| 1 | Receiver variable | Output | Char(*) |
| 2 | Length of receiver variable | Input | Binary(4) |
| 3 | Format | Input | Char(8) |
| 4 | Locale path name | Input | Char(*) |
| 5 | Locale category key to return | Input | Binary(4) |
| 6 | Error code | I/O | Char(*) |
The Retrieve Locale Information (OPM, QLGRTVLC; ILE, QlgRetrieveLocaleInformation) API retrieves information from one category of a locale or retrieves all categories of a locale. For more information about locales, see the i5/OS globalization topic collection.
The variable that is to receive the information requested. If requesting the LC_CTYPE or the LC_COLLATE categories, the information returned could potentially be very large if the locale data type indicator (returned within the receiver variable) indicates that the locale data is mixed-byte, double-byte (includes ISO 10646 16-bit character encoding standard (UCS2)), UTF8 or UTF32.
In this case, a user space with the auto-extendable attribute set may provide a better means for the receiver variable. For further information on using a user space for a receiver variable, see Receiver variables in API concepts.
The length of the receiver variable. If the length is larger than the size of the receiver variable, the results may not be predictable. The minimum length is 8 bytes.
The format of the locale information to be returned. The following format name must be used:
| LOCI0100 | Locale information |
Refer to Format of the Locale Information for more information on the locale format.
The structure that contains the path name information of the locale used to retrieve the information. For more information on this structure, see Path name format.
The following special values are allowed for the path name field in the path name structure:
| *C | Use the C locale. This special value must be specified in the first 2 characters of the path name field of the path name structure. The C locale is equivalent to the POSIX locale. |
| *ENV | Use the locale defined in the environment of the job. This special value must be specified in the first 4 characters of the path name field of the path name structure. |
| *POSIX | Use the POSIX locale, which is designed to meet the X/Open POSIX locale specification. This special value must be specified in the first 6 characters of the path name field of the path name structure. The POSIX locale is equivalent to the C locale. |
When *ENV is specified for the locale path name, the API will retrieve the locale information from the environment variable. The API will assume the '/' character as the path name delimiter. If the CCSID for the path name in the environment variable is 65535, the API will assume the job default CCSID.
If *ENV is specified and the requested category is not LC_ALL, the API will use the locale defined in the environment variable as defined by the first condition met below:
If *ENV is specified and the requested category is LC_ALL, the API uses the locale defined in the environment variable as defined by the first condition met below:
If none of the locale environment variables are defined for the requested category or if the locale defined is found to be not valid or does not exist, an error is returned.
The key of the locale category to retrieve information on. Refer to Locale Category Keys for more information.
The structure in which to return error information. For the format of the structure, see Error code parameter.
The following table lists the valid locale category keys for the Locale category key to return parameter. For a detailed description of each field, see Locale Category Key Descriptions.
| Key | Field |
|---|---|
| -1 | LC_ALL - All categories |
| 1 | LC_CTYPE - Character classification and conversion |
| 2 | LC_COLLATE - Character collation |
| 3 | LC_TIME - Date and time formatting |
| 4 | LC_NUMERIC - Numeric and non-monetary formatting |
| 5 | LC_MESSAGES - Affirmative and negative responses |
| 6 | LC_MONETARY - Monetary related numeric formatting |
| 7 | LC_TOD - Time zone information |
LC_ALL - All categories. Return all categories in the locale.
LC_COLLATE - Character collation. Provides a collation sequence definition for characters and character strings. A collation sequence defines the relative order between the collating elements in the locale.
LC_CTYPE - Character classification and conversion. Defines character classification, conversion and other character attributes such as printable and punctuation characters.
LC_MESSAGES - Affirmative and negative responses. Defines the format and values for affirmative and negative responses.
LC_MONETARY - Monetary related numeric formatting. Defines the rules and symbols that are used to format monetary numeric information.
LC_NUMERIC - Numeric and non-monetary formatting. Defines the rules and symbols that are used to format non-monetary numeric information.
LC_TIME - Date and time formatting. Defines the interpretation for date and time formatting. This category supports the Gregorian (7-day weeks, 12-month years, leap years, and so forth) style calendar only.
LC_TOD - Time zone information. Defines the time zone information (name of the time zone, daylight savings time start and end, and so forth).
The following information is returned in the receiver variable. For a detailed description of each field, see Path name format. For a detailed description of each locale category, refer to the locale category formats.
Upon return from the call to the API, it is highly recommended that the bytes returned and bytes available fields be examined first. If the bytes available field is greater than the bytes returned field, the API had more information to return than what could fit in the receiver variable provided on the call. When this occurs, calling the API again with a receiver variable at least the size of the value in the bytes available field is highly recommended. This is due to the wide use of offsets by this API. If not enough room was available, an offset may contain a value of where the information would have started if the receiver variable were large enough. Attempting to access the information at this offset may cause unpredictable results.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| 0 | 0 | BINARY(4) | Bytes returned |
| 4 | 4 | BINARY(4) | Bytes available |
| 8 | 8 | BINARY(4) | Locale category key |
| 12 | C | BINARY(4) | Offset to category information. Refer to Locale Category Formats for further details. |
| 16 | 10 | BINARY(4) | Length of category information |
| 20 | 14 | CHAR(*) | Reserved |
A format is defined for each locale category. An offset and length field are provided for all fields that are variable in length. The variable length fields may contain character data, binary data or a combination of character and binary data. The type of data that the field contains is described in the field descriptions.
The locale data type is used to determine if the locale data returned contains single-byte data, mixed-byte data (single-byte and double-byte mixed), pure double-byte data, UTF8 data or UTF32 data. If the data returned is EBCDIC mixed-byte data, the double-byte data is encased within a shift out (X'0E') and shift in (X'0F'), except when the single-byte and double-byte data is returned separately (for example, LC_CTYPE).
If there is no data available for the field and the field type is an offset to the information, the offset is set to a value of zero.
The format for which this information is returned is determined by the locale data type. For example, if the locale data type is 1, the information returned for this category would be in the Single-Byte Character Classification Structure. Refer to Field Descriptions for information on the possible data types for the locale data type field. For a detailed description of each field, see Path name format.
The explanations for the various arrays that are returned by the LC_CTYPE category all assume base zero.
The following information is returned for the single-byte character classification and conversion locale category.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| CHAR(256) | Single-byte uppercase conversion mapping. Refer to the Single-Byte Conversion Mapping Structures for further information on this field. | ||
| CHAR(256) | Single-byte lowercase conversion mapping. Refer to the Single-Byte Conversion Mapping Structures for further information on this field. | ||
| ARRAY(256) of UNSIGNED BINARY(2) | Single-byte character classification. Refer to the Single-Byte Character Classification Structure for further information on this field. | ||
| CHAR(*) | Reserved | ||
The following information is returned for the double-byte character classification and conversion locale category.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| BINARY(4) | Offset to double-byte uppercase conversion mapping. Refer to the Double-Byte Conversion Mapping Structures for further information on this field. | ||
| BINARY(4) | Offset to double-byte lowercase conversion mapping. Refer to the Double-Byte Conversion Mapping Structures for further information on this field. | ||
| BINARY(4) | Offset to double-byte character classification. Refer to the Double-Byte Character Classification Structure for further information on this field. | ||
| CHAR(*) | Reserved | ||
The following information is returned for the mixed-byte character classification and conversion category. The shift out and shift in control characters are not returned with this data.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| CHAR(256) | Single-byte uppercase conversion mapping. Refer to the Single-Byte Conversion Mapping Structures for further information on this field. | ||
| CHAR(256) | Single-byte lowercase conversion mapping. Refer to the Single-Byte Conversion Mapping Structures for further information on this field. | ||
| ARRAY(256) of UNSIGNED BINARY(2) | Single-byte character classification. Refer to the Single-Byte Character Classification Structure for further information on this field. | ||
| BINARY(4) | Offset to double-byte uppercase conversion mapping. Refer to the Double-Byte Conversion Mapping Structures for further information on this field. | ||
| BINARY(4) | Offset to double-byte lowercase conversion mapping. Refer to the Double-Byte Conversion Mapping Structures for further information on this field. | ||
| BINARY(4) | Offset to double-byte character classification. Refer to the Double-Byte Character Classification Structure for further information on this field. | ||
| CHAR(*) | Reserved | ||
The following information is returned for the four-byte character classification and conversion locale category.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| BINARY(4) | Offset to four-byte uppercase conversion mapping. Refer to the Four-Byte Conversion Mapping Structures for further information on this field. | ||
| BINARY(4) | Offset to four-byte lowercase conversion mapping. Refer to the Four-Byte Conversion Mapping Structures for further information on this field. | ||
| BINARY(4) | Offset to four-byte character classification. Refer to the Four-Byte Character Classification Structure for further information on this field. | ||
| CHAR(*) | Reserved | ||
The conversion information for the single-byte characters is stored within an Array(256) of Char(1).
