Catalog service
The catalog service controls placement of shards and discovers and monitors the health of container servers in the data grid. The catalog service hosts logic that should be idle and has little influence on scalability. It is built to service hundreds of container servers that become available simultaneously, and run services to manage the container servers.
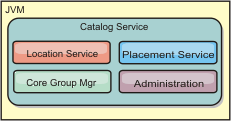
- Location service
- The location service runs on the data grid members to provide locality to clients and container servers. Container servers register with the location service to register the hosted applications. Clients can then use the location service to search for container servers to host applications.
- Placement service
- The catalog service manages the placement of shards across available container servers. The placement service is responsible for maintaining balance across physical resources and allocating individual shards to their host container server. The placement service runs as a One of N elected service in the cluster and in the data grid. This means that exactly one instance of the placement service is running. If an instance fails, another process is elected and takes over. To provide redundancy, the state of the catalog service is replicated across all the servers that are hosting the catalog service.
- Core group manager
- The core group manages peer grouping for availability monitoring, organizes container servers
into small groups of servers, and automatically federates the groups of servers.
The catalog service uses the high availability manager (HA manager) to group processes together for availability monitoring. Each grouping of the processes is a core group. The core group manager dynamically groups the processes together. These processes are kept small to allow for scalability. Each core group elects a leader that is responsible for sending heartbeat messages to the core group manager. These messages detect if an individual member failed or is still available. The heartbeat mechanism is also used to detect if all the members of a group failed, which causes the communication with the leader to fail.
The core group manager is responsible for organizing containers into small groups of servers that are loosely federated to make a data grid. When a container server first contacts the catalog service, it waits to be assigned to either a new or existing group. An eXtreme Scale deployment consists of many such groups, and this grouping is a key scalability enabler. Each group consists of Java™ virtual machines. An elected leader uses the heartbeat mechanism to monitor the availability of the other groups. The leader relays availability information to the catalog service to allow for failure reaction by reallocation and route forwarding.
Tip:When XIO is enabled, the XIO transport maintains persistent socket connections between the catalogs and the containers, over and above what the high availability (HA) manager and Distribution and Consistency Services core groups provided. WebSphere® eXtreme Scale is now leveraging these persistent connections directly for failure detection when a socket connection is lost, as a replacement for the core groups detecting lost socket connections. Then, the container server, which is the core group leader, reports the lost connections to the primary catalog.
Therefore, while you still will see the HA manager and DCS stack coming up in containers, and core groups formed, they are ignored. Subsequent updates to WebSphere eXtreme Scale will fully remove the HA manager and DCS stack from the containers. Core groups, HA manager and DCS are still leveraged as described here for the catalog cluster.
These changes also allow the catalogs to leverage client reports of failures as an impetus for seeing whether containers are still active, which is determined via an explicit RPC call. Containers also periodically check in with one of the catalog servers (not necessarily the primary server) to help assure the catalog that the container is not isolated by a brownout. For now, when you enable XIO, core groups are still set up and formed. However, core groups are ignored during failure detection with the containers. Core groups are still used for catalog servers. To enable this transport mechanism, see Configuring IBM eXtremeIO (XIO)
- Administration
- The catalog service is also the logical entry point for system administration. The catalog service hosts a Managed Bean (MBean) and provides Java Management Extensions (JMX) URLs for any of the servers that the catalog service is managing.
For high availability, configure a catalog service domain. A catalog service domain consists of multiple Java virtual machines, including a main JVM and a number of backup Java virtual machines. For more information, see High availability catalog service.