You can use ICETOOL's SELECT operator to create an output data set with records selected according to how many times different ON field values occur, sorted by those ON field values. As with the OCCUR operator, values that occur only once are called non-duplicate values, and values that occur more than once are called duplicate values.
You can use up to 10 ON fields; all of the ON field values are used for sorting and counting occurrences. For example, if you use ON(1,4,CH), 'ABCD+01' and 'ABCD-01' are sorted in that order (by 1,4,CH,A) and counted two occurrences of ('ABCD'). However, if you use ON(1,4,CH) and ON(5,3,FS), 'ABCD-01' is sorted before 'ABCD+01' (by 1,4,CH,A and 5,3,FS,A) and counted as one occurrence of 'ABCD-01' and one occurrence of 'ABCD+01'.
- FIRST - keep only the first record for each value (that is, records with non-duplicate values, and the first record for duplicate values)
- FIRST(n) - keep only the first n records for each value (that is, records with non-duplicate values, and the first n records for duplicate values)
- LAST - keep only the last record for each value (that is, records with non-duplicate values, and the last record for duplicate values)
- FIRSTDUP - only keep the first record for duplicate values
- FIRSTDUP(n) - only keep the first n records for duplicate values
- LASTDUP - only keep the last record for duplicate values
- ALLDUPS - only keep records with duplicate values
- NODUPS - only keep records with non-duplicate values
- EQUAL(n) - only keep records with values that occur n times
- HIGHER(n) - only keep records with values that occur more than n times
- LOWER(n) - only keep records with values that occur less than n times
The selected records are written to the output data set identified by the TO operand. If appropriate, you can use the DISCARD operand with any of the other operands shown previously to save the records that are not selected in a separate output data set identified by the DISCARD operand. You can create just the TO data set, just the DISCARD data set, or both.
You can use a USING data set to specify DFSORT INCLUDE, OMIT, INREC, and OUTFIL statements for your SELECT operation. INCLUDE or OMIT and INREC statement processing is performed before SELECT processing. OUTFIL statement processing is performed after SELECT processing.
To create an output data set containing records for publishers
with more than four different books in use, write the following SELECT
statement: 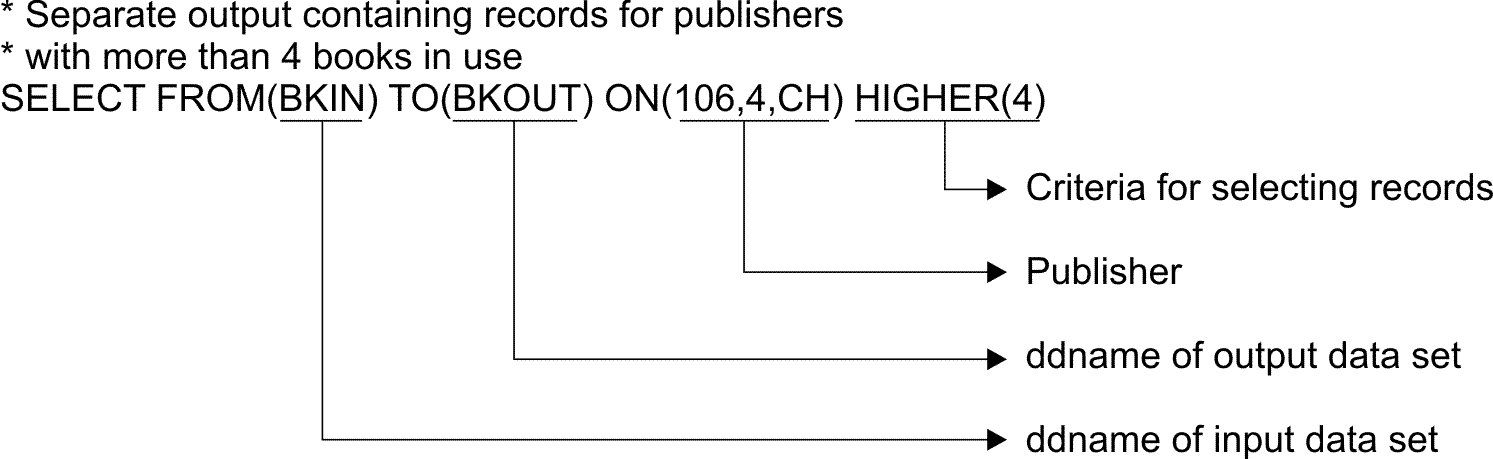
BKIN is the ddname for the sample bookstore data set. BKOUT is the ddname of the output data set that will contain the records for each publisher field value that occurs more than 4 times (all of the records for COR and VALD in this case).
