Batch processor overview
The batch processor is a multithreaded, long-running application that can process large volumes of batch data.
The batch processor can process multiple records from the same batch input simultaneously, and increase the throughput. Additionally, you can run multiple instances of the batch processor simultaneously, each one processing a separate batch input and pointing to the same server, or a different server.
The batch processor architecture diagram shows a high-level view of the batch processor application.
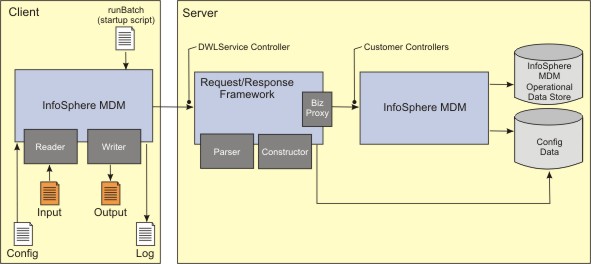
- The reader consumer reads the record from the batch input. A pluggable reader is used to read each record. The reader distinguishes each record in the batch input. The reader does not dissect the record into fields; that is done by the parser. .
- Once the record is read, the submitter consumer sends it to the Request/Response framework for parsing and processing. Selecting the parser is based on the values passed in the context parameter of the server request. The parser transforms the input request into one or more business objects. After passing through business proxy, business processing and persistence logic are applied to the business objects. The application responses are sent to the constructor in order to construct the desired batch output response. Similar to the parser, selecting the constructor is based on the values passed in the context parameter of the server request. The constructed response is returned to the batch processor.
- The pluggable writer consumer returns the response to the batch output destination.
The batch processor handles each record in its unit of work. In other words, it supports a checkpoint of one.
You can define a threshold value to set the maximum number of allowed exceptions. If the number of exceptions reaches this threshold, the batch processor stops further processing of the current batch input and logs runtime messages to a log destination. These logs are useful for diagnosing and debugging issues. A number of runtime parameters are available for configuration. Properties files are used for this configuration. For more information about configuring batch processor options, see Configuring the batch processor.
In addition, the batch processor has the following basic features:
- Gracefully shuts down its batch processes to prevent any data loss.
- Restarts stopped batch jobs from the point where they stopped, even in the event of an unexpected stoppage.
- Provides a heartbeat that enables you to monitor batch jobs while they are being processed.
- The total number of records to be processed in the batch job.
- The total number of successfully processed records.
- The total number of unsuccessfully processed records (failures).
- The termination reason, if batch processing is terminated.
- The time that the batch processor began processing the batch job.
- The time that the batch processor stopped processing the batch job.
- The number of transactions processed per second.
You can define and create customized batch jobs prior to submitting them to the batch processor. For details on creating custom jobs, see Running the batch processor.
When the batch processor reads input directly from input files,
it can either create the batch job automatically or use an explicitly
defined batch job. If you choose to have the processor use an explicitly
defined batch job, you can either define a custom job or choose from
a number of predefined jobs. The predefined batch jobs are located
in the folder $home/templates/jobs (where $home represents the directory where the batch processor
is installed).