
The MpxData sample enables you to configure the InfoSphere® DataStage® Java™ Integration stage to use the functionality of the MpxData utility. MpxData processes several steps, beginning with parsing data into UNL files to deriving data and organizing member records into buckets. MpxData also creates binary files, which are used to compare data faster than scanning through strings. MpxData parses raw data extracts into attribute-specific sets of data.
MpxData can be run in two modes, MEMCOMPUTE and MEMPUT.
When run in MEMCOMPUTE mode, it creates derived data and then creates UNL files that can then be loaded with the MDM load utilities (madhubload and madentload) or MDM Workbench Load UNLs to DB job. Running MpxData in MEMCOMPUTE mode is the most common method for an initial data load because the process can be easily tracked through log files and is faster than MEMPUT.
When MpxData is run in the MEMPUT mode, the data is loaded directly in to the MDM database. MEMPUT inserts or updates members in an existing MDM database for each record in the input file. The parsing of the data is a single step in the process as MpxData loads the information in the MDM database.
The following illustration shows extract data that is being parsed into the MDM data structure.
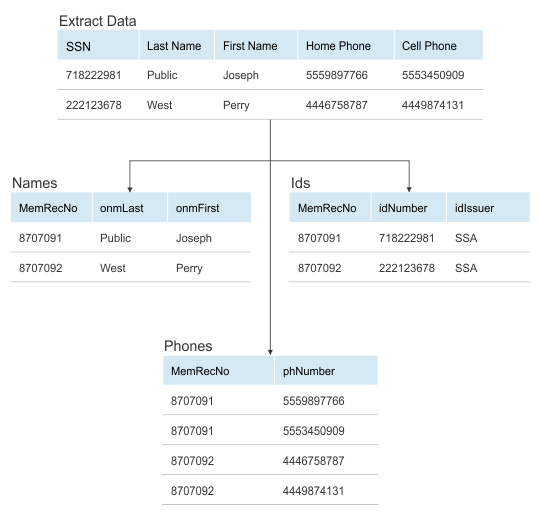
The InfoSphere DataStage MpxData job requires an XML template file that contains the operational parameters for MpxData. This template is created by running the Derive Data and Create UNLs job in MDM Workbench and saving the job template as an XML file. After you create this file, you can manually edit it if necessary. For example, if you are planning to run the InfoSphere DataStage job in MEMPUT mode and you originally had the MEMMODE option set to partial, you can change option in the XML file.