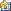This section gives examples of input and output data from a Column Import stage to give you a better idea of how the stage works.
| Column name | Key | SQL type |
|---|---|---|
| keycol | Yes | Char |
| col_to_import | Binary |
These are the rows from the input data set:
| Column name | Key | SQL type |
|---|---|---|
| keycol | Yes | Char |
| col1 | Integer | |
| col2 | Integer | |
| col3 | Integer | |
| col4 | Integer |
You have to give InfoSphere® DataStage® information about how to treat the imported data to split it into the required columns. This is done on the Output page Format Tab. For this example, you specify a data format of binary to ensure that the contents of col_to_import are interpreted as binary integers, and that the data has a field delimiter of none
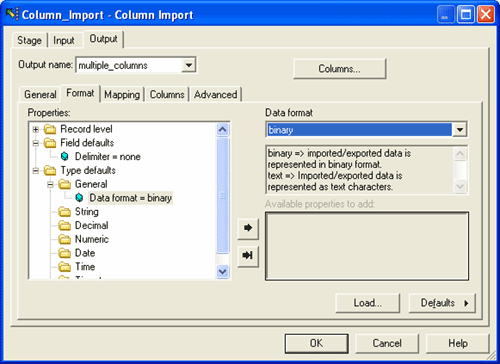
The output data set will be:
| col1 | col2 | col3 | col4 | key |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | a |
| 16843009 | 16843009 | 16843009 | 16843009 | b |
| 33686018 | 33686018 | 33686018 | 33686018 | c |
| 50529027 | 50529027 | 50529027 | 50529027 | d |
| 67372036 | 67372036 | 67372036 | 67372036 | e |
| 84215045 | 84215045 | 84215045 | 84215045 | f |
| 101058054 | 101058054 | 101058054 | 101058054 | g |
| 117901063 | 117901063 | 117901063 | 117901063 | h |
| 134744072 | 134744072 | 134744072 | 134744072 | i |
| 151587081 | 151587081 | 151587081 | 151587081 | j |
 This topic is also in the IBM InfoSphere DataStage and QualityStage Parallel Job Developer's Guide.
This topic is also in the IBM InfoSphere DataStage and QualityStage Parallel Job Developer's Guide.