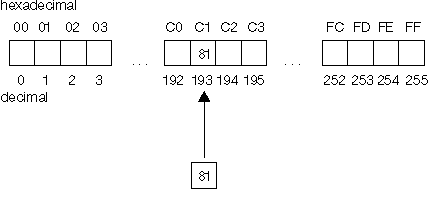
As illustrated in the example below, the conversion is performed by using the code point for the character that is to be converted as the subscript into the conversion mapping array. For example, if you have an uppercase character that has a code point (hexadecimal value) of 'C1', using the decimal value of this code point which is 193, you would go to the 193rd subscript of the lowercase conversion array and the value that is stored in that subscript is the code point for the lower case character. In this example, the lower case code point for uppercase character C1 is 81.
Conversion from lower to upper would be performed the same way except the code point for the lower case character would be used as the subscript into the uppercase conversion array.
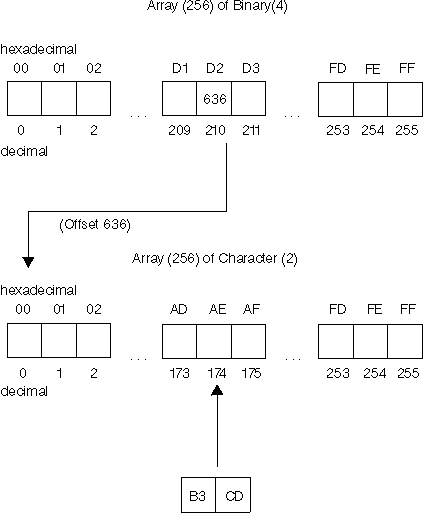
The conversion information for the double-byte characters is stored within an Array(256) of Binary(4) in which the Binary(4) elements of this array contain offsets to a second Array(256) of Character(2). The Character(2) elements of the second array contain the upper or lowercase character conversion mappings.
The double-byte code point for the character is used as the subscripts to access the arrays. The left-most byte of the double-byte character is used to access the first Array(256) of Binary(4). Within the subscripts of the first array are offsets to the second Array(256) of Character(2). The right-most byte of the double-byte character is used as the subscript to access this second array. Within this subscript is the double-byte upper or lowercase conversion character.
If the offset in the Binary(4) element of the first array is zero, than there is no case conversion available for that range of characters. For example, if you have an uppercase double-byte code point '40CE' and the offset in the first array for the lowercase conversion mapping was set to zero, this would indicate that all uppercase double-byte characters for this locale in the range where the left-most byte is '40' have no lowercase conversion available.
As illustrated in the example below, if you had a double-byte uppercase character 'D2AE', the decimal value of 'D2' is used as the subscript for the first array of the lowercase conversion mapping. The offset of 636 at this subscript is used to gain access to the second array and the decimal value of 'AE' is used as the subscript for the second array to access the double-byte lowercase character. In this example, the lowercase character for uppercase character 'D2AE' is 'B3CD'.
Conversion from lower to upper would be performed the same way except the code point for the lowercase character would be used as the subscripts into the uppercase conversion arrays.
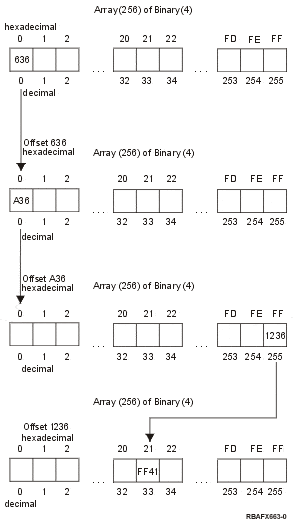
The conversion information for the four-byte characters is stored within an Array(256) of Binary(4). The Binary(4) elements of this array contain offsets to a second Array(256) of Binary(4). The Binary(4) elements of this second array contain offsets to a third Array(256) of Binary(4). The Binary(4) elements of this third array contain offsets to a fourth Array(256) of Binary(4). The Binary(4) elements of the fourth array contain the upper or lowercase character conversion mappings.
The four-byte code point for the character is used as the subscripts to access the arrays. The left-most byte of the four-byte character is used to access the first Array(256) of Binary(4). Within the subscripts of the first array are offsets to the second Array(256) of Binary(4). The second left-most byte of the four-byte character is used as the subscript to access this second array. Within the subscripts of the second array are offsets to the third Array(256) of Binary(4). The third left-most byte of the four-byte character is used as the subscript to access this third array. Within the subscripts of the third array are offsets to the fourth Array(256) of Binary(4). The right-most byte of the four-byte character is used as the subscript to access this fourth array. The Binary(4) elements of the fourth array contain the upper or lowercase character conversion mappings.
If the offset in the Binary(4) element of the first array is zero, then there is no case conversion available for that range of characters. For example, if you have an uppercase four-byte code point '000040CE' and the offset in the first array for the lowercase conversion mapping was set to zero, this would indicate that all uppercase four-byte characters for this locale in the range where the left-most byte is '00' have no lowercase conversion available. The same is also true when the offset in the second or third array is zero.
As illustrated in the example below, if you had a four-byte uppercase character '0000FF21', the value of '00' is used as the subscript for the first array of the lowercase conversion mapping. The offset of 636 at this subscript is used to gain access to the second array. The value of '00' is used as the subscript for the second array to access the third array. The offset of A36 at this subscript is used to gain access to the third array and the value of 'FF' is used as the subscript for the third array to access the fourth array. The offset of 1236 at this subscript is used to gain access to the fourth array and the value of '21' is used as the subscript for the fourth array to access the four-byte lowercase character. In this example, the lowercase character for uppercase character '0000FF21' is '0000FF41'.
Conversion from lower to upper would be performed the same way except the code point for the lowercase character would be used as the subscripts into the uppercase conversion arrays.
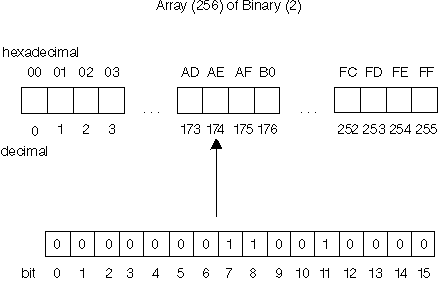
The character classification information for the single-byte character is stored within 2 bytes (16 bits) with one element of the Array(256) for each single-byte character. The decimal value for the hexadecimal code point for the single-byte character is used as the subscript for the array.
Each bit represents a character classification. If the value of the bit is set to 1, the character is of that classification. If set to 0, the character is not of that classification. The bit representations are as follows:

| Bit | Character Classification |
|---|---|
| 0-4 | Undefined |
| 5 | Punctuation - characters classified as punctuation characters |
| 6 | Graph - characters classified as printable characters, not including the space character |
| 7 | Alphabetic - characters classified as letters |
| 8 | Upper - characters classified as uppercase letters |
| 9 | Lower - characters classified as lowercase letters |
| 10 | Control - characters to be classified as control characters |
| 11 | Print - characters classified as printable characters, including the space character |
| 12 | Blank - characters classified as blank characters |
| 13 | Space - characters classified as white-space characters |
| 14 | Digit - characters classified as numeric digits |
| 15 | Hexadecimal digit - characters classified as hexadecimal digits |
As illustrated in the example below, the conversion is performed by using the code point for the single-byte character as the subscript into the array. For example, if you have a single-byte character that has a code point of 'AE', use the decimal value of this code point as the subscript into the array. The Binary(2) element of the array contains the 16 character classification bits. This example shows that this character is of the print, upper, and alphabetic character classifications.
