 z/OS DFSMSdfp Storage Administration
z/OS DFSMSdfp Storage Administration
z/OS DFSMSdfp Storage Administration
z/OS DFSMSdfp Storage Administration
|
Previous topic |
Next topic |
Contents |
Contact z/OS |
Library |
PDF
Data classification methodology z/OS DFSMSdfp Storage Administration SC23-6860-01 |
|
|
Data classification is a methodology for SMS implementation that translates high-level requirements into data classes, storage classes, and management classes and identifies the decision points needed in the ACS routines. Use the data classification technique to build a tree diagram where each major branch (data type) is a collection of data to be migrated to SMS management, each in a separate phase of the implementation process. Figure 1 shows six data types to be managed by SMS. Figure 1. Typical Data Types
 After the initial tree diagram has been built, each data type is split further until no more downward splits need to be made. Further splits result in the creation of data subtypes. Each data subtype is a distinct set of data sets requiring a unique set of assigned classes. Figure 2 is an example of how a TSO data type can be split into different data subtypes. Figure 2. TSO Data Type with Data Subtypes
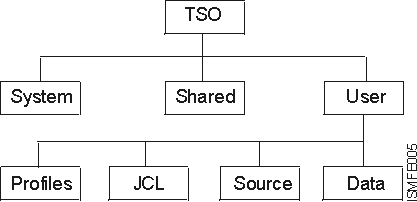 NaviQuest is designed to support testing of data subtypes determined during data classification. All data sets associated with a single data subtype will have the same expected ACS results. NaviQuest testing at the subtype level lets you manage all test cases for a data subtype and validate the results for that subtype. 


|
 Copyright IBM Corporation 1990, 2014 Copyright IBM Corporation 1990, 2014 |