The use of shadow tables is supported for high availability disaster recovery (HADR) environments. However, there are a number of considerations for ensuring that latency-based routing is available in the event of a failover.
For an HADR setup, you install and configure InfoSphere® CDC on both a primary server and on the standby server. The InfoSphere CDC instance is active on the primary server and passive on the standby. HADR replicates data from the primary to the standby, including both source and shadow tables.
With InfoSphere CDC, there are two types of metadata that are used to synchronize the source and target tables. The operational metadata, which is information such as the instance signature and bookmarks, is stored in the database and is replicated by HADR to the standby servers. The configuration metadata, which is information such as subscriptions and mapped tables, is stored in the cdc-installation-dir, so it is not replicated by HADR. Therefore, after you implement shadow tables in an HADR environment, any configuration changes that are made to the shadow tables on the primary are not reflected on the standby server.
You propagate configuration metadata changes by employing a scheduled InfoSphere CDC metadata backup-and-copy over the standby servers by using the dmbackupmd command. You might also want to apply those changes to the standby servers immediately after they take place. For example, after any applying DDL statements that change the source row-organized table, the target shadow table, or both.
After a failover or role switch occurs and the HADR primary role has moved to a host where InfoSphere CDC was previously passive, you must manually start InfoSphere CDC on the new primary node. If the configuration metadata is not synchronized, you have to reapply any changes that occurred on the old primary server.
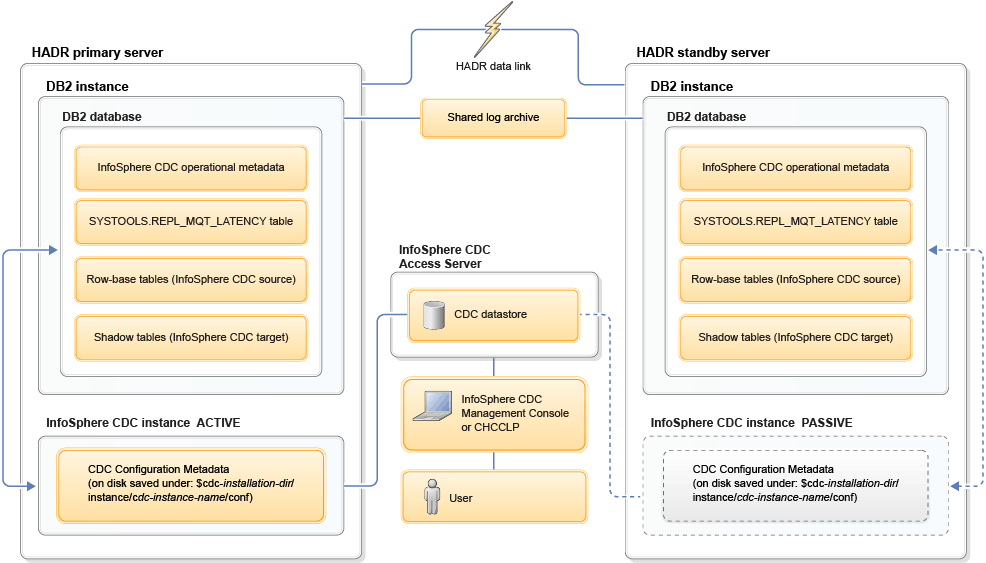
As part of this initial setup, you should configure a shared log archive. When using HADR with shadow tables, a shared archive is even more essential because you need to ensure that the InfoSphere CDC log capture process has access to all of the DB2 log files (including the ones that are not yet scraped) and the likelihood that InfoSphere CDC invokes log retrieve after failover is very high. For more information, see the following topic in the Related concepts section: "Log archiving configuration for DB2 high availability disaster recovery (HADR)".
It is also advisable to keep a change log of any DDL changes which affect the InfoSphere CDC configuration metadata. If there is an outage on the primary and you must fail over to the standby database, the configuration changes might not have been propagated to the standby yet, so you will need to manually redo those configuration changes. A change log makes reapplying those changes much easier.
If you already have a script, for example one that uses the MON_GET_TABLE table function to monitor if shadow tables are used, you can use it to identify which shadow table are not being routed to after the failover to the new primary completes. You can compare the InfoSphere CDC table mappings to that list of shadow tables which are consistently not having queries routed to them, and identify which mappings are missing.
select tabname, tabschema from syscat.tables where substr(property,23,1)='Y'