The character classification information for the double-byte characters are stored within an Array(256) of Binary(4) in which the Binary(4) elements of this array contain offsets to a second Array(256) of Binary(4). The Binary(4) elements of the second array contain the 4 bytes (32 bits) that hold the bit representation for the double-byte character classification.
If the offset in the first array is set to zero, this double-byte character range is not defined. For example, if you have a double-byte code point 'CDFE' and the offset for the first array is set to zero, this would indicate that all double-byte characters for this locale in the range where the left-most byte was 'CD' have no character classification available.
The double-byte code point for the character is used as the subscripts to access the array. The left-most byte of the double-byte character is used to access the first Array(256) of Binary(4). Within the subscripts of the first array are offsets to the second Array(256) of Binary(4). The right-most byte of the double-byte character is used as the subscript to access this second array. Within this subscript are the 32 bits that contain the character classification information.
Each bit represents a character classification. If the value of the bit is set to 1, the character is of that classification. If set to 0, the character is not of that classification. The bit representations are as follows:
| Bit | Character Classification |
|---|---|
| 0-20 | Undefined |
| 21 | Punctuation - characters classified as punctuation characters |
| 22 | Graph - characters classified as printable characters, not including the space character |
| 23 | Alphabetic - characters classified as letters |
| 24 | Upper - characters classified as uppercase letters |
| 25 | Lower - characters classified as lowercase letters |
| 26 | Control - characters to be classified as control characters |
| 27 | Print - characters classified as printable characters, including the space character |
| 28 | Blank - characters classified as blank characters |
| 29 | Space - characters classified as white-space characters |
| 30 | Digit - characters classified as numeric digits |
| 31 | Hexadecimal digit - characters classified as hexadecimal digits |
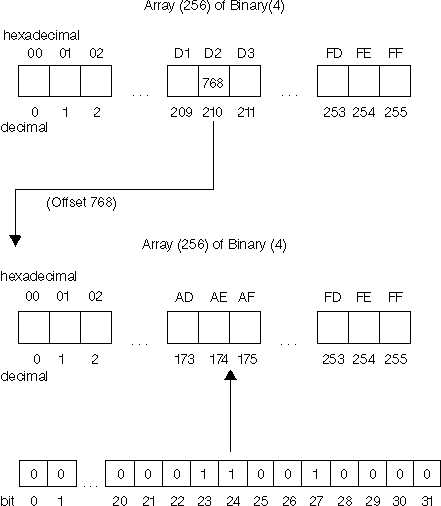
As illustrated in the example below, if you had a double-byte character 'D2AE', the decimal value of 'D2' is used as the subscript for the first array. The offset of 768 at this subscript is used to gain access to the second array. The decimal value of 'AE' is then used as the subscript for the second array. At this subscript are the 32 bits that contain the character classification information for the double-byte character. This example shows that this character is of the print, upper, and alphabetic character classifications.
The character classification information for the four-byte characters is stored within an Array(256) of Binary(4). The Binary(4) elements of this array contain offsets to a second Array(256) of Binary(4). The Binary(4) elements of this second array contain offsets to a third Array(256) of Binary(4). The Binary(4) elements of this third array contain offsets to a fourth Array(256) of Binary(4). The Binary(4) elements of the fourth array contain the 4 bytes (32 bits) that hold the bit representation for the four-byte character classification.
If the offset in the Binary(4) element of the first array is zero, then this four-byte character range is not defined. For example, if you have an four-byte code point '000040CE' and the offset in the first array was set to zero, this would indicate that all four-byte characters for this locale in the range where the left-most byte is '00' have no character classification available. The same is also true when the offset in the second or third array is zero.
The four-byte code point for the character is used as the subscripts to access the arrays. The left-most byte of the four-byte character is used to access the first Array(256) of Binary(4). Within the subscripts of the first array are offsets to the second Array(256) of Binary(4). The second left-most byte of the four-byte character is used as the subscript to access this second array. Within the subscripts of the second array are offsets to the third Array(256) of Binary(4). The third left-most byte of the four-byte character is used as the subscript to access this third array. Within the subscripts of the third array are offsets to the fourth Array(256) of Binary(4). The right-most byte of the four-byte character is used as the subscript to access this fourth array. Within this subscript are the 32 bits that contain the character classification information.
Each bit represents a character classification. If the value of the bit is set to 1, the character is of that classification. If set to 0, the character is not of that classification. The bit representations are as follows:
| Bit | Character Classification |
|---|---|
| 0-20 | Undefined |
| 21 | Punctuation - characters classified as punctuation characters |
| 22 | Graph - characters classified as printable characters, not including the space character |
| 23 | Alphabetic - characters classified as letters |
| 24 | Upper - characters classified as uppercase letters |
| 25 | Lower - characters classified as lowercase letters |
| 26 | Control - characters to be classified as control characters |
| 27 | Print - characters classified as printable characters, including the space character |
| 28 | Blank - characters classified as blank characters |
| 29 | Space - characters classified as white-space characters |
| 30 | Digit - characters classified as numeric digits |
| 31 | Hexadecimal digit - characters classified as hexadecimal digits |
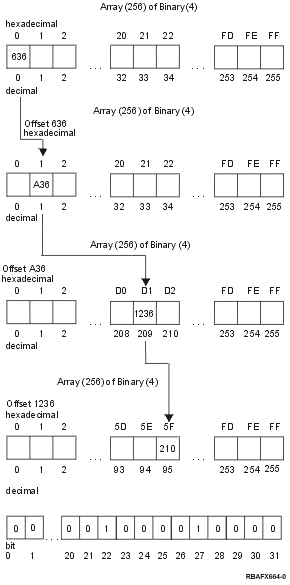
As illustrated in the example below, if you had a four-byte character '0001D15F', the value of '00' is used as the subscript for the first array of the character classification information. The offset of 636 at this subscript is used to gain access to the second array. The value of '01' is used as the subscript for the second array to access the third array. The offset of A36 at this subscript is used to gain access to the third array and the value of 'D1' is used as the subscript for the third array to access the fourth array. The offset of 1236 at this subscript is used to gain access to the fourth array and the value of '5F' is used as the subscript to access the fourth array. Within this subscript are the 32 bits that contain the character classification information.
The format for which this information is returned is determined by the locale data type. For example, if the locale data type is 1, the information returned for this category would be in the Single-byte Character Collation Structure. For a detailed description of each field, see Path name format.
The explanations for the various arrays that are returned by the LC_COLLATE category all assume base zero.
