The database manager uses a B+ tree structure for index storage.
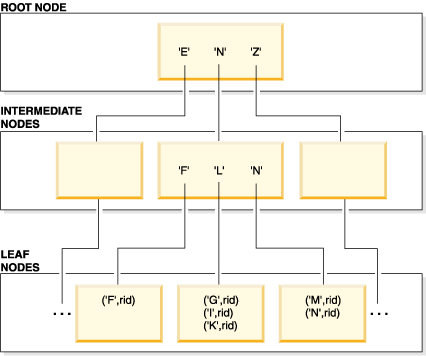
When it looks for a particular index key value, the index manager searches the index tree, starting at the root node. The root node contains one key for each (intermediate) node in the next level. The value of each of these keys is the largest existing key value for the corresponding node at the next level. For example, suppose that an index has three levels, as shown in the figure. To find a particular index key value, the index manager searches the root node for the first key value that is greater than or equal to the search key value. The root node key points to a specific intermediate node. The index manager follows this procedure through each intermediate node until it finds the leaf node that contains the index key that it needs.
Suppose that the key being looked for in Figure 1 is "I". The first key in the root node that is greater than or equal to "I" is "N", which points to the middle node at the next level. The first key in that intermediate node that is greater than or equal to "I" is "L", which, in turn, points to a specific leaf node on which the index key for "I" and its corresponding RID can be found. The RID identifies the corresponding row in the base table.
The leaf node level can also contain pointers to previous leaf nodes. These pointers enable the index manager to scan across leaf nodes in either direction to retrieve a range of values after it finds one value in the range. The ability to scan in either direction is possible only if the index was created with the ALLOW REVERSE SCANS option.
In the case of a multidimensional clustering (MDC) or insert time clustering (ITC) table, a block index is created automatically for each clustering dimension that you specify for the table. A composite block index is also created; this index contains a key part for each column that is involved in any dimension of the table. Such indexes contain pointers to block IDs (BIDs) instead of RIDs, and provide data-access improvements.
A one-byte ridFlag, stored for each RID on the leaf page of an index, is used to mark the RID as logically deleted, so that it can be physically removed later. After an update or delete operation commits, the keys that are marked as deleted can be removed. For each variable-length column in the index, two additional bytes store the actual length of the column value.