z/OS concepts
z/OS concepts
z/OS concepts
z/OS concepts
|
Previous topic |
Next topic |
Contents |
Glossary |
Contact z/OS |
PDF
z/OS data sets versus file system files z/OS concepts |
|
|
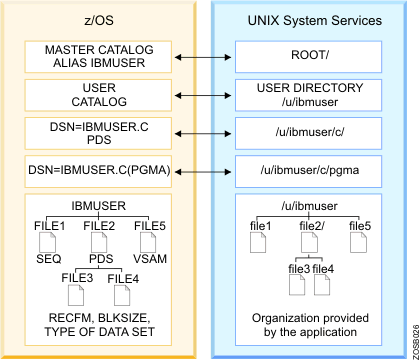
Many elements of UNIX® have analogs in the z/OS® operating system. Consider, for example, that the organization of a user catalog is analogous to a user directory (/u/ibmuser) in the file system. In z/OS, the user prefix assigned to z/OS data sets points to a user catalog. Typically, one user owns all the data sets whose names begin with his user prefix. For example, the data sets belonging to the TSO/E user ID IBMUSER all begin with the high-level qualifier (prefix) IBMUSER. There could be different data sets named IBMUSER.C, IBMUSER.C.OTHER and IBMUSER.TEST. In the UNIX file system, ibmuser would have a user directory named /u/ibmuser. Under that directory there could be a subdirectory named /u/ibmuser/c, and /u/ibmuser/c/pgma would point to the file pgma (see Figure 1). Of the various types of z/OS data sets, a partitioned data set (PDS) is most like a user directory in the file system. In a partitioned data set such as IBMUSER.C, you could have members (files) PGMA, PGMB, and so on. For example, you might have IBMUSER.C(PGMA) and IBMUSER.C(PGMB). Along the same lines, a subdirectory such as /u/ibmuser/c can hold many files, such as pgma, pgmb, and so on. All data written to a hierarchical file system can be read by all programs as soon as it is written. Data is written to a disk when a program issues an fsync() . |
 Copyright IBM Corporation 1990, 2010 Copyright IBM Corporation 1990, 2010 |