The following information is returned for the single-byte character collation structure.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data. | ||
| BINARY(4) | Locale data type. | ||
| BINARY(4) | Number of weights and sort rules. | ||
| BINARY(4) | Offset to sort rules. Refer to the Character Collation Sort Rules for further information on this field. | ||
| BINARY(4) | Offset to single-byte character collating table. Refer to the Single-byte Character Collating Table for further information on this field. | ||
| BINARY(4) | Offset to multi-character collating elements. Refer to the Multi-Character Collating Elements for further information on this field. | ||
| BINARY(4) | Offset to single-byte one-to-many character mappings. Refer to the One-to-Many Character Mappings for further information on this field. | ||
| CHAR(*) | Reserved | ||
The following information is returned for the double-byte character collation structure.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data. | ||
| BINARY(4) | Locale data type. | ||
| BINARY(4) | Number of weights and sort rules. | ||
| BINARY(4) | Offset to sort rules. Refer to the Character Collation Sort Rules for further information on this field. | ||
| BINARY(4) | Offset to double-byte character collating table. Refer to the Double-byte Character Collating Table for further information on this field. | ||
| BINARY(4) | Offset to multi-character collating elements. Refer to the Multi-Character Collating Elements for further information on this field. | ||
| BINARY(4) | Offset to double-byte one-to-many character
mappings. Refer to the One-to-Many Character Mappings
for further information on this field. |
||
| CHAR(*) | Reserved | ||
The following information is returned for the mixed-byte character collation structure. If the data returned is EBCDIC mixed-byte, the shift out and shift in control characters are only returned for the multi-character collating elements.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data. | ||
| BINARY(4) | Locale data type. | ||
| BINARY(4) | Number of weights and sort rules. | ||
| BINARY(4) | Offset to sort rules. Refer to the Character Collation Sort Rules for further information on this field. | ||
| BINARY(4) | Offset to single-byte character collating table. Refer to the Single-byte Character Collating Table for further information on this field. | ||
| BINARY(4) | Offset to double-byte character collating table. Refer to the Double-byte Character Collating Table for further information on this field. | ||
| BINARY(4) | Offset to multi-character collating elements. Refer to the Multi-Character Collating Elements for further information on this field. | ||
| BINARY(4) | Offset to single-byte one-to-many character mappings. Refer to the One-to-Many Character Mappings for further information on this field. | ||
| BINARY(4) | Offset to double-byte one-to-many character mappings. Refer to the One-to-Many Character Mappings for further information on this field. | ||
| CHAR(*) | Reserved | ||
The following information is returned for the four-byte character collation structure.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data. | ||
| BINARY(4) | Locale data type. | ||
| BINARY(4) | Number of weights and sort rules. | ||
| BINARY(4) | Offset to sort rules. Refer to the Character Collation Sort Rules for further information on this field. | ||
| BINARY(4) | Offset to four-byte character collating table. Refer to the Four-byte Character Collating Table for further information on this field. | ||
| BINARY(4) | Offset to multi-character collating elements. Refer to the Multi-Character Collating Elements for further information on this field. | ||
| BINARY(4) | Offset to four-byte one-to-many character
mappings. Refer to the One-to-Many Character Mappings
for further information on this field. |
||
| CHAR(*) | Reserved | ||
The sort rules are returned as an Array(*) of Binary(4) where the number of Binary(4) elements (or sort rules) is determined by the Number of weights and sort rules field. Each Binary(4) element is a sort rule. The sort rules are applied when comparing strings and they apply to all the collating element tables returned. The first sort rule is applied when comparing strings using the first weight; the second sort rule is applied when comparing strings using the second weight, and so on. The possible sort rules are:
| 1 | Forward - specifies that comparison operations for the weight level proceed from the start of the string towards the end of the string. |
| 2 | Backward - specifies that comparison operations for the weight level proceed from the end of the string towards the beginning of the string. |
| 8 | Position - specifies that comparison operations for the weight level will consider the relative position of elements in the strings not subject to ignore. Refer to Orders and Weights for further information on the ignore value. |
| 9 | Forward/Position - specifies that comparison operations for the weight level proceed from the start of the string towards the end of the string and that comparison operations for the weight level will consider the relative position of elements in the strings not subject to ignore. Refer to Orders and Weights for further information on the ignore value. |
| 10 | Backward/Position - specifies that comparison operations for the weight level proceed from the end of the string towards the beginning of the string and that comparison operations for the weight level will consider the relative position of elements in the strings not subject to ignore. Refer to Orders and Weights for further information on the ignore value. |
The order and weights are returned as an Array(*) of Binary(4). The first element in the array specifies the order for the character or multi-character. The remaining elements are the weights for the character or multi-character. The number of remaining elements is determined by the Number of weights and sort rules field. In other words, the total number of elements in the array is 1 + Number of weights and sort rules. Refer to Single-byte Character Collating Table , Double-byte Character Collating Table or Four-byte Character Collating Table for further information on the how the orders and weights are returned.
Each collating element is assigned a collation value (order) that defines its order in the character collation sequence in the locale. This order is used by regular expressions and pattern matching, and if no collation weight is explicitly defined (Number of weights and sort rules field equals zero), it also serves as the collation weight for sorting.
The collation weights are used when comparing two strings to determine their relative order. The following special values are possible for the weight:
| -1 | Indicates that when strings are compared using weights at the level where the -1 is specified, the collating element is ignored as if the string did not contain the collating element. |
| -2 | Indicates that this collating element is mapped into a string of collating elements. When this value is encountered, the replacement string for the one-to-many mapping is found in the appropriate one-to-many character mapping structure. Refer to One-to-Many Character Mappings for further information on one-to-many mappings. |
The single-byte character collating information is stored within an Array(256) of Binary(4). The Binary(4) elements contain offsets to the order and weights for that collating element. Refer to Orders and Weights for further information on the order and weights.
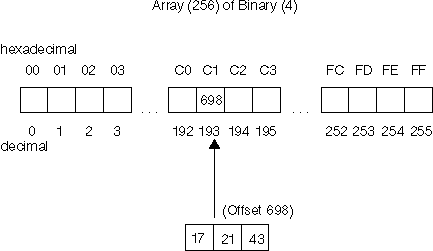
The decimal value for the single-byte code point for the character is used as the subscript to access the collating element array. As illustrated in the example below, if you had a character with a code point of 'C1', you would use the decimal value of this code point as the subscript into the array. The offset of 698 at this subscript is used to gain access to the order and weights for that character. Assuming that the number of weights and sort rules field is set to 2, the example shows that this character has an order of 17 and weights of 21 and 43.
If the offset to the order and weights is set to a value of zero, this indicates that there is no collating value available for that collating element.
The double-byte character collating information is stored within an Array(256) of Binary(4). The Binary(4) elements of this first array contain offsets to a second Array(256) of Binary(4). This second array contains offsets to the order and weights for that collating element. Refer to Orders and Weights for further information on the order and weights.
The double-byte code point for the character is used as the subscripts to access the collating element arrays. The left-most byte of the double-byte character is used to access the first Array(256) of Binary(4). Within the subscripts of the first array are offsets to the second Array(256) of Binary(4). The right-most byte of the double-byte character is used as the subscript to access this second array. Within the subscripts of the second array are offsets to the order and weights for that double-byte character.
As illustrated in the example below, if you had a double-byte character 'D2AE', the decimal value of 'D2' is used as the subscript for the first array. The offset of 636 at this subscript is used to gain access to the second array and the decimal value of 'AE' is used as the subscript for the second array. The offset of 940 is used to gain access to the order and weights. Assuming that the number of weights and sort rules field is set to 2, the example shows that this double-byte character has an order of 41 and weights of 60 and 72.
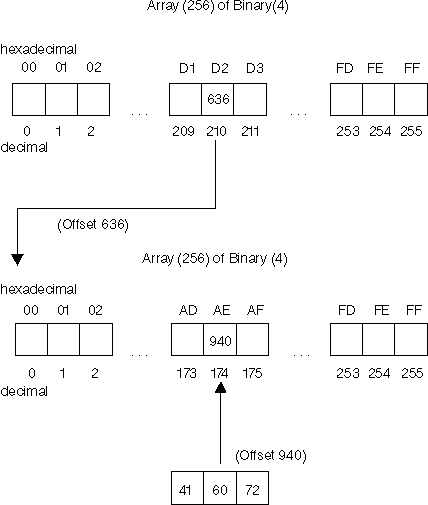
If the offset in the first array is set to zero, this indicates that there are no collating values available for this double-byte character range of collating elements. For example, if you have a double-byte code point 'CDFE' and the offset for the first array is set to zero, this would indicate that all double-byte characters for this locale in the range where the left-most byte was 'CD' have no collating values available. Or, if the offset in the second array is set to zero, this indicates that there are no collating values available for this double-byte collating element. For example, if you have a double-byte code point 'CDFE' and the offset for the first array is not zero, but the offset for the second array is zero, then this indicates that there are no collating values available for this double-byte character.
The four-byte character collating information is stored within an Array(256) of Binary(4). The Binary(4) elements of this first array contain offsets to a second Array(256) of Binary(4). The Binary(4) elements of this second array contain offsets to a third Array(256) of Binary(4). The Binary(4) elements of this third array contain offsets to a fourth Array(256) of Binary(4). This fourth array contains offsets to the order and weights for that collating element. Refer to Orders and Weights for further information on the order and weights.
