Indexes on partitioned tables
The following types of indexes apply to only partitioned tables: partitioned indexes, partitioning indexes (PIs), data-partitioned secondary indexes (DPSIs), and nonpartitioned secondary indexes (NPIs or NPSIs).
Partitioned index
A partitioned index is an index that is physically partitioned. Any index on a partitioned table, except for an XML index, can be physically partitioned.
To create a partitioned index, specify PARTITIONED in the CREATE INDEX statement.
A partitioned index consists of multiple data sets. Each data set corresponds to a table partition. The following figure illustrates the difference between a partitioned index and a nonpartitioned index.
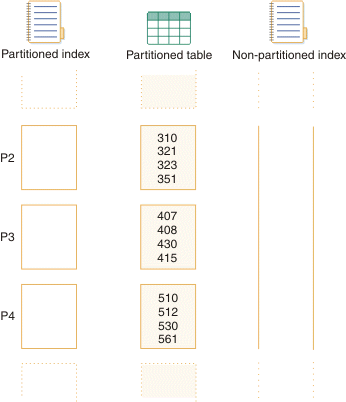
Partitioning index
A partitioning index is an index on the column or columns that partition the table.
The CREATE INDEX statement does not have a specific SQL keyword that designates an index as a partitioning index. Instead, an index is a partitioning index if the index key that is specified in the CREATE INDEX statement matches the partitioning key. The partitioning key is the column or columns that are specified in the PARTITION BY clause of the CREATE TABLE statement. Those columns partition the table. An index key matches the partitioning key if it has the same leftmost columns and collating sequence (ASC/DESC) as the columns in the partitioning key.
A partitioning key is different from the limit key values. A partitioning key defines the columns on which the table is partitioned. The limit key values define which values belong in each partition. Specifically, a limit key value is the value of the partitioning key that defines the partition boundary. It is the highest value of the partitioning key for an ascending index, or the lowest value for a descending index. Limit key values are specified in the PARTITION... ENDING AT clause of a CREATE TABLE statement or ALTER TABLE statement. The specified ranges partition the table space and the corresponding partitioning index space.
Partitioning is different from clustering. Clustering is a grouping that controls how rows are physically ordered in a partition or table space. Clustering is controlled by a clustering index and can apply to any type of table space. Partitioning applies to only partitioned table spaces. Partitioning is a grouping that guarantees that rows are inserted into certain partitions based on certain value ranges as defined by the limit key values. You can however use clustering and partitioning together. If you use the same index for clustering and partitioning the rows are physically ordered across the entire table space.
Partitioning indexes are not the same as partitioned indexes. However, it is best that all partitioning indexes also be partitioned.
Partitioning indexes are not required, because the partitioning scheme (the partitioning key and limit key values) are already defined in the table definition.
You might work with partitioned tables that were created in older versions of DB2® and the partitioning scheme was not defined as part of the table definition. In this case, a partitioning index is required to specify the partitioning scheme. (The partitioning key and the limit key values were specified in the PART VALUES clause of the CREATE INDEX statement.) This behavior is called index-controlled partitioning. DB2 can still process those indexes and the partitioned tables. However, all new partitioned tables should define the partitioning scheme in the table definition. This behavior is sometimes called table-controlled partitioning to distinguish it from the older index-controlled partitioning.
 Assume that a table contains state area codes, and you need to create a
partitioning index to sequence the area codes across partitions. You can use the following SQL
statements to create the table and the partitioning index:
Assume that a table contains state area codes, and you need to create a
partitioning index to sequence the area codes across partitions. You can use the following SQL
statements to create the table and the partitioning index:
CREATE TABLE AREA_CODES
(AREACODE_NO INTEGER NOT NULL,
STATE CHAR (2) NOT NULL,
…
PARTITION BY (AREACODE_NO ASC)
…CREATE INDEX AREACODE_IX1 ON AREA_CODES (AREACODE_NO)
CLUSTER (…
PARTITION 2 ENDING AT (400),
PARTITION 3 ENDING AT (500),
PARTITION 4 ENDING AT (600)),
…);
The following figure illustrates the partitioning index on the AREA_CODES table.
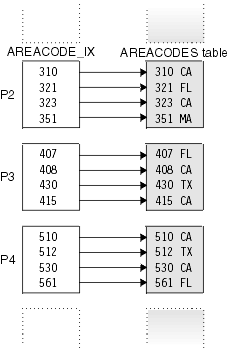
Nonpartitioning index (secondary index)
An index that is not a partitioning index is a nonparitioning index or secondary index. You can create a secondary index on a table to enforce a unique constraint, to cluster data, or to provide access paths to data for queries.
