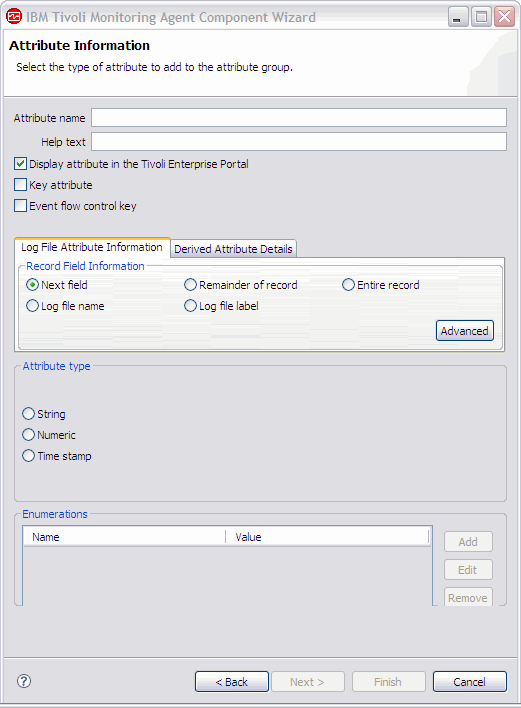
Along with the fields applicable to all data sources, the Attribute Information page for the log file data source has some additional fields in the Record Field Information area.
The Record Field Information fields are:- Next field
- Shows the next field after parsing, by using the delimiters from the attribute group (or special delimiters for this attribute from the Advanced dialog).
- Remainder of record
- Shows the rest of the record after previous attributes are parsed. This attribute is the last attribute, except for possibly the log file name or log file label.
- Entire record
- Shows the entire record, which can be the only attribute, except for possibly the log file name or log file label.
- Log file name
- Shows the name of the log file.
- Log file label
- Shows the label that is assigned to the file on the advanced panel.
Note: Use the Derived Attribute Details tab only if you want a derived attribute, and not an attribute directly from the log file. - Click Advanced in
the Record Field Information area to display
the Advanced Log File Attribute Information page
(Figure 9). Figure 9. Advanced Log File Attribute Information page
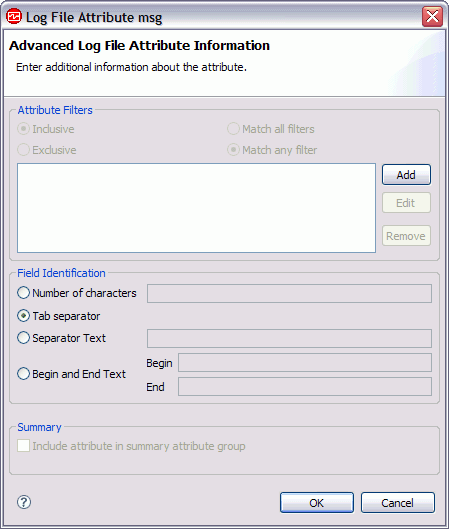
- Use Add, Edit, and Remove to define the individual filters
for an attribute filter set. Figure 10. Add Filter window
- To add a filter, follow these steps:
- Click Add, and complete the options in
the Add Filter window (Figure 10) as follows:
- The Filter criteria section defines the
base characteristics of the filter, including the following properties:
- Starting offset defines the position in the attribute string where the comparison is to begin.
- Comparison string defines the pattern string
against which the attribute is defined.
Type a string, pattern, or regular expression that is used by the agent to filter the data read from the file. The records that match the filter pattern are eliminated from the records that are returned to the Tivoli Enterprise Portal, or are the only records returned. The result depends on whether you choose for the filter to be inclusive or exclusive.
- Match entire value checks for an exact occurrence of the comparison string in the attribute string. Checking starts from the starting offset position.
- Match any part of value checks for the comparison string anywhere in the attribute string. Checking starts from the starting offset position.
- The comparison string is a regular expression indicates that the comparison string is a regular expression pattern
that can be applied against the attribute string.
Regular expression-filtering support is provided by using the International Components for Unicode (ICU) libraries to check whether the attribute value examined matches the specified pattern.
To effectively use regular expression support, you must be familiar with the specifics of how ICU implements regular-expressions. This implementation is not identical to how regular expression support is implemented in Perl, grep, sed, Java™ regular expressions, and other implementations. See ICU regular expressions for guidance on creating regular expression filters.
- Define an override filter indicates that
you want to provide a more specific filter comparison that overrides
the base characteristics previously defined. This additional comparison
string is used to reverse the filter result. When the filter is Inclusive,
the override acts as an exclusion qualifier for the filter expression.
When the filter is Exclusive, the override acts as an inclusion qualifier
for the filter expression. (For more about Inclusive and Exclusive,
see step 9, and the examples
that follow). The override filter has the following properties:
- Starting offset defines the position in the attribute string where the comparison is to begin.
- Comparison string defines the pattern string
against which the attribute is matched.
Type a regular expression that is used by the agent to filter the data read from the file. The records that match the filter pattern are eliminated from the records that are returned to the Tivoli Enterprise Portal, or are the only records returned. The result depends on whether you choose for the filter to be inclusive or exclusive.
- Replacement value can be used to alter the raw attribute string with a new value. See ICU regular expressions for more details about special characters that can be used.
- Replace first occurrence replaces the first occurrence that is matched by the comparison string with new text.
- Replace all occurrences replaces all occurrences that are matched by the comparison string with new text.
- The Filter criteria section defines the
base characteristics of the filter, including the following properties:
- Click OK.
Figure 11. Add Filter example 1If the attribute string is abc is easy as 123, then the replaced string that is displayed in the Tivoli Enterprise Portal as 123 is not as easy as abc.![Add Filter window with ^([a-z]*) is ([a-z]*) as ([0-9]*)$ entered in the comparison string field, the Replacement value box is checked, and $3 is not as $2 as $1 entered in the replacement value field](addfilterexample1.gif) Figure 12. Add Filter example 2If the attribute string is Unrecoverable Error reading from disk, and the filter is Inclusive, then the attribute is displayed in the Tivoli Enterprise Portal. If the attribute string is No Errors Found during weekly backup and the filter is Inclusive, then the attribute is not displayed in the Tivoli Enterprise Portal.
Figure 12. Add Filter example 2If the attribute string is Unrecoverable Error reading from disk, and the filter is Inclusive, then the attribute is displayed in the Tivoli Enterprise Portal. If the attribute string is No Errors Found during weekly backup and the filter is Inclusive, then the attribute is not displayed in the Tivoli Enterprise Portal.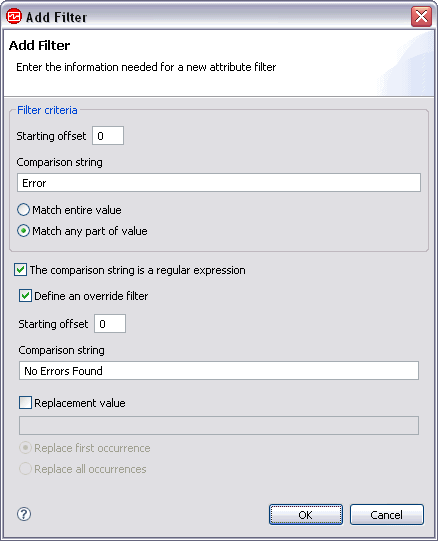
- Click Add, and complete the options in
the Add Filter window (Figure 10) as follows:
- Use Add, Edit, and Remove to define the individual filters
for an attribute filter set.