 IBM InfoSphere Information Server
IBM InfoSphere Information Server
Scenario D: Clustered metadata repository tier and services tier configuration
Scenario D is a configuration that includes IBM® WebSphere® Application Server clustering and IBM DB2® clustering for high availability.
A large company uses both IBM WebSphere Application Server Network Deployment (ND) and DB2 for other applications. They recently purchased IBM InfoSphere® Information Server. They plan to use the full suite of components for future data integration projects.
The company has existing WebSphere Application Server and IBM DB2 installations. They are each managed within different support groups within the company IT department. Each group understands how to provide high availability solutions for the component under their supervision.
The large number of concurrent users requires a clustered WebSphere Application Server topology that permits almost no downtime. This topology also allows for future expansion to accommodate additional capacity. The WebSphere Application Server group plans to create a WebSphere Application Server cluster for InfoSphere Information Server. The DB2 group will provide clustering of the metadata repository database and IBM InfoSphere Information Analyzer database to minimize downtime.
The engine tier will be configured in an active-passive server cluster topology. The cluster management software will be IBM Tivoli® System Automation for Multiplatforms. To increase processing throughput, the passive node will be used as a parallel engine node while the primary node is active.
They are using UNIX computers for the servers and Microsoft Windows workstations for the clients.
The following diagram illustrates the configuration that they will build.

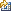 Last updated: 2017-03-31
Last updated: 2017-03-31