The four-byte code point for the character is used as the subscripts to access the collating element arrays. The left-most byte of the four-byte character is used to access the first Array(256) of Binary(4). Within the subscripts of the first array are offsets to the second Array(256) of Binary(4). The second left-most byte of the four-byte character is used as the subscript to access this second array. Within the subscripts of the second array are offsets to the third Array(256) of Binary(4). The third left-most byte of the four-byte character is used as the subscript to access this third array. Within the subscripts of the third array are offsets to the fourth Array(256) of Binary(4). The rightmost byte of the four-byte character is used as the subscript to access this fourth array. Within the subscripts of the fourth array are offsets to the order and weights for that four-byte character.
As illustrated in the example below, if you had a four-byte character '0001D15F', the value of '00' is used as the subscript for the first array. The offset of 636 at this subscript is used to gain access to the second array and the value of '01' is used as the subscript for the second array. The offset of A36 at this subscript is used to gain access to the third array and the value of 'D1' is used as the subscript for the third array. The offset of 1236 at this subscript is used to gain access to the fourth array and the value of '5F' is used as the subscript for the fourth array. The offset of 1636 is used to gain access to the order and weights. Assuming that the number of weights and sort rules field is set to 2, the example shows that this four-byte character has an order of 40 and weights of 60 and 72.
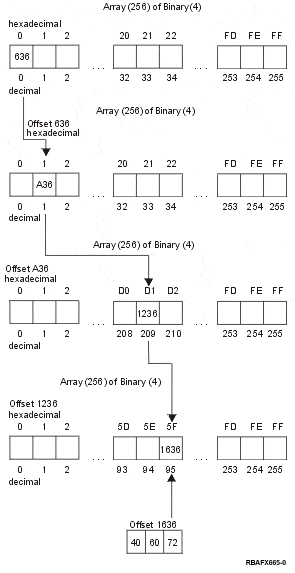
If the offset in the first array is set to zero, this indicates that there are no collating values available for this four-byte character range of collating elements. For example, if you have a four-byte code point '0000CDFE' and the offset for the first array is set to zero, this would indicate that all four-byte characters for this locale in the range where the left-most byte was '00' have no collating values available. Or, if the offset in the second array is set to zero, this indicates that there are no collating values available for this four-byte collating element. For example, if you have a four-byte code point '0000CDFE' and the offset for the first array is not zero, but the offset for the second array is zero, then this indicates that there are no collating values available for this four-byte character. This is also true for the third and fourth arrays.
The multi-character collating elements are returned as a character(*) field. The offset to the first multi-character element returned is the offset provided to the start of this field in the main structure. If the offset to the first multi-character element is zero, then there are no multi-character elements available. All elements are of the following format: (For a detailed description of each field, see Path name format.)
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | Offset to multi-character collating elements. | ||
| BINARY(4) | Length of multi-character collating element. | ||
| BINARY(4) | Offset to order and weights for the multi-character element. Refer to the Orders and Weights for further information on this field.> | ||
| BINARY(4) | Offset to next multi-character collating element structure. | ||
The one-to-many character mappings are returned as a character(*) field. The offset to the first one-to-many mapping element returned is the offset provided to the start of this field in the main structure. If the offset to the first one-to-many mapping element is zero, then there are no one-to-many mapping elements available. All elements are of the following format: (For a detailed description of each field, see Path name format.)
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | Offset to collating element. The length of this field is determined by the type of data. For example, if the type of data is single byte, then the length of the collating element is 1. | ||
| BINARY(4) | Length of replacement string. | ||
| BINARY(4) | Number of replacement strings. | ||
| BINARY(4) | Offset to replacement string. | ||
| BINARY(4) | Offset to next one-to-many character mapping. | ||
The following information is returned for the date and time formatting category. For a detailed description of each field, see Path Name Format.
The date and time formats have conversion specifiers that are used to build the formats. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers and their meaning.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| BINARY(4) | Offset to date and time representation | ||
| BINARY(4) | Length of date and time representation | ||
| BINARY(4) | Offset to date representation | ||
| BINARY(4) | Length of date representation | ||
| BINARY(4) | Offset to time representation | ||
| BINARY(4) | Length of time representation | ||
| BINARY(4) | Offset to ante meridiem and post meridiem representation | ||
| BINARY(4) | Length of ante meridiem and post meridiem representation | ||
| BINARY(4) | Offset to time representation in a 12 hour clock format | ||
| BINARY(4) | Length of time representation in a 12 hour clock format | ||
| BINARY(4) | Offset to abbreviated weekday names | ||
| BINARY(4) | Length of abbreviated weekday names | ||
| BINARY(4) | Offset to full weekday names | ||
| BINARY(4) | Length of full weekday names | ||
| BINARY(4) | Offset to abbreviated month names | ||
| BINARY(4) | Length of abbreviated month names | ||
| BINARY(4) | Offset to full month names | ||
| BINARY(4) | Length of full month names | ||
| BINARY(4) | Offset to era | ||
| BINARY(4) | Length of era | ||
| BINARY(4) | Offset to era date format | ||
| BINARY(4) | Length of era date format | ||
| BINARY(4) | Offset to era time format | ||
| BINARY(4) | Length of era time format | ||
| BINARY(4) | Offset to era date and time format | ||
| BINARY(4) | Length of era date and time format | ||
| BINARY(4) | Offset to alternate digits | ||
| BINARY(4) | Length of alternate digits | ||
| CHAR(*) | Date and time data | ||
The conversion specifiers are used to build the formats for the date and time information. An example for a time format is %H:%M:%S. This time format specifies the hours as a decimal number followed by the minutes as a decimal number and the seconds as a decimal number with the colon (:) as the time separator.
| Specifier | Conversion Specifier Description |
|---|---|
| %a | Abbreviated weekday name |
| %A | Full weekday name |
| %b | Abbreviated month name |
| %B | Full month name |
| %c | Appropriate date and time representation |
| %C | Long format date and time representation |
| %d | Day of the month as a decimal number (01,31) |
| %D | Date in the format %m/%d/%y |
| %e | Day of the month as a decimal number (1,31) in a 2-digit field with leading space character fill |
| %E | Combined alternative era year and name, respectively in %o %N format |
| %h | Abbreviated month name (same as %b) |
| %H | Hour (24-hour clock) as a decimal number (00,23) |
| %I | Hour (12-hour clock) as a decimal number (01,12) |
| %j | Day of the year as a decimal number (001,366) |
| %m | Month as a decimal number (01,12) |
| %M | Minute as a decimal number (00,59) |
| %n | Newline character |
| %N | Alternative era name |
| %o | Alternative era year |
| %O | Alternative digits |
| %p | Ante meridiem (am) or post meridiem (pm) |
| %r | Time in AM/PM notation according to U.K./U.S. conventions in the format %I:%M:%S %p |
| %R | Time in 24 hour notation in the %H:%M format |
| %S | Second as a decimal number (00,61) - the 61 allows for the leap second and double leap second |
| %t | Tab character |
| %T | Time in format %H:%M:%S |
| %U | Week number of the year (Sunday as the first day of the week) as a decimal number (00,53) |
| %w | Weekday (Sunday as the first day of the week) as a decimal number (0,6) |
| %W | Week number of the year (Monday as the first day of the week) as a decimal number (00,53) |
| %x | Appropriate date representation |
| %X | Appropriate time representation |
| %y | Year without a century as a decimal number (00,99) |
| %Y | Year with a century as a decimal number |
| %Z | Timezone name |
The following information is returned for the numeric and non-monetary formatting category. For a detailed description of each field, see Path name format.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| BINARY(4) | Offset to decimal delimiter | ||
| BINARY(4) | Length of decimal delimiter | ||
| BINARY(4) | Offset to thousands separator | ||
| BINARY(4) | Length of thousands separator | ||
| BINARY(4) | Offset to digit grouping | ||
| BINARY(4) | Number of digit groupings | ||
| CHAR(*) | Numeric formatting data | ||
The following information is returned for the affirmative and negative responses category. For a detailed description of each field, see Path name format.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| BINARY(4) | Offset to affirmative response expression | ||
| BINARY(4) | Length of affirmative response expression | ||
| BINARY(4) | Offset to negative response expression | ||
| BINARY(4) | Length of negative response expression | ||
| BINARY(4) | Offset to affirmative response string | ||
| BINARY(4) | Length of affirmative response string | ||
| BINARY(4) | Offset to negative response string | ||
| BINARY(4) | Length of negative response string | ||
| CHAR(*) | Message response data | ||
The following information is returned for the monetary-related numeric formatting category. For a detailed description of each field, see Path name format.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| BINARY(4) | Number of fractional digits for international currency symbol | ||
