Variants
SPL standard and specialized toolkits > com.ibm.streams.teda 1.0.2 > Application framework > Architecture > ITE application > Variants
ITE applications can be configured in different variants. The variant determines how filenames and records are distributed to chains and if you can use record correlation functions across chains.
The variant of an ITE application is a predefined set of configuration parameter values. The Streams Studio wizard allows you to select one of three variants, and will configure your ITE application parameters accordingly. Understanding the variants is essential, because they put restrictions on the functionality that can be implemented in the application. The variant also affects the parallelization and the load distribution mechanism that is used within the application.
Concepts
The basic unit of parallelization in the ITE application is the Chain. Each chain processes only one input file at a given time. Once the processing of all records extracted from the input file has completed, the chain starts to process the next file. Using one chain only in the ITE application would limit the throughput of the application, and you would not be able to fully load machines with a large number of CPUs. Therefore you can configure the ITE application to deploy as many chains as needed to optimize throughput for a given target hardware. Internally the parallelization is done either using the Streams User Defined Parallelization (UDP) feature or using mixed mode processing to create parallelism during compile time. If you configure multiple chains, the File Ingestion component will distribute the filenames to the available chains.
With multiple chains, each chain processes only a subset of the input files. For use cases that require correlation of all records from all input files, this is not sufficient. Imagine you need to implement some aggregation function that counts the number of dropped calls for each subscriber. That could be implemented using an SPL map that stores a dropped calls counter as value and uses the subscriber identification as key. If you use only one chain this functionality could be implemented for example in the ChainProcessorTransformer as part of the business logic. If you have more than one chain that approach would not work anymore, because each chain only only has partial information about the number of dropped calls for each subscriber. To get the total number of dropped calls for a subscriber, you would need to do an additional aggregation over the maps maintained in each chain. To solve this problem the ITE application provides an additional component called Group or Context. The context processing is located after the Chain Processor but before the Chain Sink. It receives records from all parallel Chain Processors or from a subset of them and applies the correlation function to the data. After that the records are forwarded to the Chain sinks for storage processing. If you implement the Aggregator in this component, it will “see” all records and the aggregation would have the complete data. The built-in record deduplication is implemented in this component. You can place custom SPL code in the Context component to implement your own correlation functions. The number of contexts working in parallel and the routing of records through the context components can be configured.. The routing can be based either on the filename of the input file by applying a pattern matching on the filename (File Group Split), or based on the value of a configurable attribute in the record (Tuple Group Split). Below is a description of different variants.
Variant A
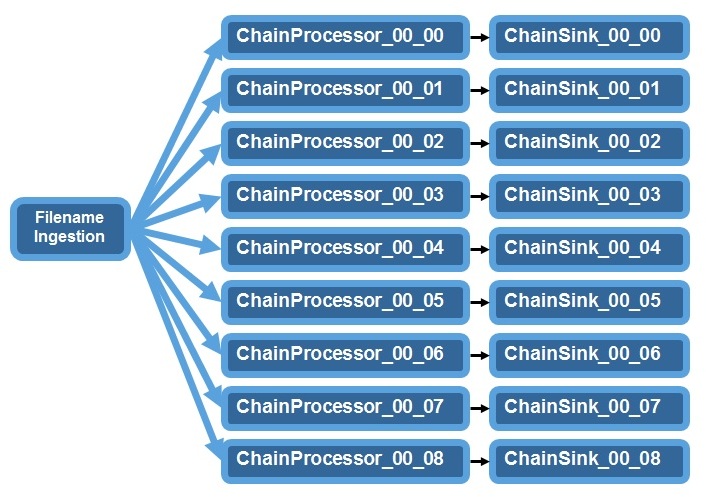
This is the simplest variant. It does not contain any groups. The Filename ingestion distributes filenames to all chains, by using, for example a round-robin mechanism. Use this variant if your use case does not require correlation of records across chains. In this variant you cannot enable the built-in Bloom filter for record deduplication.
