Forest of trees indexes
A forest of trees index is like a B-tree index, but it has multiple root nodes and potentially fewer levels. Multiple root nodes can alleviate root node contention, because more concurrent users can access the index. A forest of trees index can also improve the performance of a query by reducing the number of levels involved in buffer read operations.
You can create a forest of trees index as an alternative to a B-Tree index, but not as an alternative to an R-Tree index or other types of indexes.
Unlike a traditional B-tree index, which contains one root node, a forest of trees index is a large B-Tree index that is divided into smaller subtrees (which you can think of as buckets). These subtrees contain multiple root nodes and leaves. The following figure shows the structure of a forest of trees index.
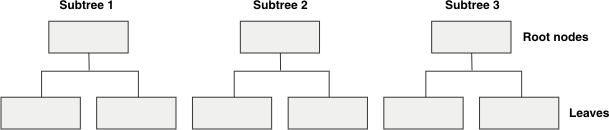
Informix® stores and retrieves an item from a subtree by:
- Computing a hash value from the columns that you selected when creating the index.
- Mapping the hash value to a subtree for storage or retrieval of the row.
Forest of trees indexes are detached indexes. The server does not support forest of trees attached indexes.
You create a forest of trees index with the CREATE INDEX statement of SQL and the HASH ON clause.
You enable or disable forest of trees indexes with the SET INDEXES statement of SQL.
You can identify a forest of trees index by the FOT indicator in the Index Name field in SET EXPLAIN output.
You can look up the number of hashed columns and subtrees in a forest of trees index by viewing information in the sysindices table for the database containing tables that have forest of trees indexes.
The server treats a forest of trees index the same way it treats a B-tree index. Therefore, in a logged database, you can control how the B-tree scanner threads remove deletions from both forest of trees and B-tree indexes.
- Create forest of trees indexes on columns with complex data types, UDTs, or functional columns.
- Use the FILLFACTOR option of the CREATE INDEX statement when you create forest of trees indexes, because the indexes are built from top to bottom.
- Create clustered forest of trees indexes.
- Run the ALTER INDEX statement on forest of trees indexes.
- Run the SET INDEXES statement on forest of trees indexes in a database of secondary servers within a cluster environment.
- Use forest of trees indexes in queries that use aggregates, including minimum and maximum range values.
- Perform range scans directly on the HASH ON columns of a forest
of trees index.
However, you can perform range scans on columns that are not listed in the HASH ON column list. For range scans on columns listed in HASH ON column list, you must create an additional B-tree index that contains the appropriate column list for the range scan. This additional B-tree index might have the same column list as the forest of trees index, plus or minus a column.
- Use a forest of trees index for an OR index path. The database server does not use forest of trees indexes for queries that have an OR predicate on the indexed columns.