| BINARY(4) | Number of fractional digits for currency symbol | ||
| BINARY(4) | Currency symbol positioning for monetary non-negative values | ||
| BINARY(4) | Currency symbol positioning for monetary negative values | ||
| BINARY(4) | Currency symbol separator for monetary non-negative values | ||
| BINARY(4) | Currency symbol separator for monetary negative values | ||
| BINARY(4) | Positive sign positioning for monetary non-negative values | ||
| BINARY(4) | Negative sign positioning for monetary negative values | ||
| BINARY(4) | Offset to international currency symbol | ||
| BINARY(4) | Length of international currency symbol | ||
| BINARY(4) | Offset to local currency symbol | ||
| BINARY(4) | Length of local currency symbol | ||
| BINARY(4) | Offset to monetary decimal delimiter | ||
| BINARY(4) | Length of monetary decimal delimiter | ||
| BINARY(4) | Offset to monetary thousands separator | ||
| BINARY(4) | Length of monetary thousands separator | ||
| BINARY(4) | Offset to monetary digit grouping | ||
| BINARY(4) | Number of monetary digit groupings | ||
| BINARY(4) | Offset to monetary positive sign | ||
| BINARY(4) | Length of monetary positive sign | ||
| BINARY(4) | Offset to monetary negative sign | ||
| BINARY(4) | Length of monetary negative sign | ||
| CHAR(*) | Monetary formatting data | ||
The following information is returned for the time zone information category. For a detailed description of each field, see Field Descriptions.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | CCSID of locale data | ||
| BINARY(4) | Locale data type | ||
| Array(4) of BINARY(4) | Start for daylight savings time | ||
| Array(4) of BINARY(4) | End for daylight savings time | ||
| BINARY(4) | Greenwich Mean Time difference | ||
| BINARY(4) | Daylight savings time shift | ||
| BINARY(4) | Offset to time zone name | ||
| BINARY(4) | Length of time zone name | ||
| BINARY(4) | Offset to daylight savings time name | ||
| BINARY(4) | Length of daylight savings time name | ||
| CHAR(*) | Time zone data | ||
All information for all categories is returned in the following format. Refer to the specific locale category formats for details on each locale category. For a detailed description of each field, see Field Descriptions.
If the locale does not have any information defined for a locale category, the offset to the category field is set to zero.
| Offset | Type | Field | |
|---|---|---|---|
| Dec | Hex | ||
| BINARY(4) | Offset to LC_CTYPE category | ||
| BINARY(4) | Offset to LC_COLLATE category | ||
| BINARY(4) | Offset to LC_TIME category | ||
| BINARY(4) | Offset to LC_NUMERIC category | ||
| BINARY(4) | Offset to LC_MESSAGES category | ||
| BINARY(4) | Offset to LC_MONETARY category | ||
| BINARY(4) | Offset to LC_TOD category | ||
| CHAR(*) | Category information | ||
The following section describes the fields returned in further detail.
Bytes available. The number of bytes of data available to be returned. All available data is returned if enough space is provided.
Bytes returned. The number of bytes of data returned.
Category information. The data for all the locale categories. Use the corresponding offsets and lengths to access the data that is included in this field. Refer to each locale category for further information.
CCSID of locale data. The coded character set identifier of the locale information that is returned.
Currency symbol positioning for monetary negative values. Indicates where the local or international currency symbol is positioned for a monetary quantity with a negative value. The possible values are:
| 0 | The currency symbol succeeds the value. |
| 1 | The currency symbol precedes the value. |
Currency symbol positioning for monetary non-negative values. Indicates where the local or international currency symbol is positioned for a monetary quantity with a non-negative value. The possible values are:
| 0 | The currency symbol succeeds the value. |
| 1 | The currency symbol precedes the value. |
Currency symbol separator for monetary negative values. Indicates whether a space separates the local or international currency symbol from the value for a monetary quantity with a negative value. The possible values are:
| 0 | No space separates the currency symbol from the value. |
| 1 | A space separates the currency symbol from the value. |
| 2 | A space separates the currency symbol and the negative sign string, if adjacent. |
Currency symbol separator for monetary non-negative values. Indicates whether a space separates the local or international currency symbol from the value for a monetary quantity with a non-negative value. The possible values are:
| 0 | No space separates the currency symbol from the value. |
| 1 | A space separates the currency symbol from the value. |
| 2 | A space separates the currency symbol and the positive sign string, if adjacent. |
Date and time data. The data for the date and time formatting. This includes the date and time representations, weekday names, month names, era information and alternate digits. This information is returned in the LC_TIME category. Use the corresponding offsets and lengths to get to the data that is included in this field.
Daylight savings time shift. The number of seconds that the locale's time is shifted when Daylight Savings Time takes effect.
End for daylight savings time. The instant when Daylight Savings Time ceases to be in effect. The format for this field is 'month week day time' with each field a Binary(4) value. For example, '0004 0000 0023 0000' sets the end time as April 23 at midnight. The blank spaces between each Binary(4) value is only used here for ease of reading. The actual value returned will not have blanks placed between the Binary(4) values.
Greenwich Mean Time difference. The number of minutes that the locale's time zone is different from Greenwich Mean Time.
Length of abbreviated month names. The length of the abbreviated month names.
Length of abbreviated weekday names. The length of the abbreviated weekday names.
Length of affirmative response expression. The length of the affirmative response expression.
Length of affirmative response string. The length of the affirmative response string.
Length of alternate digits. The length of the alternate digits.
Length of ante meridiem and post meridiem representation. The length of the ante meridiem and post meridiem representation.
Length of category information. The length of the category information. This field is the length of only the first level of the category. For example, if the LC_CTYPE category were specified and the data returned was double-byte, this field would contain a value of 20 (5 Binary(4) fields in the first level of the category). Whereas if the data returned was single-byte, this field would contain a value of 1032 (2 Binary(4), 2 char(256) and 1 Array(256) of unsigned Binary(2) fields in the first level of the category).
Length of date representation. The length of the date representation.
Length of date and time representation. The length of the date and time representation.
Length of daylight savings time name. The length of the daylight savings time name.
Length of decimal delimiter. The length of the decimal delimiter.
Length of era. The length of the era.
Length of era date format. The length of the era date format.
Length of era date and time format. The length of the era date and time format.
Length of era time format. The length of the era time format.
Length of full weekday names. The length of the full weekday names.
Length of full month names. The length of the full month names.
Length of international currency symbol. The length of the international currency symbol.
Length of local currency symbol. The length of the local currency symbol.
Length of monetary decimal delimiter. The length of the monetary decimal delimiter.
Length of monetary negative sign. The length of the monetary negative sign.
Length of monetary positive sign. The length of the monetary positive sign.
Length of monetary thousands separator. The length of the monetary thousands separator.
Length of multi-character collating element. The length of the multi-character collating element in bytes.
Length of negative response expression. The length of the negative response expression.
Length of negative response string. The length of the negative response string.
Length of replacement string. The length of the replacement string for the one-to-many character mapping.
Length of thousands separator. The length of the thousands separator.
Length of time representation. The length of the time representation.
Length of time representation of a 12-hour clock format. The length of the time representation of a 12-hour clock format.
Length of time zone name. The length of the time zone name.
Locale category key. The locale category key specified for the Locale category key to return parameter on the call to the API.
Locale data type. The indicator for the type of data returned from the locale. The possible values are:
| 1 | The data returned is single-byte. |
| 2 | The data returned is double-byte (includes ISO 10646 16-bit character encoding standard (UCS2)). |
| 3 | The data returned is mixed single-byte and double-byte. |
| 4 | The data returned is UTF8 data. |
| 5 | The data returned is UTF32 data. |
Message response data. The data for the affirmative and negative responses. This includes the affirmative and negative response expressions and strings information. This information is returned in the LC_MESSAGES category. Use the corresponding offsets and lengths to access the data that is included in this field.
