Schema format
A schema contains a record (or row) definition. This describes each column (or field) that will be encountered within the record, giving column name and data type.
The following is an example record schema:
record (
name:string[255];
address:nullable string[255];
value1:int32;
value2:int32;
date:date)
(The line breaks are there for ease of
reading, you would omit these if you were defining a partial schema,
for example record(name:string[255];value1:int32;date:date) is
a valid schema.)
The format of each line describing a column is:
column_name:[nullability]datatype;
- column_name. This is the name that identifies the column. Names must start with a letter or an underscore (_), and can contain only alphanumeric or underscore characters. The name is not case sensitive. The name can be of any length.
- nullability. You can optionally specify whether
a column is allowed to contain a null value, or whether this would
be viewed as invalid. If the column can be null, insert the word 'nullable'.
By default columns are not nullable.
You can also include 'nullable' at record level to specify that all columns are nullable, then override the setting for individual columns by specifying `not nullable'. For example:
record nullable ( name:not nullable string[255]; value1:int32; date:date) - datatype. This is the data type of the column. This uses the internal data types, see Data Types, not the SQL data types as used on Columns tabs in stage editors.
You can include comments in schema definition files. A comment is started by a double slash //, and ended by a newline.
You can specify a default value to pass if the source is NULL:
{null_field='[value]'}
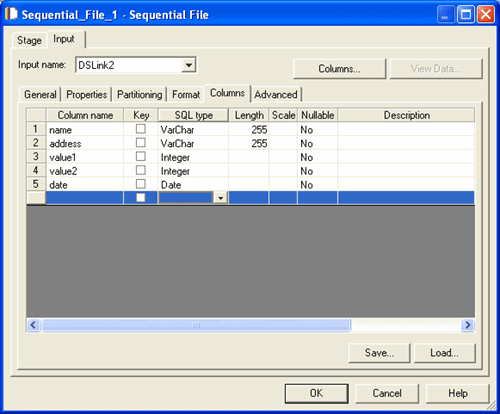
The example schema corresponds to the following table definition as specified on a Columns tab of a stage editor:
The following sections give special consideration for representing various data types in a schema file.