The geographically dispersed DB2® pureScale® cluster (GDPC) is a configuration that allows a DB2 pureScale cluster to be distributed, having members of a cluster at different sites.
The DB2 pureScale Feature provides outstanding database scalability, availability, and application transparency on AIX® and Linux platforms, building on the data sharing architecture of the gold standard, DB2 for z/OS® Parallel Sysplex®. However, any single-site system, even DB2 pureScale systems or the DB2 for z/OS Parallel Sysplex, can be vulnerable to external events that compromise an entire site such as an extensive power or communications outage.
Since disasters like power failures and fires might disable a single data center, many large IT organizations configure two sites, far enough apart to be on separate power grids. This configuration minimizes the risk of total outage, and allows business to carry on at one site, even if the other is impacted by a disaster. Like the Geographically Dispersed Parallel Sysplex™ configuration of DB2 for z/OS, the geographically dispersed DB2 pureScale cluster (GDPC) provides the scalability and application transparency of a regular single-site DB2 pureScale cluster, but in a cross-site configuration which enables ‘active/active’ system availability, even in the face of many types of disaster.
Active/active is critical because it means that during normal operation, the DB2 pureScale members at both sites are sharing the workload between them as usual, with workload balancing (WLB) maintaining an optimal level of activity on all members, both within and between sites. This means that the second site is not a standby site, waiting for something to go wrong. Instead, the second site is pulling its weight, returning value for investment even during day-to-day operation.
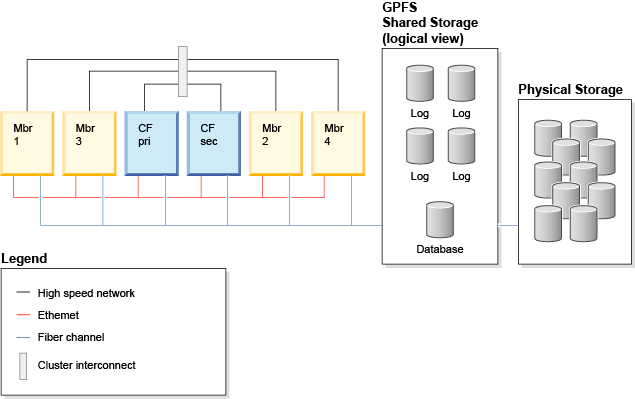
Figure 1 shows such a typical DB2 pureScale cluster configuration, with four members and two CFs. The DB2 pureScale Feature is a shared-data architecture, in which all members are operating on a single copy of the database, communicating with each other via the CF to synchronize activities and to ingest, modify and retrieve data as required by the application. Messages between the members and CF use the RDMA capability via the cluster interconnect, which provides extremely low communication latencies as well as very low CPU utilization per message. There are some very limited member-to-member communications in a DB2 pureScale cluster that utilize the Ethernet network.
Splitting a DB2 pureScale cluster in half across two sites A & B implies that half of the member systems will be physically located at site A and half at site B. For tie breaking and transparent failover in an event of a site failure, a third site is required. One CF should be placed at each of the two main sites as well, to avoid a single point of failure (SPOF). In order to maintain the best performance and scalability, use an RDMA-capable interconnect between sites, so that messages from a member at one site to the CF at the other site are as fast and inexpensive as possible. The spanning distance of an InfiniBand network is typically measured in tens or maybe hundreds of meters, however devices such as the Obsidian Longbow InfiniBand extender allow the reach of a high speed interconnect network to span greater distances, over wide-area networks or dedicated fiber optic links.
In addition to the dispersal of computing resources such as members and CFs, a disaster recovery (DR) cluster configuration also requires storage to be replicated across sites. Building on the standard DB2 pureScale cluster design, the GDPC configuration uses GPFS synchronous replication between sites to keep all disk write activity up-to-date across the cluster. This includes both table space writes and transaction log writes. At a high level, a GDPC cluster might look similar to either of the following figures:
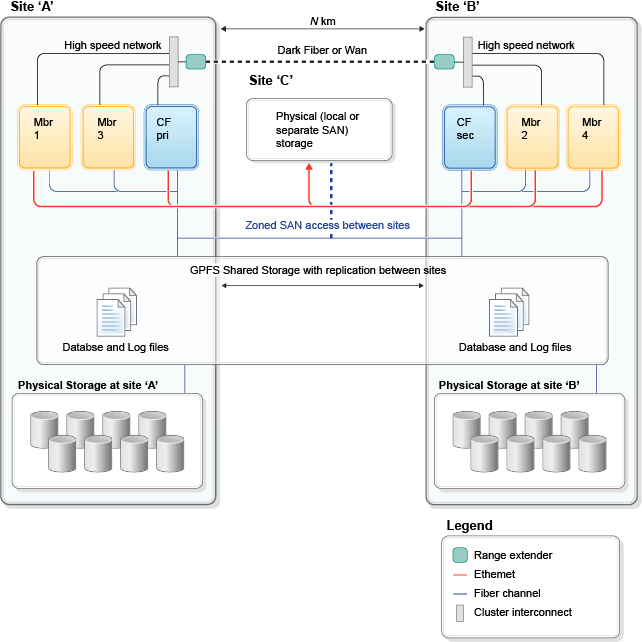
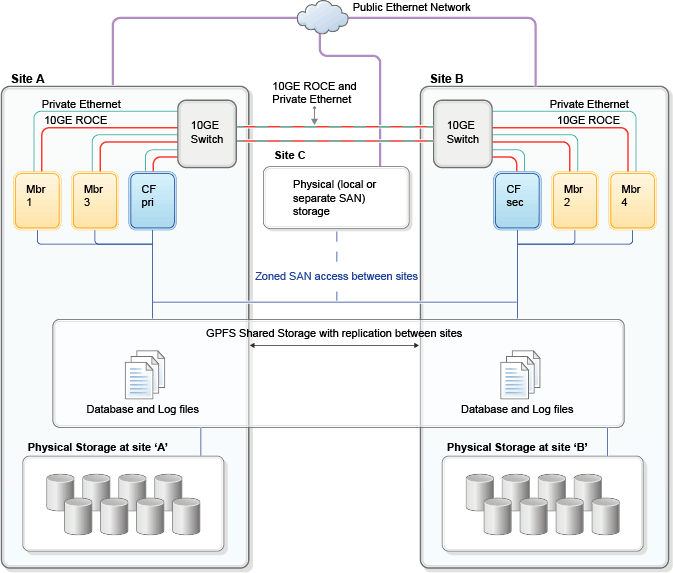
Client applications connecting to the DB2 pureScale cluster typically have workload balancing (WLB) enabled, which transparently routes work to the member with the most available capacity. WLB maintains optimal use of resources during normal operation, and also reroutes connections in case of member downtime (planned or unplanned), or even site failure. The client systems, often configured as application servers in a multi-tier environment, are often configured with redundancy across sites, providing fault tolerance at the upper layers as well. The Client Affinity feature can also be used with GDPC, if there is a desire to route specific client requests to members physically located at one of the sites.