The usefulness of an index depends on the columns in its key and the cardinality of the key. Columns that you frequently select, join, group, or order are good candidates for keys. In addition, the number of distinct values in an index key for a large table must be sufficient for DB2 to use the index to retrieve data. Otherwise, DB2 might choose to do a table space scan.
You can create two types of secondary indexes: those that are partitioned (called data-partitioned secondary indexes) and those that are nonpartitioned (called nonpartitioned secondary indexes).
- Data-partitioned secondary index (DPSI)
- A data-partitioned secondary index (DPSI) is a nonpartitioning index that is
physically partitioned according to the partitioning scheme of the underlying data.
A DPSI has as many partitions as the number of partitions in the table space. Each DPSI partition contains keys for the rows of the corresponding table space partition only. For example, if the table space has three partitions, the keys in DPSI partition 1 reference only the rows in table space partition 1; the keys in DPSI partition 2 reference only the rows in table space partition 2, and so on.
Restrictions:- You can create a DPSI only on a table in a partitioned table space.
- You cannot create a DPSI for a partition-by-growth table space.
- An XML index cannot be a DPSI.
To define a DPSI, use the PARTITIONED keyword in the CREATE INDEX statement and specify an index key that does not match the partitioning key columns. If the leftmost columns of the index that you specify with the PARTITIONED keyword match the partitioning key, DB2 creates the index as a DPSI only if the collating sequence of the matching columns is different.
The use of DPSIs promotes partition independence and therefore provides the following performance advantages, among others:
- Eliminates contention between parallel LOAD utility jobs with the PART option that target different partitions of a table space
- Facilitates partition-level operations such as adding a partition or rotating a partition to be the last partition
- Improves the recovery time of secondary indexes on partitioned table spaces
However, the use of DPSIs does not always improve the performance of queries. For example, for queries with predicates that reference only the columns in the key of the DPSI, DB2 must probe each partition of the index for values that satisfy the predicate.
DPSIs provide performance advantages for queries that meet all of the following criteria:
- The query has predicates on the DPSI columns.
- The query contains additional predicates on the partitioning columns of the table that limit the query to a subset of the partitions in the table.
- Nonpartitioned secondary index (NPI or NPSI)
- A nonpartitioned secondary index (NPI or NPSI) is any index that is not defined as
a partitioning index or a partitioned index. An NPI index has one index space that contains keys for
the rows of all partitions of the table space.
You can create an NPI on a table in a partitioned table space. These indexes do not apply to nonpartitioned table spaces.
NPIs provide performance advantages for queries that meet the following criteria:
- The query does not contain predicates on the partitioning columns of the table that limit the query to a small subset of the partitions in the table.
- The query qualifications match the index columns.
- The SELECT list columns are included in the index (for index-only access).
To understand the advantages of using DPSIs and NPIs, consider the following example. Suppose that you use the following SQL statements to create a DPSI (DPSIIX2) and an NPI (NPSIIX3) on the AREA_CODES table.
CREATE INDEX DPSIIX2 ON AREA_CODES (STATE) PARTITIONED;
CREATE INDEX NPSIIX3 ON AREA_CODES (STATE); The AREA_CODES table must be partitioned on something other than the STATE column for these indexes to be secondary indexes.
The following figure illustrates what these indexes look like.
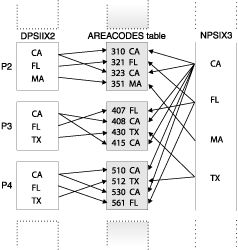
Consider the following SELECT statement:
SELECT STATE FROM AREA_CODES
WHERE AREACODE_NO *<= 300 AND STATE = ‘CA';This query can make efficient use of the DPSI. The number of key values that need to be searched is limited to the key values of the qualifying partitions. If a nonpartitioned secondary query, there may be a more comprehensive index scan of the key values.
Consider the following SELECT statement:
SELECT STATE FROM AREA_CODES
WHERE AREACODE_NO <= 300 AND STATE > ‘CA';This query makes efficient use of the NPI on columns AREACODE_NO and STATE, partitioned by STATE. The number of key values that need to be searched is limited to scanning the index key values that are lower than or equal to 300.
DPSIs provide advantages over NPIs for utility processing. For example, utilities such as COPY, REBUILD INDEX, and RECOVER INDEX can operate on physical partitions rather than logical partitions because the keys for a data partition reside in a single DPSI partition. This method can provide greater availability.