Before setting up a geographically dispersed DB2® pureScale® cluster (GDPC), a number of conditions must be met.
The connection between sites is a key piece of infrastructure in a geographically dispersed DB2 pureScale cluster (GDPC). A DB2 pureScale environment uses low-latency, high-bandwidth RDMA messaging between members and cluster facilities (CFs), and in a GDPC configuration, many such messages traverse the link from one site to the other.
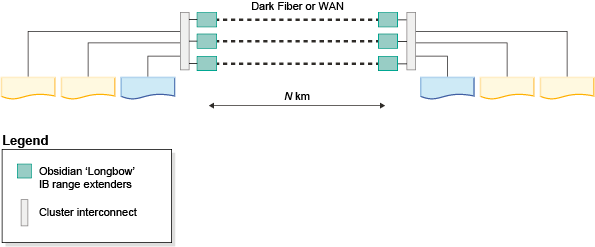
In the case of an InfiniBand high speed interconnect, Longbow InfiniBand extender technology from Obsidian Strategies provides a transparent connection between the two portions of the high speed interconnect network that are located at the two sites, and maintains the ability to execute RDMA operations across GDPC, even at relatively large distances. Used in pairs at either end of the site-to-site interconnect, the extenders accept a high speed interconnect connection to a site-local high speed interconnect switch, and through it, connect to the members and CF. The extender translates high speed interconnect traffic to and from packets that are sent and received over the site-to-site interconnect (either a ‘dark fiber’ or 10 GB WAN connection).
The extenders themselves add only a very small amount of extra latency to the message protocol. The bulk of the extra site-to-site message latency, when compared to a single-site DB2 pureScale cluster, arises from the simple fact of distance: each kilometer of transmission in glass fiber adds an additional 5 microseconds of delay. So for example, a 10km distance between sites would add (10km x 5 microseconds/km) x 2 for round trip = 100 microseconds of extra latency for most types of messages. In practical terms, workloads that have higher ratios of read activity compared to write activity tend to trigger fewer message exchanges with the CF, and so would be less impacted by additional site-to-site latency.
Current Longbow IB extenders operate at the 4X width Single Data Rate (SDR) or 10 GB data rate between end points (subject to the capacity of the dark fiber / WAN link.) If redundancy or additional cross-site capacity is required, Longbow units can be grouped in multiple pairs between sites (see Figure 1). As well, different Longbow models provide different features which can be useful in certain circumstances, such as encryption in the E-100 and X-100 models, which might be important if the site-to-site interconnect is shared or public and encryption is required by security policies. All current Longbow models are supported with GDPC. Particular configurations, such as the choice of model, use of WAN or fiber, or choice of transceiver wavelength, and other characteristics, are not specified here, and should be selected based on the physical infrastructure to be used, and IT policies in effect. For more information about Longbow IB extenders, contact Obsidian Research. (http://www.obsidianresearch.com/)
A GDPC is composed of two main sites A and B, with each having an equal number of members and CFs. For example, if site A has two members and one CF, site B must also have two members and one CF. It is a best practice that each main site have the same number of physical machines as well. For example, you do not want to have one machine with four LPARs on one site and two machines with two LPARs each on the other site. One key clustering concept that must be considered is the concept of ‘quorum’. Quorum refers to the number of computer systems that must be online in the cluster in order for the cluster to remain operational. There are two types of quorum, operational quorum and configuration quorum. Operational quorum is needed for software services on the cluster to operate. Configuration quorum is needed to apply configuration changes to a cluster, such as adding a new computer system to the cluster. Configuration quorum requires a strict majority of online computer systems in the cluster, so for example in a cluster that comprises 6 computer systems, at least 4 of those computer systems must be online to perform any cluster configuration updates.
In a non-GDPC environment, operational quorum is typically achieved through the use of a tiebreaker disk. In the event of having only half the computer systems in a cluster online (or a network partition where each half is simultaneously online with no network connectivity to the other half), the disk “tiebreaker” device can be acquired by one half of the cluster. This allows it to achieve operational quorum and run software services (that is, the DB2 pureScale instance) on that winning half of the cluster. In the event of a network partition, the “losing” half would consequently be fenced from the cluster, preventing it from accessing any shared instance data. The requirement for a disk tiebreaker, however, is that the single tiebreaker disk must be accessible from each computer system in the cluster. In a GDPC environment, this disk must be physically located at one of the two sites, which in the event of a complete network partition between the two sites, would prevent the other site from being able to achieve operational quorum. In the case of clusters with an odd number of nodes, a majority of online nodes is needed for operational quorum. However, in the case where the cluster has an even number of nodes, with an even split of online nodes, a tiebreaker disk decides which subcluster gains operational quorum. In cases where one half of the cluster is down, the online subcluster claims the tiebreaker and gain quorum.