Monetary formatting data. The data for monetary formatting. This includes the fractional digit, currency symbol positioning, currency symbol separator, positive and negative sign positioning, currency symbol, decimal delimiter, thousands separator, positive and negative sign and digit grouping information. This information is returned in the LC_MONETARY category. Use the corresponding offsets and lengths to access the data that is included in this field.
Negative sign positioning for monetary negative values. An integer representing a value indicating the positioning of the monetary negative sign for a negative formatted monetary quantity. The possible values are:
| 0 | Parentheses enclose the quantity and the local or international currency symbol. |
| 1 | The negative sign string precedes the quantity and local or international currency symbol. |
| 2 | The negative sign string succeeds the quantity and local or international currency symbol. |
| 3 | The negative sign string precedes the local or international currency symbol. |
| 4 | The negative sign string succeeds the local or international currency symbol. |
Number of digit groupings. The number of digit groupings.
Number of fractional digits for currency symbol. An integer representing the number of fractional digits (those to the right of the decimal delimiter) to be written in a formatted monetary quantity using the local currency symbol.
Number of fractional digits for international currency symbol. An integer representing the number of fractional digits (those to the right of the decimal delimiter) to be written in a formatted monetary quantity using the international currency symbol.
Number of monetary digit groupings. The number of monetary digit groupings.
Number of replacement strings. The number of replacement strings.
Number of weights and sort rules. The number of weights and sort rules for character collating. There is one corresponding sort rule for each weight. Refer to Character Collation Sort Rules for further information on the sort rules and Orders and Weights for further information on the weights.
Numeric formatting data. The data for the numeric, non-monetary formatting. This includes the decimal delimiter, thousands separator and digit grouping information. This information is returned in the LC_NUMERIC category. Use the corresponding offsets and lengths to access the data that is included in this field.
Offset to abbreviated month names. Offset to the abbreviated month names. The abbreviated month names consist of twelve quoted strings separated by semicolons. The first string is the abbreviated name of the first month of the year (January), the second the abbreviated name of the second month, and so on. The conversion specifier for this field is %b. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to abbreviated weekday names. Offset to the abbreviated weekday names. The abbreviated weekday names consist of seven quoted strings separated by semicolons. The first string is the abbreviated name of the day corresponding to Sunday, the second is the abbreviated name of the day corresponding to Monday, and so on. The conversion specifier for this field is %a. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to affirmative response expression. Offset to the quoted string of an extended regular expression that describes the acceptable affirmative response to a question expecting an affirmative or negative response.
Offset to affirmative response string. Offset to the quoted string that describes an acceptable affirmative response.
Offset to alternative digits. Offset to the alternative digits. The alternative digits is a group of quoted strings separated by semicolons. The first string represents the alternate string for zero, the second string represents the alternate string for one, and so on. A maximum of 100 alternate strings can be returned. The conversion specifier is %O. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to ante meridiem and post meridiem representation. Offset to the ante meridiem (am) and post meridiem (pm) representation. The ante meridiem (before noon) and post meridiem (after noon) representation consists of two quoted strings separated by a semicolon. The first string represents the ante meridiem designation and the second string represents the post meridiem designation. The conversion specifier for this field is %p. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to category information. Offset to the start of the category information returned.
Offset to collating element. Offset to the collating element that has a one-to-many mapping. The length of this field is determined by the type of data that is being returned. For example, if the type of data is single-byte, then the length of this field would be 1 byte.
Offset to date representation. Offset to the date representation. The date representation consists of a quoted string and can contain any combination of characters and field descriptors that represent the date. The conversion specifier for this field is %x. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to date and time representation. Offset to the date and time representation. The date and time representation consists of a quoted string and can contain any combination of characters and field descriptors that represent the date and time. The conversion specifier for this field is %c. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to daylight savings time name. Offset to the quoted string of characters that represent the time zone when Daylight Savings Time is in effect.
Offset to decimal delimiter. Offset to the quoted string containing a symbol that is used as the decimal delimiter (radix character) in numeric, non-monetary formatted quantities.
Offset to digit grouping. Offset to the digit grouping. The digit grouping defines the size of each group of digits in formatted non-monetary quantities. This field consists of a sequence of integers. Each integer specifies the number of digits in each group, with the initial integer defining the size of the group immediately preceding the decimal delimiter. The following integers define the preceding groups. When the last integer is not -1, then the size of the previous group (if any) is used repeatedly for the remainder of the digits. When the last integer is -1, then no further grouping is performed. The number of integers in the sequence is determined by the Number of digit groupings field.
Offset to double-byte character classification. Offset to the character classification for a double-byte character. This information indicates what classifications a character has, for example if the character is a control character. Refer to the Double-Byte Character Classification Structure for further information on this field.
Offset to double-byte character collating table. Offset to the double-byte character collating table. Refer to the Double-byte Character Collating Table for further information on this field.
Offset to double-byte lowercase conversion mapping. Offset to the lowercase conversion mapping for a double-byte character. This mapping is used to find the lowercase character for the corresponding uppercase character. Refer to the Double-Byte Conversion Mapping Structures for further information on this field.
Offset to double-byte one-to-many character mappings. Offset to the double-byte one-to-many character mappings. Refer to the One-to-Many Character Mappings for further information on this field.
Offset to double-byte uppercase conversion mapping. Offset to the uppercase conversion mapping for a double-byte character. This mapping is used to find the uppercase character for the corresponding lowercase character. Refer to the Double-Byte Conversion Mapping Structures for further information on this field.
Offset to era. Offset to the era. The era defines how the years are counted and displayed for each era, corresponding to the %E conversion specifier. The era consists of a quoted string in the format: "direction:offset:start_date:end_date:era_name:". If more than one era is defined, each quoted string for each era is separated by a semicolon. Each element of the era format is defined as:
| direction | Specifies a - (minus sign) or a + (plus sign) character. The plus character indicates that years count in the positive direction when moving from the start date to the end date. The minus character indicates that years count in the negative direction when moving from the start date to the end date. |
| offset | Specifies a number representing the first year of the era. |
| start_date | Specifies the starting date of the era in the yyyy/mm/dd format, where yyyy, mm and dd are the year, month and day, respectively. Years prior to the year AD 1 are represented as negative numbers. |
| end_date | Specifies the ending date of the era in the same form used for the start_date variable or one of the two special values -* or +*. A -* value indicates that the ending date of the era extends backward to the beginning of time. A +* value indicates that the ending date of the era extends forward to the end of time. |
| era_name | Specifies a string representing the name of the era. The conversion specifier is %EC. |
| era_format | Specifies a string for formatting the year in the era. The conversion specifier is %EY. |
Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to era date format. Offset to the era date format. The era date format is a quoted string that defines the string used to represent the date in the alternate-era format. The conversion specifier is %Ex. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to era date and time format. Offset to the era date and time format. The era date and time format is a quoted string that defines the string used to represent the date and time in the alternate-era format. The conversion specifier is %Ec. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to era time format. Offset to the era time format. The era time format is a quoted string that defines the string used to represent the time in the alternate-era format. The conversion specifier is %EX. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to four-byte character classification. Offset to the character classification for a four-byte character. This information indicates what classifications a character has, for example if the character is a control character. Refer to the Four-Byte Character Classification Structure for further information on this field.
Offset to four-byte character collating table. Offset to the four-byte character collating table. Refer to the Four-byte Character Collating Table for further information on this field.
Offset to four-byte lowercase conversion mapping. Offset to the lowercase conversion mapping for a four-byte character. This mapping is used to find the lowercase character for the corresponding uppercase character. Refer to the Four-Byte Conversion Mapping Structures for further information on this field.
Offset to four-byte one-to-many character mappings. Offset to the four-byte one-to-many character mappings. Refer to the One-to-Many Character Mappings for further information on this field.
Offset to four-byte uppercase conversion mapping. Offset to the uppercase conversion mapping for a four-byte character. This mapping is used to find the uppercase character for the corresponding lowercase character. Refer to the Four-Byte Conversion Mapping Structures for further information on this field.
