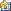By default the Row Generator stage runs sequentially, generating data in a single partition. You can, however, configure it to run in parallel, and you can use the partition number when you are generating data to, for example, increment a value by the number of partitions. You will also get the Number of Records you specify in each partition (so in the example where you have asked for 100 records, you will get 100 records in each partition rather than 100 records divided between the number of partitions).
In this example you are generating a data set comprising two integers. One is generated by cycling, one by random number generation.
The cycling integer's initial value is set to the partition number (using the special value `part') and its increment is set to the number of partitions (using the special value `partcount'). This is set in the Edit Column Meta Data dialog box as follows (select column in Columns tab and choose Edit Row... from shortcut menu):

The random integer's seed value is set to the partition number, and the limit to the total number of partitions.
| integer1 | integer2 |
|---|---|
| 0 | 1 |
| 4 | 2 |
| 8 | 3 |
| 12 | 2 |
| 16 | 3 |
| 20 | 1 |
| 24 | 2 |
| 28 | 3 |
| 32 | 3 |
| 36 | 1 |
| 40 | 0 |
| 44 | 3 |
| 48 | 3 |
| 52 | 2 |
| 56 | 0 |
| 60 | 0 |
| 64 | 1 |
| 68 | 3 |
| 72 | 2 |
| 76 | 2 |
| 80 | 0 |
| 84 | 1 |
| ... | ... |
 This topic is also in the IBM InfoSphere DataStage and QualityStage Parallel Job Developer's Guide.
This topic is also in the IBM InfoSphere DataStage and QualityStage Parallel Job Developer's Guide.