GDPC environments rely on strict majority quorum semantics, where one additional tiebreaker host T is required to maintain quorum in the event of site failure. This tiebreaker host T must be the same architecture type as the machines at the two main sites. For example, it must run the same operating system, although it does not require the same hardware model. A best practice is to also be running the same OS level across all computer systems in the cluster. This additional host does not run any DB2 members or CFs.
A two-site configuration where the tiebreaker host is physically located at one of the two main sites would not be able to achieve either operational or configuration quorum in the event of a site failure at the site containing host T. As such, it is a best practice for continuous availability to use a three-site configuration where the tiebreaker host T is physically located at a separate third site (site C), in order to achieve continuous availability in the event of a failure affecting either of the data processing sites (site A or site B), as majority quorum can be established between site C and the surviving data processing site. In three-site configurations, all three sites can be on different IP subnets as long as each computer system from each site is able to “ping” each other computer system in the cluster. Site C also does not require high speed interconnect connectivity; only sites A and B require high speed interconnect connectivity, with a single high speed interconnect subnet spanning both sites.
To aid in problem determination, it is a best practice to have all computer systems at all sites configure their system clocks to the same timezone.
GDPC requires that both sites A and B have direct access to each others’ disks. To this end, a number of options are available for extending a SAN across the data centers. Options include transmitting Fibre Channel (FC) traffic directly over ATM or IP networks, or using iSCSI to transmit SCSI commands over IP. Dark fiber is likely to be the fastest but also the most expensive option.
A typical cluster that is not in a GDPC uses GPFS™ software in a non-replicated configuration. In such a case, all GPFS disk activity for a given file system goes to a single GPFS failure group. When disks are not replicated, a disk failure can leave some of the file system data inaccessible. For a GDPC, however, GPFS replication is used between sites A & B in order to ensure that an entire copy of the data is available at the surviving site in the event of a total site failure.
GDPC configuration leverages GPFS replication, by configuring each site to maintain an entire copy of the file system data in its own failure group. As long as quorum is maintained in the cluster, in the event of a site failure (one of the failure groups are lost or inaccessible), the other site can continue with read/write access to the file system.
Tiebreaker host T requires a small disk or partition for each replicated GPFS file system to be used as a file system quorum disk. The amount of storage for each disk or partition is approximately 50 MB, and these disks or partitions only need to be accessible by host T, and are only used to store filesystem descriptors. I/O activity to disks or partitions that are used to store only filesystem descriptors is very low. Using a full physical volume for this purpose is wasteful and not necessarily practical; configuring a small volume is sufficient for this case. On AIX operating systems, you can also use logical volumes as the device type.
The introduction of significant distances between cluster members at different sites increases message latency by an amount of about 5 microseconds per kilometer of glass fiber. In some cases, the amount can be higher, if the connection includes signal repeaters, or is shared with other applications.
Besides distance, the performance overhead experienced by a GDPC configuration also depends on the workloads in use. The greater the portion of write activity (INSERT, UPDATE, DELETE) in the workload, the more messages need to be sent from members to the CFs, and the more disk writes (especially to the transaction logs) need to be made. This increase in disk writes typically leads to higher overhead at a given distance. Conversely, a greater portion of read (SELECT) activity means fewer messages and fewer disk writes, and reduced overhead.
A DB2 pureScale environment is designed to have minimal downtime if a host fails due to hardware or software faults. In the event of a hardware failure, a system must be ‘I/O fenced’ to prevent it from corrupting the data. After a host is I/O fenced, it can no longer access the storage device, and any I/O attempt is blocked. A key piece of technology to minimize downtime is SCSI-3 Persistent Reserve (PR).
If SCSI-3 PR is not enabled, the GPFS disk lease expiry mechanism is used to fence failed systems. This typically results in a longer recovery time because of the need to wait for the lease to expire.