Offset to full month names. Offset to the full month names. The full month names consists of twelve quoted strings separated by semicolons. The first string is the full name of the first month of the year (January), the second the full name of the second month, and so on. The conversion specifier for this field is %B. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to full weekday names. Offset to the full weekday names. The full weekday names consists of seven quoted strings separated by semicolons. The first string is the full name of the day corresponding to Sunday, the second is the full name of the day corresponding to Monday, and so on. The conversion specifier for this field is %A. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to international currency symbol. Offset to the international currency symbol. The international currency symbol consists of a four character quoted string that denotes the symbol used for international monetary quantities. The first three characters contain the alphabetic international currency symbol. The fourth character is the character used to separate the international currency symbol from the monetary quantity.
Offset to LC_COLLATE category. Offset to the start of the character collation information.
Offset to LC_CTYPE category. Offset to the start of the character classification and conversion information.
Offset to LC_MESSAGES category. Offset to the start of the affirmative and negative responses information.
Offset to LC_MONETARY category. Offset to the start of the monetary related numeric formatting information.
Offset to LC_NUMERIC category. Offset to the start of the numeric and non-monetary formatting information.
Offset to LC_TIME category. Offset to the start of the date and time formatting information.
Offset to LC_TOD category. Offset to the start of the time zone information.
Offset to local currency symbol. Offset to the quoted string that denotes the symbol used for local monetary quantities.
Offset to monetary decimal delimiter. Offset to the quoted string containing a symbol that is used as the decimal delimiter (radix character) in monetary formatted quantities.
Offset to monetary digit grouping. Offset to the monetary digit grouping. The monetary digit grouping defines the size of each group of digits in formatted monetary quantities. This field consists of a sequence of integers. Each integer specifies the number of digits in each group, with the initial integer defining the size of the group immediately preceding the decimal delimiter. The following integers define the preceding groups. When the last integer is not -1 then the size of the previous group (if any) is used repeatedly for the remainder of the digits. When the last integer is -1 no further grouping is performed. The number of integers in the sequence is determined by the Number of monetary digits groupings field.
Offset to monetary negative sign. Offset to the quoted string used to indicate a negative-valued formatted monetary quantity.
Offset to monetary positive sign. Offset to the quoted string used to indicate a non-negative-valued formatted monetary quantity.
Offset to monetary thousands separator. Offset to the quoted string containing the symbol that is used as a separator for groups of digits to the left of the decimal delimiter in formatted monetary quantities.
Offset to multi-character collating element. Offset to the multi-character collating element. The multi-character collating element is a sequence of two or more characters to be collated as an entity.
Offset to multi-character collating elements. Offset to the multi-character collating elements. Refer to the Multi-Character Collating Elements for further information on this field.
Offset to negative response expression. Offset to the quoted string of an extended regular expression that describes the acceptable negative response to a question expecting an affirmative or negative response.
Offset to negative response string. Offset to the quoted string that describes an acceptable negative response.
Offset to next multi-character collating element. Offset to the next multi-character collating element. A value of zero in this field denotes the end of the list of multi-character collating elements.
Offset to next one-to-many character mapping. Offset to the next one-to-many character mapping. A value of zero in this field denotes the end of the list of one-to-many character mappings.
Offset to order and weights for the multi-character element. Offset to the order and weights for the multi-character collating element. Refer to the Orders and Weights for further information on this field.
Offset to replacement string. Offset to the replacement string for a one-to-many mapping of a collating element. The replacement string is comprised of one or more quoted strings separated by semicolons. The number of replacement strings is determined by the number of replacement strings field.
Offset to single-byte character collating table. Offset to the single-byte character collating table. Refer to the Single-byte Character Collating Table for further information on this field.
Offset to single-byte one-to-many character mappings. Offset to the single-byte one-to-many character mappings. Refer to the One-to-Many Character Mappings for further information on this field.
Offset to sort rules. Offset to the sort rules for character collation. These rules are applied when comparing single or multi-character collating elements. Refer to the Character Collation Sort Rules for further information on this field.
Offset to thousands separator. Offset to a quoted string containing a symbol that is used as the decimal separator for groups of digits to the left of the decimal delimiter in numeric, non-monetary formatted quantities.
Offset to time representation. Offset to the time representation. The time representation consists of a quoted string and can contain any combination of characters and field descriptors that represent the time. The conversion specifier for this field is %X. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to time representation of a 12-hour clock format. Offset to the time representation of a 12-hour clock format. The time representation of a 12-hour clock format consists of a quoted string and can contain any combination of characters and field descriptors. The conversion specifier for this field is %r. Refer to Date and Time Conversion Specifiers for the list of conversion specifiers.
Offset to time zone name. Offset to the quoted string of characters that represent the time zone name.
Positive sign positioning for monetary non-negative values. An integer set to a value indicating the positioning of the monetary positive sign for a monetary quantity with a non-negative value. The possible values are:
| 0 | Parentheses enclose the quantity and the local or international currency symbol. |
| 1 | The positive sign string precedes the quantity and local or international currency symbol. |
| 2 | The positive sign string succeeds the quantity and local or international currency symbol. |
| 3 | The positive sign string precedes the local or international currency symbol. |
| 4 | The positive sign string succeeds the local or international currency symbol. |
Reserved. An ignored field.
Single-byte character classification. The character classification for a single-byte character. This information indicates what classifications a character has, for example if the character is a control character. Refer to the Single-Byte Character Classification Structure for further information on this field.
Single-byte lowercase conversion mapping. The lowercase conversion mapping for a single-byte character. This mapping is used to find the lowercase character for the corresponding uppercase character. Refer to the Single-Byte Conversion Mapping Structures for further information on this field.
Single-byte uppercase conversion mapping. The uppercase conversion mapping for a single-byte character. This mapping is used to find the uppercase character for the corresponding lowercase character. Refer to the Single-Byte Conversion Mapping Structures for further information on this field.
Start for daylight savings time. The instant when Daylight Savings Time comes into effect. The format for this field is 'month week day time' with each field a Binary(4) value. For example, '0010 0003 0006 0000' sets the start time as the 3rd week of October at midnight on Saturday. The blank spaces between each Binary(4) value is only used here for ease of reading. The actual value returned will not have blanks placed between the Binary(4) values.
Time zone data. The data for the time zone information. This includes daylight savings time, Greenwich Mean Time, and time zone information. This information is returned in the LC_TOD category. Use the corresponding offsets and lengths to access the data that is included in this field.
| Message ID | Error Message Text |
|---|---|
| CPFA0AB E | Object name not a directory. |
| CPFA0A2 E | Information passed to this operation was not valid. |
| CPFA0A3 E | Path name resolution causes looping. |
| CPFA0A7 E | Path name too long. |
| CPFA0A9 E | Object not found. |
| CPFA0C1 E | CCSID &1 not valid. |
| CPFA09C E | Not authorized to object. |
| CPFA09E E | Object in use. |
| CPFA09F E | Object damaged. |
| CPFA092 E | Path name not converted. |
| CPF24B4 E | Severe error while addressing parameter list. |
| CPF3BED E | Requested function cannot be performed at this time. |
| CPF3BEF E | C or POSIX locale specified in the environment variable. |
| CPF3BF1 E | Locale &1 does not exist. |
| CPF3BF2 E | Locale &1 is not a valid locale. |
| CPF3BF3 E | Locale not defined in environment variable. |
| CPF3CF1 E | Error code parameter not valid. |
| CPF3CF2 E | Error(s) occurred during running of &1 API. |
| CPF3C19 E | Error occurred with receiver variable specified. |
| CPF3C1E E | Required parameter &1 omitted. |
| CPF3C21 E | Format name &1 is not valid. |
| CPF3C24 E | Length of the receiver variable is not valid. |
| CPF3C36 E | Number of parameters, &1, entered for this API was not valid. |
| CPF3C82 E | Key &1 not valid for API &2. |
| CPF3C90 E | Literal value cannot be changed. |
| CPF8100 E | All CPF81xx messages could be returned. xx is from 01 to FF. |
| CPF9872 E | Program or service program &1 in library &2 ended. Reason code &3. |
[ Back to top | National Language Support APIs | APIs by category ]