Zones
Zones give you control over shard placement. Zones are user-defined logical groupings of physical servers. The following are examples of different types of zones: different blade servers, chassis of blade servers, floors of a building, buildings, or different geographical locations in a multiple data center environment. Another use case is in a virtualized environment where many server instances, each with a unique IP address, run on the same physical server.
Zones defined between data centers
The classic example and use case for zones is when you have two or more geographically dispersed data centers. Dispersed data centers spread your data grid over different locations for recovery from data center failure. For example, you might want to ensure that you have a full set of asynchronous replica shards for your data grid in a remote data center. With this strategy, you can recover from the failure of the local data center transparently, with no loss of data. Data centers themselves have high speed, low latency networks. However, communication between one data center and another has higher latency. Synchronous replicas are used in each data center where the low latency minimizes the impact of replication on response times. Using asynchronous replication reduces impact on response time. The geographic distance provides availability in case of local data center failure.
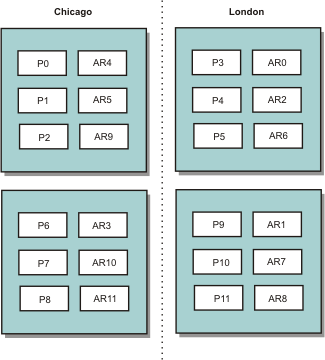
In the following example, primary shards for the Chicago zone have replicas in the London zone. Primary shards for the London zone have replicas in the Chicago zone.
Three configuration settings control shard placement:
- Deployment file
- Group containers
- Specify rules
The following sections explain the different options, presented loosely from least to most complicated.
Development mode
In your deployment XML file, set: developmentMode="false".
This simple step activates the first shard placement policy.
For more information about the XML file, see Deployment policy descriptor XML file.
Policy 1: Shards for the same partition are placed in separate physical servers.
Consider a simple example of a data grid with one replica shard. With this policy, the primary and replica shards for each partition are on different physical servers. If a single physical server fails, no data is lost. The primary or replica shard for each partition are on different physical servers that did not fail, or both are on some other physical server that did not fail.
The high availability and simplicity of this policy make it the most efficient setting for all production environments. In many cases, applying this policy is the only step required for effectively controlling shard placement in your environment.
In applying this policy, a physical server is defined by an IP address. Shards are placed in container servers. Container servers have an IP address, for example, the -listenerHost parameter on the start server script. Multiple container servers can have the same IP address.
Since a physical server has multiple IP addresses, consider the next step for more control of your environment.
Group container servers
Container servers are assigned to zones with the -zone parameter on the start server script. In a WebSphere Application Server environment, zones are defined through node groups with a specific name format: ReplicationZone<Zone>. In this way, you choose the name and membership of your zones. For more information, see Defining zones for container servers.
Policy 2: Shards for the same partition are placed in separate zones.
Consider extending the example of a data grid with one replica shard by deploying it across two data centers. Define each data center as an independent zone. Use a zone name of DC1 for the container servers in the first data center, and DC2 for the container servers in the second data center. With this policy, the primary and replica shards for each partition would be in different data centers. If a data center fails, no data is lost. For each partition, either its primary or replica shard is in the other data center.
With this policy, you can control shard placement by defining zones. You choose your physical or logical boundary or grouping of interest. Then, choose a unique zone name for each group, and start the container servers in each of your zones with the name of the appropriate zone. Shards are placed so that shards for the same partition are placed in separate zones.
Zone rules
- P specifies the primary shard
- S specifies synchronous replica shards
- A specifies asynchronous replica shards.
- true (a shard cannot be placed in the same
zone as another shard from the same partition).
Remember: For the "true" case, you must have at least as many zones in the rule as you have shards using it. Doing so ensures that each shard can be in its own zone.
- false (shards from the same partition can be placed in the same zone.
For more information, see Example: Zone definitions in the deployment policy descriptor XML file.
Extended use cases
The following are various use cases for shard placement strategies:
Rolling upgrades
Consider a scenario in which you want to apply rolling upgrades to your physical servers, including maintenance that requires restarting your deployment. In this example, assume that you have a data grid spread across 20 physical servers, defined with one synchronous replica. You want to shut down 10 of the physical servers at a time for the maintenance.When you shut down groups of 10 physical servers, no partition has both its primary and replica shards on the servers you are shutting down. Otherwise, you lose the data from that partition.
The easiest solution is to define a third zone. Instead of two zones of 10 physical servers each, use three zones, two with seven physical servers, and one with six. Spreading the data across more zones allows for better failover for availability.
Rather than defining another zone, the other approach is to add a replica.
Upgrading WebSphere® eXtreme Scale
When you are upgrading WebSphere eXtreme Scale software in a rolling manner with data grids that contain live data, consider the following issues. The catalog service software version must be greater than or equal to the container server software versions. Upgrade all the catalog servers first with a rolling strategy. Read more about upgrading your deployment in the topicUpdating eXtreme Scale servers.
Changing data model
A related issue is how to change the data model or schema of objects that are stored in the data grid without causing downtime. It would be disruptive to change the data model by stopping the data grid and restarting with the updated data model classes in the container server classpath, and reloading the data grid. An alternative would be to start a new data grid with the new schema, copy the data from the old data grid to the new data grid, then shut down the old data grid.
- Use XML as the value
- Use a blob made with Google protobuf
- Use JavaScript Object Notation (JSON)
Virtualization
Cloud computing and virtualization are popular emerging technologies. By default, two shards for the same partition are never placed on the same IP address as described in Policy 1. When you are deploying on virtual images, such as VMware, many server instances, each with a unique IP address, can be run on the same physical server. To ensure that replicas can only be placed on separate physical servers, you can use zones to solve the problem. Group your physical servers into zones, and use zone placement rules to keep primary and replica shards in separate zones.
Zones for wide-area networks
You might want to deploy a single data grid over multiple buildings or data centers with slower network connections. Slower network connections lead to lower bandwidth and higher latency connections. The possibility of network partitions also increases in this mode due to network congestion and other factors.
To deal with these risks, the catalog service organizes container servers into core groups that exchange heartbeats to detect container server failure. These core groups do not span zones. A leader within each core group pushes membership information to the catalog service. The catalog service verifies any reported failures before responding to membership information by heartbeating the container server in question. If the catalog service sees a false failure detection, the catalog service takes no action. The core group partition heals quickly. The catalog service also heartbeats core group leaders periodically at a slow rate to handle the case of core group isolation.