ITE application
SPL standard and specialized toolkits > com.ibm.streams.teda 1.0.2 > Application framework > Architecture > ITE application
The ITE applications perform all processing on the input files and optionally cooperate with the Lookup Manager application for data enrichment.
The processing consists of scanning and parsing input files; extracting, transforming, and enriching the data; removing duplicate records; writing records to output files; and collecting and storing file processing statistics. In opposition to the Lookup Manager application which is customized by adapting configuration and XML files, ITE applications are customized by providing or adapting SPL composite operators. Therefore it is important for you to roughly understand the structure of the ITE application, as outlined in the following diagram.
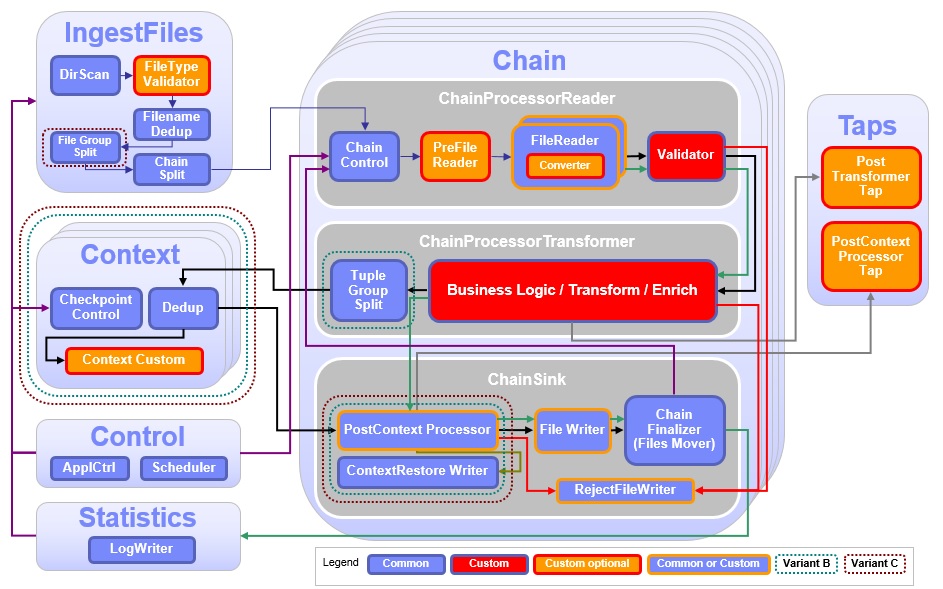
The colors of the functional blocks indicate which parts of the application can be customized in which ways. Common parts do not need or allow code changes. Instead their behavior is determined only by the settings in the configuration file. Custom parts are composites that only contain default tuple handling and need to be filled with application logic. They cannot be disabled using configuration parameters. Custom Optional parts can be disabled via configuration parameters or adapted if the functionality is needed by your application. For parts marked as Common or Custom a standard implementation exists that can be configured via parameters, however if there is a need you can replace these parts with your own implementation. For example you can use the three standard parsers in the FileReader, or you can implement your own parser and plug it into the File Reader composite.
Main functional components
Record processing in the ITE application is primarily performed within the following three components.
The Filename ingestion scans directories for input files and optionally validates and deduplicates the file names. It also handles the file name distribution to the Chains. Distributing filenames results in a load distribution, as there are multiple chains which process the input files in parallel.
The ChainProcessor consists of two parts. The ChainProcessorReader hosts the FileReader which parses the input file and extracts the records and the Validator which checks the records for logical errors according to the use case. If the reader or the validator detect errors in a record (structural or logical) the record will be marked as invalid or the containing file will be rejected and moved to a certain directory. This allows the user to manually inspect the rejected file, correct any errors and resubmit the file for processing. The ChainProcessorTransformer contains the business logic of your application. It applies business rules to the records and optionally enriches the records with enrichment data provided by the Lookup Manager application. Here you can integrate, for example, rules engines like ODM.
After transformation, the record is routed to the Context component. The Context contains the record deduplication and any custom logic you want to apply to groups of records. If your use case requires record correlations, for example aggregations, the CustomContext is the right place to implement them. Because records from multiple chains can be routed through the same CustomContext. Usage of the context component is optional. Finally the records are send to the ChainSink, which can apply additional custom logic and handles the storage of the records in output files.
Other components
The Control component handles the job startup and shutdown phases, initiates checkpointing and controls the chain processing. It exchanges job status information with the Lookup Manager. Chain control keeps track of the results of the processing, to ensure that output files are only generated if the input file was processed completely and without critical errors. It can pause and resume chain processing at file boundaries as needed. The control component also periodically initiates internal housekeeping logic, so called Cleanup phases, to remove expired data from parts of the application. For example the deduplication logic evicts expired data during the cleanup phase.
The Statistics component creates log entries for each processed files. It writes log files to a configurable statistics directory and creates and updates file processing summary metrics that can be used for system monitoring.
The Taps are optional components that receive merged output streams from all chains. They can be used to implement additional custom logic, for example, creating a file that receives data from all chains or sending events.
Parallelization
There is only one instance of the FileIngest, Control, Statistics and Tap components in an ITE application, whereas multiple instances of the Chain and Context components can be configured, to achieve parallelization. This allows the application to scale to large number of CPUs and hosts. You can also configure the relation between chains and contexts by forming Groups. The ITE application provides two mechanisms for grouping these components. See the chapter on variants for more details on grouping and parallelization options.
Related links:
- Reference > Toolkits > Specialized toolkits > com.ibm.streams.teda 1.0.2 > Developing applications > Customizing applications > Customizing the ITE application
- Variants
- ITE applications can be configured in different variants.
- Filename ingestion
- The filename ingestion component scans one or more directories for input files and feeds the chains with the file names to process.
- Chain processing
- All record related processing is located in the Chains.
- Checkpointing and Cleanup
- The ITE application implements a checkpointing mechanism to allow recovery after failures.