Variant B
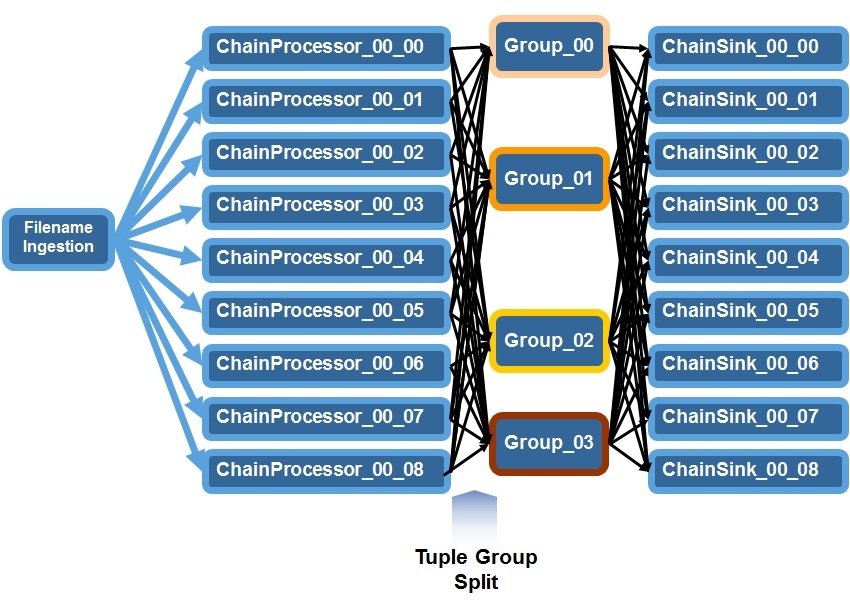
In this variant one or more groups are available. The filename distribution is the same as in variant A, each input file is processed by an arbitrary chain. After the Chain Processor extracts and transforms the records, they are routed to exactly one of the configured groups. Which group is chosen depends on the value of a configurable attribute in the record. This works similar to the standard Split operator from the Streams SPL toolkit. After the group processing is applied, the record is send to the Chain Sink that corresponds to the Chain Processor it was emitted from.
Use this variant to implement correlations that need to process all records from all parallel chains. Like, for example, aggregations on a per subscriber basis as described before. To improve throughput you can use multiple groups, each handling one partition of data. For example, you could configure 5 groups, each one handling a distinct range of subscribers, identified by the subscriber ID. In this variant you can use the built-in record deduplication.
Variant C
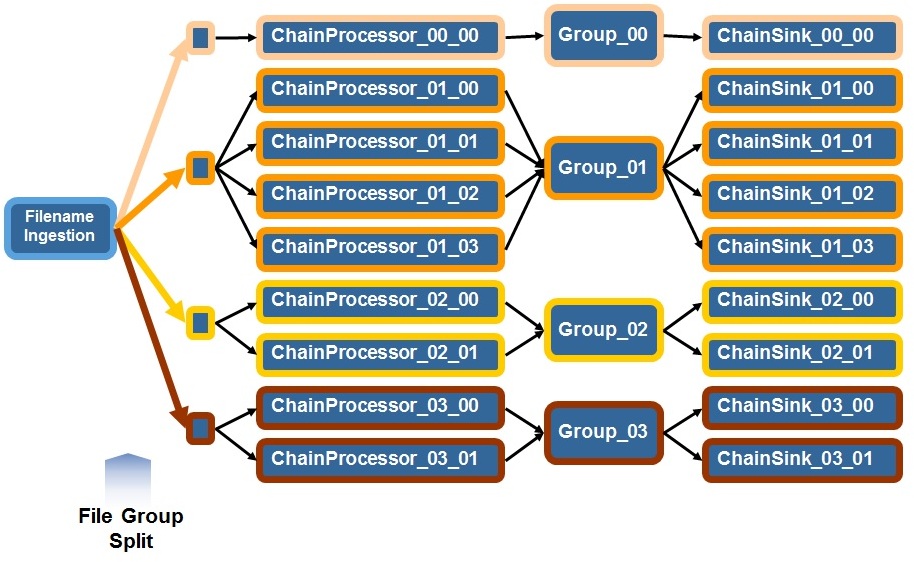
In this variant subsets of chains are associated with one group each. The group receives records from all chain processors associated with the group. You can configure the number of parallel chains for each group. The decision which chain processor processes a certain input file is made by the filename ingestion component in two steps. First the filename is matched against a list of identifiers to determine the group that should receive the file. Than the filename is distributed to the chains within the group like in variants A and B.
Use this variant if you want to apply correlations across subsets of chains. The subsets could represent geographical regions for example, with the filenames containing information about the region an input file is associated with. In this scenario the correlations would be applied for each geographical region independently. In this variant you can use the built-in Bloom filter.
Related links:
- Reference > Toolkits > Specialized toolkits > com.ibm.streams.teda 1.0.2 > Application framework > Architecture > ITE application > Filename ingestion > Filename distribution