Data deduplication and node replication are optional functions that can be used with Tivoli® Storage Manager. They provide added benefits but also require additional resources and consideration for the daily schedule.
About this task
Depending on your environment, using data deduplication and node replication can change the tasks that are required for the daily schedule. If you are using node replication to create the backup copy of your data, then storage pool backups are not needed. Likewise, you do not need to migrate your data to tape storage pools for the creation of offsite backup media.
The following image illustrates
how to schedule data deduplication and node replication processes
to achieve the best performance. Tasks that overlap in the image can
be run at the same time.
Restriction: The amount of duplicate
identification processes that can be overlapped is based on the processor
capability of the Tivoli Storage
Manager server
and the I/O capability of the storage pool disk.
Figure 1. Daily schedule when data deduplication
and node replication are used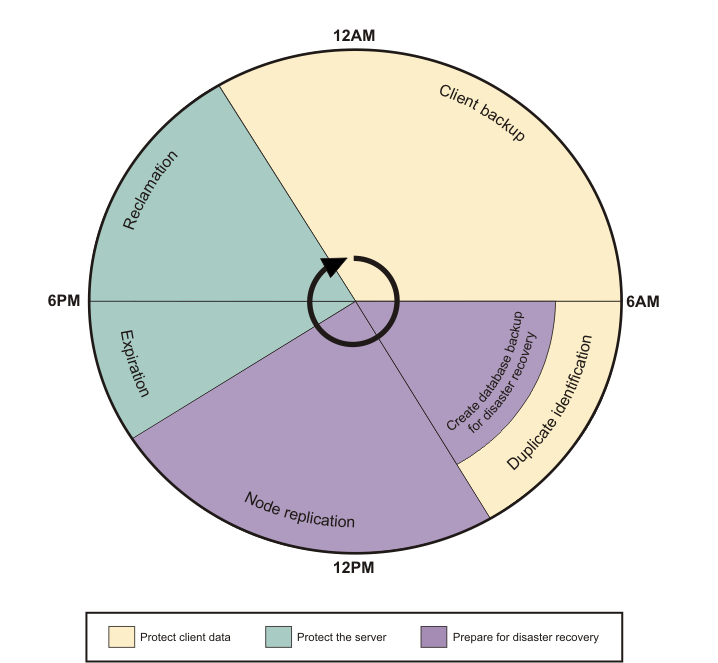
The following steps include commands to implement the schedule that is shown in the image. For this example, tape is not used in the environment.