Before you begin
- Each blueprint design server in the cluster must run the same version of IBM® UrbanCode™ Deploy.
- Install an IBM UrbanCode Deploy server and create a token that the blueprint design servers can use to access it.
- Set up a system to host the databases, shared files, and load balancer. These resources can be on the same system or on separate systems. If you have a cluster of servers or engines, you can use the same cluster resources or set up separate cluster resources for the blueprint design server cluster.
About this task
To set up blueprint design servers and engines in a clustered configuration, you install them on separate systems and connect them to the same database and network storage. You can install as many blueprint design servers and engines as you need. You can install a blueprint design server and an engine on each cluster node, or you can install blueprint design servers and engines on separate nodes.
You do not need to install the same number of blueprint design servers and engines. Most high-availability setups need more engines than blueprint design servers.
Then, you configure a load balancer to distribute the traffic to the blueprint design servers. Instead of accessing the blueprint design servers and engines directly, users access the load balancer URL. To the users, that URL appears to host a single instance of the blueprint design server or engine.
- One or more blueprint design server nodes
- One or more engine nodes
- A database for the engine nodes and the RabbitMQ service
- A database for the blueprint design server nodes
- A shared file system for the blueprint design server nodes
- A load balancer
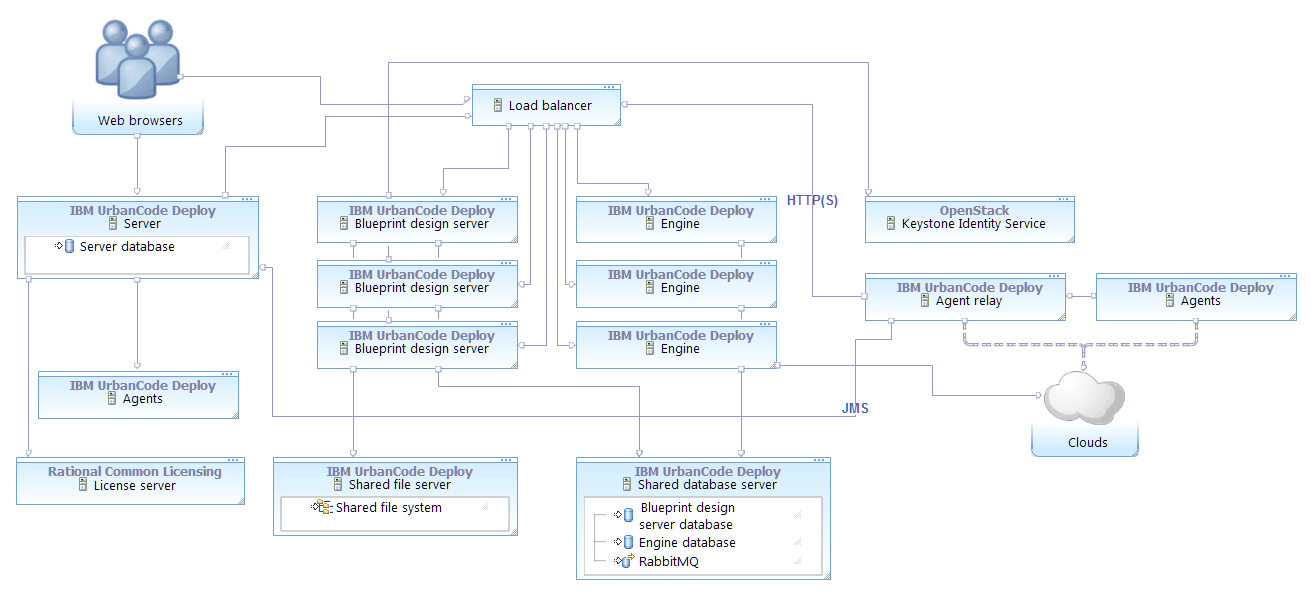
You can set up a cluster of blueprint design servers and engines independently of the IBM UrbanCode Deploy server. You do not necessarily have to have a cluster of IBM UrbanCode Deploy servers.