With WebSphere® eXtreme Scale,
you can create many installation topologies that include stand-alone
servers, WebSphere Application Server, or both.
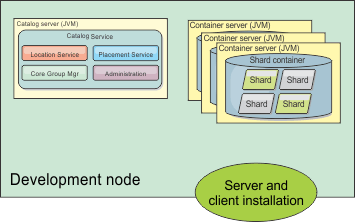
Development node
The simplest installation
scenario is creating a development node. In this scenario, you install
the client and server installation of WebSphere eXtreme Scale one time on the node
where you want to develop your application. Figure 1. Development
node
After you complete the installation on your development node,
you can configure your development environment and begin writing your
applications.
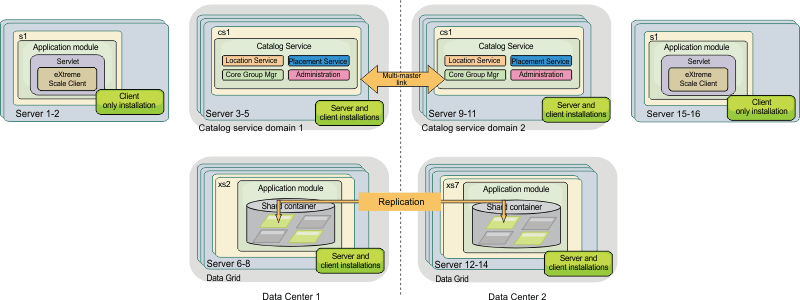
Stand-alone topology
A stand-alone topology
consists of servers that are not running on WebSphere Application Server. You can create many
different stand-alone topologies, but the following topology is included
as an example. In this topology, two data centers are present. In
each data center, WebSphere eXtreme Scale full
installations (client and server) and client-only installations are
installed on the physical servers. The client-only installations are
on the nodes that are running the web applications that are using
the data grid. These nodes do not run any catalog or container servers,
so the server installation is not required. A multi-master link connects
the two catalog service domains in the configuration. The multi-master
link enables replication between the shards in the container servers
in the different data centers. Figure 2. Stand-alone topology with
two data centers
Advantages to using a stand-alone topology:
Flexible
integration options that can be embedded with vendor
frameworks and libraries.
Smaller footprint than a WebSphere Application Server topology.
Fewer
licensing requirements than a WebSphere Application Server topology.
Expanded Java Runtime Environment (JRE) options.
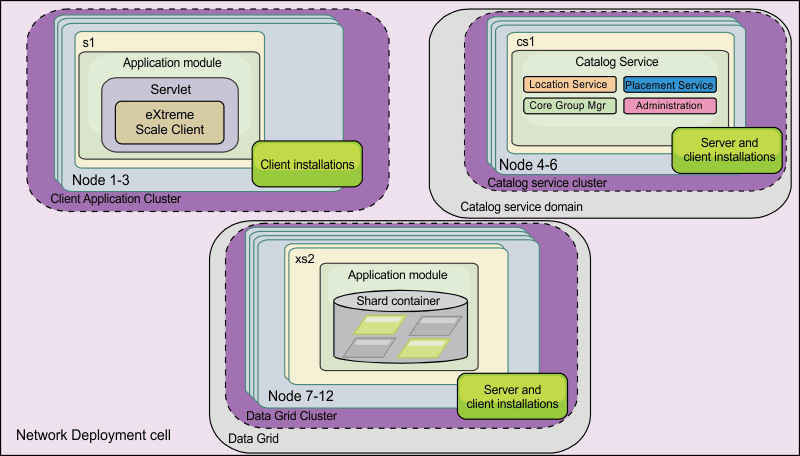
WebSphere Application Server topology
You
can also create an installation that runs entirely in a WebSphere Application Server cell. The clients, catalog
servers, and container servers each have an associated cluster. The
nodes that run the application have the client-only installation.
The other nodes have the client and server installation.Figure 3. WebSphere Application Server topology example
Advantages of using a WebSphere Application Server topology.
Centralized
and consistent administration and configuration.
Integration with
the following WebSphere Application Server components:
OpenJPA L2
cache, dynamic cache, and HTTP session persistence.
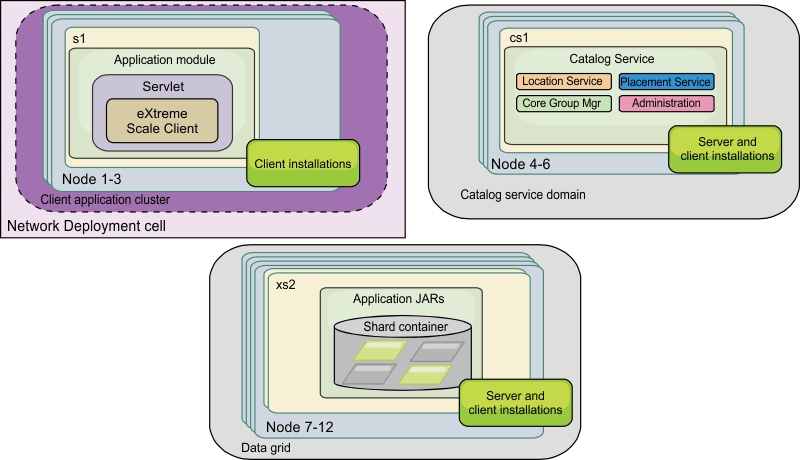
Mixed topology
You can create a mixed topology
that contains both WebSphere Application Server and
stand-alone servers. In the following example, the client applications
are running in the WebSphere Application Server cell,
while the catalog servers and container servers are running in stand-alone
mode.Figure 4. Mixed topology example
Virtual image topology
WebSphere eXtreme Scale is capable of being used effectively in a
virtual product environment, such as VMWare. However it is critical to keep in mind that eXtreme Scale is a stateful distributed system and therefore
certain criteria must be maintained for effective usage:
eXtreme Scale is intended to run with a stable network
without significant interruptions and has built-in mechanisms to ensure high availability and
recover from outages. However, these recovery mechanisms are not without risk of brief service
interruption or potential data loss. Also, outages that affect a significant percentage of the
eXtreme Scale JVMs in the data grid can result in the
resources within the remaining data grid servers being overrun, compromising the entire data
grid. Therefore, be careful to ensure that any utilities used by the virtual product in which
eXtreme Scale is installed does not dramatically affect
network connectivity.
Be sure to allocate enough CPU resource or memory. For example, a virtual machine with 16
GB of physical memory should not be configured with 4-4 GB eXtreme Scale JVMs, since this does not take into account
overhead. Similarly, a host machine with 16 GB of physical memory should not be configured
with 4-4 GB guest virtual machines.
eXtreme Scale is designed as a distributed and balanced
data grid product. When the product is configured and sized appropriately there is an
expectation that sufficient resources will exist during run time. When the resources become
unavailable, the system begins processing failover operations to recover state. Depending on
the type and duration of the loss of resources, the system might take dramatic action to
attempt to recover because the loss of those resources can indicate significant losses of
system infrastructure.
The distributed nature of the eXtreme Scale data grid
means that specific data and underlying infrastructure might be moved from JVM to JVM as
additional resources are configured or the infrastructure accounts for failover work.
Therefore, utilities used by the virtual product (for example, VMWare Snapshot) that record
memory and state within a virtual machine as a backup mechanism, and do not take into account
the distributed stateful nature of the system, must be avoided.