Data partition elimination refers to the database server's ability to determine, based on query predicates, that only a subset of the data partitions in a table need to be accessed to answer a query. Data partition elimination is particularly useful when running decision support queries against a partitioned table.
A partitioned table uses a data organization scheme in which table data is divided across multiple storage objects, called data partitions or ranges, according to values in one or more table partitioning key columns of the table. Data from a table is partitioned into multiple storage objects based on specifications provided in the PARTITION BY clause of the CREATE TABLE statement. These storage objects can be in different table spaces, in the same table space, or a combination of both.
create table custlist(
subsdate date, province char(2), accountid int)
partition by range(subsdate) (
starting from '1/1/1990' in ts1,
starting from '1/1/1991' in ts1,
starting from '1/1/1992' in ts1,
starting from '1/1/1993' in ts2,
starting from '1/1/1994' in ts2,
starting from '1/1/1995' in ts2,
starting from '1/1/1996' in ts3,
starting from '1/1/1997' in ts3,
starting from '1/1/1998' in ts3,
starting from '1/1/1999' in ts4,
starting from '1/1/2000' in ts4,
starting from '1/1/2001'
ending '12/31/2001' in ts4) select * from custlist
where subsdate between '1/1/2000' and '12/31/2000'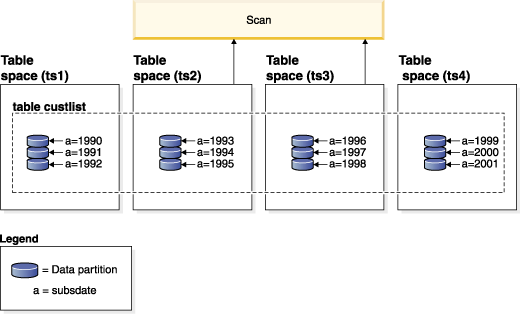
create table multi (
sale_date date, region char(2))
partition by (sale_date) (
starting '01/01/2005'
ending '12/31/2005'
every 1 month)
create index sx on multi(sale_date)
create index rx on multi(region) select * from multi
where sale_date between '6/1/2005'
and '7/31/2005' and region = 'NW'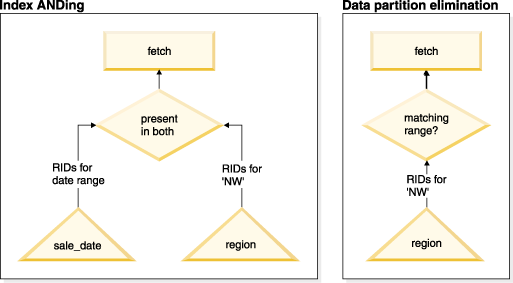
select * from custlist
where subsdate between '12/31/1999' and '1/1/2001'Arguments:
---------
DPESTFLG: (Number of data partitions accessed are Estimated)
FALSE
DPLSTPRT: (List of data partitions accessed)
9-11
DPNUMPRT: (Number of data partitions accessed)
3
DP Elim Predicates:
------------------
Range 1)
Stop Predicate: (Q1.A <= '01/01/2001')
Start Predicate: ('12/31/1999' <= Q1.A)
Objects Used in Access Plan:
---------------------------
Schema: MRSRINI
Name: CUSTLIST
Type: Data Partitioned Table
Time of creation: 2005-11-30-14.21.33.857039
Last statistics update: 2005-11-30-14.21.34.339392
Number of columns: 3
Number of rows: 100000
Width of rows: 19
Number of buffer pool pages: 1200
Number of data partitions: 12
Distinct row values: No
Tablespace name: <VARIOUS> create table sales (
year int, month int)
partition by range(year, month) (
starting from (2001,1)
ending at (2001,3) in ts1,
ending at (2001,6) in ts2,
ending at (2001,9) in ts3,
ending at (2001,12) in ts4,
ending at (2002,3) in ts5,
ending at (2002,6) in ts6,
ending at (2002,9) in ts7,
ending at (2002,12) in ts8)
select * from sales where year = 2001 and month < 8 select * from sales
where (year = 2001 and month <= 3)
or (year = 2002 and month >= 10) create table sales (
a int, b int generated always as (a / 5))
in ts1,ts2,ts3,ts4,ts5,ts6,ts7,ts8,ts9,ts10
partition by range(b) (
starting from (0)
ending at (1000) every (50)) select * from sales where a > 35Join predicates can also be used in data partition elimination, if the join predicate is pushed down to the table access level. The join predicate is only pushed down to the table access level on the inner join of a nested loop join (NLJN).
create table t1 (a int, b int)
partition by range(a,b) (
starting from (1,1)
ending (1,10) in ts1,
ending (1,20) in ts2,
ending (2,10) in ts3,
ending (2,20) in ts4,
ending (3,10) in ts5,
ending (3,20) in ts6,
ending (4,10) in ts7,
ending (4,20) in ts8)
create table t2 (a int, b int) P1: T1.A = T2.A
P2: T1.B > 15In this example, the exact data partitions that will be accessed at compile time cannot be determined, due to unknown outer values of the join. In this case, as well as cases where host variables or parameter markers are used, data partition elimination occurs at run time when the necessary values are bound.
During run time, when T1 is the inner of an NLJN, data partition elimination occurs dynamically, based on the predicates, for every outer value of T2.A. During run time, the predicates T1.A = 3 and T1.B > 15 are applied for the outer value T2.A = 3, which qualifies the data partitions in table space TS6 to be accessed.
| Outer table T2: column A | Inner table T1: column A | Inner table T1: column B | Inner table T1: data partition location |
|---|---|---|---|
| 2 | 3 | 20 | TS6 |
| 3 | 2 | 10 | TS3 |
| 3 | 2 | 18 | TS4 |
| 3 | 15 | TS6 | |
| 1 | 40 | TS3 |
Starting in DB2® Version 9.7 Fix Pack 1, you can create an index over XML data on a partitioned table as either partitioned or nonpartitioned. The default is a partitioned index.
Partitioned and nonpartitioned XML indexes are maintained by the database manager during table insert, update, and delete operations in the same way as any other relational indexes on a partitioned table are maintained. Nonpartitioned indexes over XML data on a partitioned table are used in the same way as indexes over XML data on a nonpartitioned table to speed up query processing. Using the query predicate, it is possible to determine that only a subset of the data partitions in the partitioned table need to be accessed to answer the query.
create table employee (a int, b xml, c xml)
index in tbspx
partition by (a) (
starting 0 ending 10,
ending 20,
ending 30,
ending 40) select * from employee
where a > 21
and xmlexist('$doc/Person/Name/First[.="Eric"]'
passing "EMPLOYEE"."B" as "doc")The optimizer can immediately eliminate the first two partitions based on the predicate a > 21. If the nonpartitioned index over XML data on column B is chosen by the optimizer in the query plan, an index scan using the index over XML data will be able to take advantage of the data partition elimination result from the optimizer and only return results belonging to partitions that were not eliminated by the relational data partition elimination predicates.