Write a DD statement for the A123456.BOOKS1 data sets and place it at the end of the job:
//BKOUT DD DSN=A123456.BOOKS1,DISP=(NEW,CATLG,DELETE),
// SPACE=(CYL,(3,3)),UNIT=3390| Book Title | Publisher |
|---|---|
1 75 |
106 109 |
LIVING WELL ON A SMALL BUDGET |
COR |
To create
separate output data sets containing records with only
the course name and author's last name, both for courses that use
more than one book, and for courses that use only one book, write
the following SELECT statement: 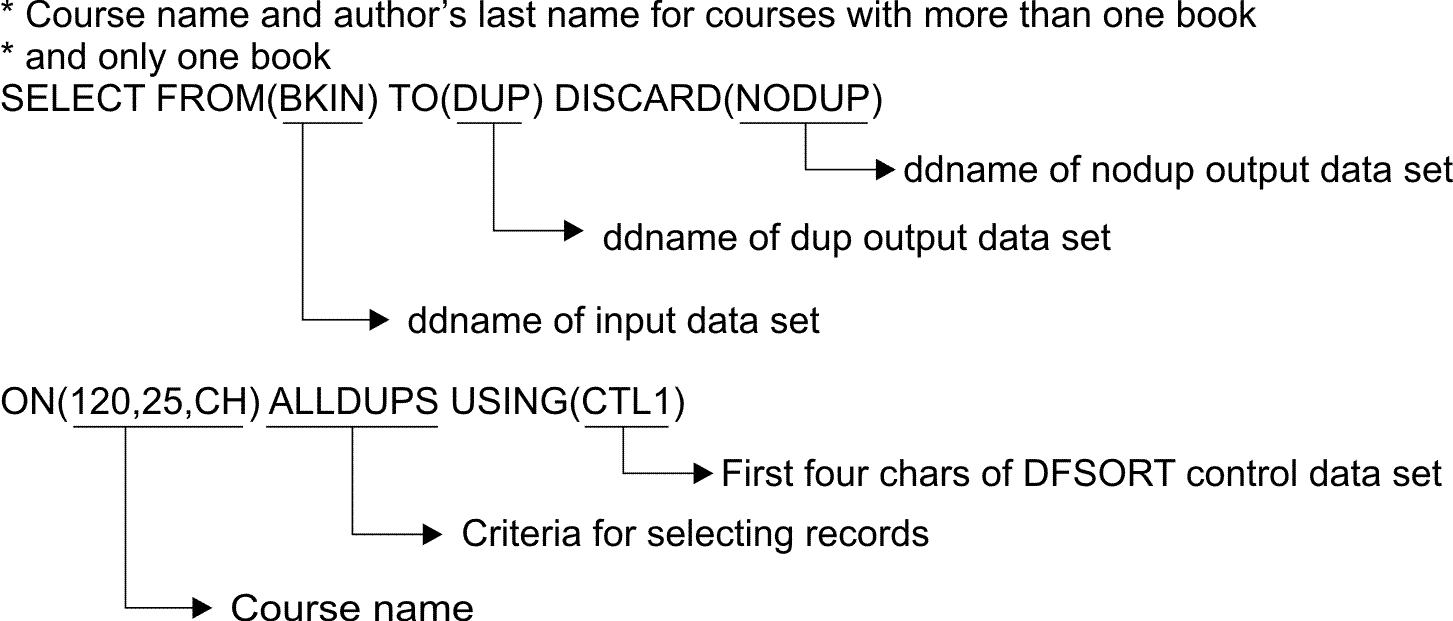
BKIN is the ddname for the sample bookstore data set. DUP is the ddname of the output data set to contain the records for courses with more than one book. NODUP is the ddname of the output data set to contain the records for courses with only one book.
//SEL2 JOB A492,PROGRAMMER
//EXTRACT EXEC PGM=ICETOOL
//TOOLMSG DD SYSOUT=*
//DFSMSG DD SYSOUT=*
//BKIN DD DSN=A123456.SORT.SAMPIN,DISP=SHR
//TOOLIN DD *
* Course name and author's last name for courses with more than one book
* and only one book
SELECT FROM(BKIN) TO(DUP) DISCARD(NODUP) -
ON(120,25,CH) ALLDUPS USING(CTL1)
/*
//CTL1CNTL DD *
OMIT COND=(120,25,CH,EQ,C' ')
OUTFIL FNAMES=DUP,OUTREC=(120,25,2X,145,15)
OUTFIL FNAMES=NODUP,OUTREC=(120,25,2X,145,15)
/*
//DUP DD SYSOUT=*
//NODUP DD SYSOUT=*The OMIT statement removes records with a blank course name before SELECT processing. The OUTFIL statement for DUP reformats the selected records for courses with more than one book to have just the course name and author's last name. The OUTFIL statement for NODUP reformats the selected records for courses with only one book to have just the course name and author's last name.
INTRO TO COMPUTERS CHATTERJEE
INTRO TO COMPUTERS CHATTERJEE
INTRO TO COMPUTERS CHATTERJEE
MODERN POETRY FRIEDMAN
MODERN POETRY FRIEDMAN
WORLD HISTORY GOODGOLD
WORLD HISTORY WILLERTONADVANCED MARKETING LORCH
BIOLOGY I GREENBERG
DATA MANAGEMENT SMITH
EUROPEAN HISTORY BISCARDI
FICTION WRITING BUCK
MARKETING MAXWELL
PSYCHOANALYSIS NAKATSU
PSYCHOLOGY I ZABOSKI
TECHINCAL EDITING MADRID
TECHNICAL EDITING MADRID
VIDEO GAMES NEUMANNNote that "TECHINCAL EDITING" and "TECHNICAL EDITING" are both included in the NODUP data set because they are different ("TECHINCAL" is spelled incorrectly).
SELECT FROM(BRANCH) TO(HIGH3) ON(16,2,CH) FIRST(3) USING(HIGH) SORT FIELDS=(16,2,CH,A,18,4,ZD,D)
OUTFIL FNAMES=BRANCH,
BUILD=(16,2,2X,18,4,ZD,EDIT=(IIT))State Employees
CA 35
CA 32
CA 29
CA 22
CA 21
CA 18
CA 15
CO 33
CO 32
CO 22
CO 20
CO 19 The FIRST(3) operand tells SELECT to keep the first 3 records for each ON field (the state). Finally, the OUTFIL statement extracts the state and employees values from the selected records.
CA 35
CA 32
CA 29
CO 33
CO 32
CO 22 | So far |
|---|
| So far in this chapter you have learned how to print statistics for numeric fields, create sorted and unsorted data sets, obtain a count of numeric fields in a range for a particular field, print fields from an input data set, print reports, print a count of field occurrences and select output records based on field occurrences. Next, you will learn how to use ICETOOL's SPLICE operator. |