In a table that is both multidimensional clustered and data partitioned, columns can be used both in the table partitioning range-partition-spec and in the multidimensional clustering (MDC) key. A table that is both multidimensional clustered and partitioned can achieve a finer granularity of data partition and block elimination than could be achieved by either functionality alone.
There are also many applications where it is useful to specify different columns for the MDC key than those on which the table is partitioned. It should be noted that table partitioning is multicolumn, while MDC is multi-dimension.
MDC and table partitioning provide overlapping sets of benefits. The following table lists potential needs in your organization and identifies a recommended organization scheme based on the characteristics identified previously.
| Issue | Recommended scheme | Recommendation |
|---|---|---|
| Data availability during roll-out | Table partitioning | Use the DETACH PARTITION clause to roll out large amounts of data with minimal disruption. |
| Query performance | Table partitioning and MDC | MDC is best for querying multiple dimensions. Table partitioning helps through data partition elimination. |
| Minimal reorganization | MDC | MDC maintains clustering, which reduces the need to reorganize. |
| Rollout a month or more of data during a traditional offline window | Table partitioning | Data partitioning addresses this need fully. MDC adds nothing and would be less suitable on its own. |
| Rollout a month or more of data during a micro-offline window (less than 1 minute) | Table partitioning | Data partitioning addresses this need fully. MDC adds nothing and would be less suitable on its own. |
| Rollout a month or more of data while keeping the table fully available for business users submitting queries without any loss of service. | MDC | MDC only addresses this need somewhat. Table partitioning would not be suitable due to the short period the table goes offline. |
| Load data daily (either ALLOW READ ACCESS or ALLOW NO ACCESS) | Table partitioning and MDC | MDC provides most of the benefit here. Table partitioning provides incremental benefits. |
| Load data "continually" (ALLOW READ ACCESS) | Table partitioning and MDC | MDC provides most of the benefit here. Table partitioning provides incremental benefits. |
| Query execution performance for "traditional BI" queries | Table partitioning and MDC | MDC is especially good for querying cubes/multiple dimensions. Table partitioning helps via partition elimination. |
| Minimize reorganization pain, by avoiding the need for reorganization or reducing the pain associated with performing the task | MDC | MDC maintains clustering which reduces the need to reorg. If MDC is used, data partitioning does not provide incremental benefits. However if MDC is not used, table partitioning helps reduce the need for reorg by maintaining some course grain clustering at the partition level. |
Example 1:
Consider a table with key columns YearAndMonth and Province. A reasonable approach to planning this table might be to partition by date with 2 months per data partition. In addition, you might also organize by Province, so that all rows for a particular province within any two month date range are clustered together, as shown in Figure 1.
CREATE TABLE orders (YearAndMonth INT, Province CHAR(2))
PARTITION BY RANGE (YearAndMonth)
(STARTING 9901 ENDING 9904 EVERY 2)
ORGANIZE BY (Province);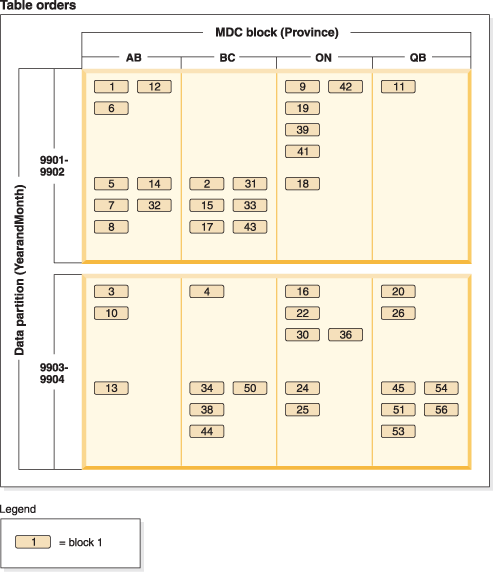
Example 2:
Finer granularity can be achieved by adding YearAndMonth to the ORGANIZE BY clause, as shown in Figure 2.
CREATE TABLE orders (YearAndMonth INT, Province CHAR(2))
PARTITION BY RANGE (YearAndMonth)
(STARTING 9901 ENDING 9904 EVERY 2)
ORGANIZE BY (YearAndMonth, Province);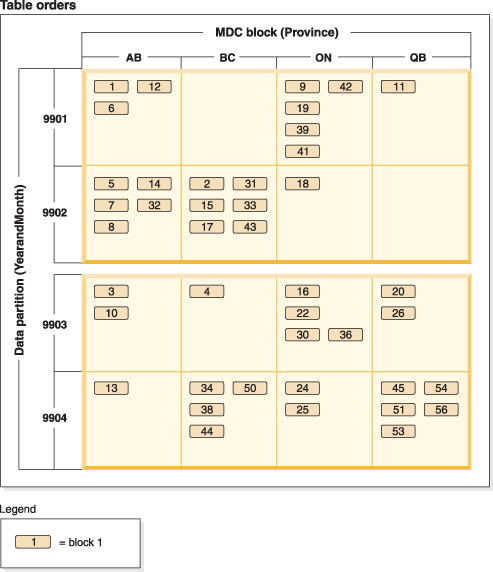
In cases where the partitioning is such that there is only a single value in each range, nothing is gained by including the table partitioning column in the MDC key.