 z/OS DFSMS Using Data Sets
z/OS DFSMS Using Data Sets
z/OS DFSMS Using Data Sets
z/OS DFSMS Using Data Sets
|
Previous topic |
Next topic |
Contents |
Contact z/OS |
Library |
PDF
Concatenating Unlike Data Sets z/OS DFSMS Using Data Sets SC23-6855-00 |
|
|
To concatenate unlike sequential data sets, you must modify the DCBOFLGS field of the DCB before the end of the current data set is reached. This informs the system that you are concatenating unlike data sets. DCBOFPPC is bit 4 of the DCBOFLGS field. Set bit 4, DCBOFPPC, to 1 by using the instruction OI DCBOFLGS,X'08'. If DCBOFPPC is 1, end-of-volume processing for each data set issues a close for the data set just read, and an open for the next concatenated data set. This closing and opening procedure updates the fields in the DCB and, performs the other functions of CLOSE and OPEN. If the buffer pool was obtained automatically by the open routine, the procedure also frees the buffer pool and obtains a new one for the next concatenated data set. The procedure does not free the buffer pool for the last concatenated data set unless your program supplied a DCBE with RMODE31=BUFF. Unless you have some way of determining the characteristics of the next data set before it is opened, you should not reset the DCBOFLGS field to indicate like attributes during processing. When you concatenate data sets with unlike attributes (that is, turn on the DCBOFPPC bit of the DCBOFLGS field), the EOV exit is not taken for the first volume of any data set. If the program has a DCB OPEN exit it is called at the beginning of every data set in the concatenation. If your program turns DCBOFPPC on before issuing OPEN, each time
the system calls your DCB OPEN exit routine or JFCBE exit, DCBESLBI
in your DCBE is on only if the current data set being started supports
large block interface (LBI). If you want to know in advance if all
the data sets support LBI, your program can take one of the following
actions:
When a new data set is reached and DCBOFPPC is on, you must reissue
the GET or READ macro that detected the end of the data set because
with QSAM, the new data set can have a longer record length, or with
BSAM the new data set can have a larger block size. You might need
to allocate larger buffers. Figure 1 shows a possible routine
for determining when a GET or READ must be reissued.
Figure 1. Reissuing
a READ or GET for Unlike Concatenated Data Sets
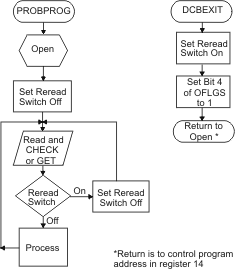 You might need to take special precautions if the program issues multiple READ macros without intervening CHECK or WAIT macros for those READS. Do not issue WAIT or CHECK macros to READ requests that were issued after the READ that detected end-of-data. These restrictions do not apply to data set to data set transition of like data sets, because no OPEN or CLOSE operation is necessary between data sets. You can code OPTCD=B in the DD statement, or you can code it for dynamic allocation. You cannot code OPTCD=B in the DCB macro. This parameter has an effect only during the reading of IBM, ISO, or ANSI standard labelled tapes. In those cases, it causes the system to treat the portion of the data set on each tape volume as a complete data set. In this way, you can read tapes in which the trailer labels incorrectly are end-of-data instead of end-of-volume. If you specify OPTCD=B in the DD statement for a multivolume tape data set, the system generates the equivalent of individual concatenated DD statements for each volume serial number and allocates one tape drive for each volume. Restriction: If you have a variable-blocked spanned (VBS) data set that spans volumes in such a way that one segment (for example, the first segment) is at the end of the first volume and the next segment (for example, the middle segment) is at the beginning of the next volume, and you attempt to treat these volumes as separate data sets, the integrity of the data cannot be guaranteed. QSAM will abend. QSAM's job is to ensure that it can put all of the segments together. This restriction will also be based on the data and whether the segments are split up between volumes. 

|
 Copyright IBM Corporation 1990, 2014 Copyright IBM Corporation 1990, 2014 |