Recommendations for EVI use
Encoded vector indexes are a powerful tool for providing fast data access in decision support and query reporting environments. To ensure the effective use of EVIs, use the following guidelines.
Create EVIs on
- Read-only tables or tables with a minimum of INSERT, UPDATE, DELETE activity.
- Key columns that are used in the WHERE clause - local selection predicates of SQL requests.
- Single key columns that have a relatively small set of distinct values.
- Multiple key columns that result in a relatively small set of distinct values.
- Key columns that have a static or relatively static set of distinct values.
- Non-unique key columns, with many duplicates.
Create EVIs with the maximum byte code size expected
- Use the "WITH n DISTINCT VALUES" clause on the CREATE ENCODED VECTOR INDEX statement.
- If unsure, use a number greater than 65,535 to create a 4 byte code. This method avoids the EVI maintenance involved in switching byte code sizes.
- EVIs with INCLUDE always create with a 4 byte code.
When loading data
- Drop EVIs, load data, create EVIs.
- EVI byte code size is assigned automatically based on the number of actual distinct key values found in the table.
- Symbol table contains all key values, in order, no keys in overflow area.
- EVIs with INCLUDE always use 4 byte code
Consider adding INCLUDE values to existing EVIs
An EVI index with INCLUDE values can be used to supply ready-made aggregate results. The existing symbol table and vector are still used for table selection, when appropriate, for skip sequential plans over large tables, or for index ANDing and ORing plans. If you already have EVIs, consider creating new ones with additional INCLUDE values, and then drop the pre-existing index.
Consider specifying multiple INCLUDE values on the same EVI create
If you need different aggregates over different table values for the same GROUP BY columns specified as EVI keys, define those aggregates in the same EVI. This definition cuts down on maintenance costs and allows for a single symbol table and vector.
For example:
Select SUM(revenue) from sales group by CountrySelect SUM(costOfGoods) from sales group by Country, RegionBoth queries could benefit from the following EVI:
CREATE ENCODED VECTOR INDEX eviCountryRegion on Sales(country,region)
INCLUDE(SUM(revenue), SUM(costOfGoods))The optimizer does additional grouping (regrouping) if the EVI key values are wider than the corresponding GROUP BY request of the query. This additional grouping would be the case in the first example query.
If an aggregate request is specified over null capable results, an implicit COUNT over that same result is included as part of the symbol table entry. The COUNT is used to facilitate index maintenance when a requested aggregate needs to reflect. It can also assist with pushing aggregation through a join if the optimizer determines this push is possible. The COUNT is then used to help compensate for fewer join activity due to the pushed down grouping.
Consider EVI INCLUDE and Grouping Sets
EVI INCLUDE support has been expanded to match GROUPING SETs, ROLLUP and CUBE queries.
When EVI INCLUDES are available over a table being aggregated over in a grouping sets query, the query is rewritten to facilitate and match any EVI INCLUDE indexes that might be available. This can result in exceeding good query performance because the table is never accessed. All the aggregate variations necessary to perform the rollup, cube or grouping set query result can be performed over the EVI symbol table with INCLUDE values.
For example on the ROLLUP query below, the grouping is the sum of quantity rolled up at various levels (month, quarter, year) and ONLY the symbol table of the encoded vector index is accessed in the access plan.
SELECT year(shipdate) year_ship, quarter(shipdate) quarter, month(shipdate) month_ship, sum(quantity)
as totquantity
FROM item_fact
GROUP BY ROLLUP (Year(shipdate), Quarter(shipdate), month(shipdate));Here is the EVI INCLUDE create that will facilitate the rollup query.
CREATE ENCODED VECTOR INDEX GS_EVI
ON ITEM_FACT
( YEAR ( SHIPDATE ) ASC , QUARTER ( SHIPDATE ) ASC , MONTH ( SHIPDATE ) ASC )
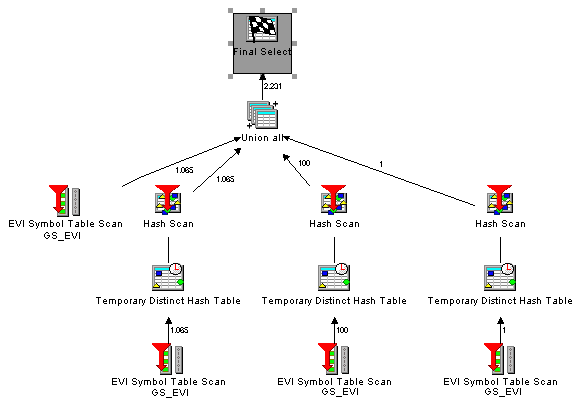
INCLUDE ( SUM ( QUANTITY ) , COUNT ( * ) );The following graphic shows a Visual Explain that illustrates the access and the performance. Instead of accessing potentially millions of rows, the access is over a rather modest size symbol table.
Consider SMP and parallel index creation and maintenance
Symmetrical Multiprocessing (SMP) is a valuable tool for building and maintaining indexes in parallel. The results of using the optional SMP feature of IBM® i are faster index build times, and faster I/O velocities while maintaining indexes in parallel. Using an SMP degree value of either *OPTIMIZE or *MAX, additional multiple tasks and additional system resources are used to build or maintain the indexes. With a degree value of *MAX, expect linear scalability on index creation. For example, creating indexes on a 4-processor system can be four times as fast as a 1-processor system.
Checking values in the overflow area
You can also use the Display File Description (DSPFD) command (or System i® Navigator - Database) to check how many values are in the overflow area. Once the DSPFD command is issued, check the overflow area parameter for details on the initial and actual number of distinct key values in the overflow area.
Using CHGLF to rebuild the access path of an index
Use the Change Logical File (CHGLF) command with the attribute Force Rebuild Access Path set to YES (FRCRBDAP(*YES)). This command accomplishes the same thing as dropping and recreating the index, but it does not require that you know about how the index was built. This command is especially effective for applications where the original index definitions are not available, or for refreshing the access path.