Preparing to load master data in virtual MDM with the MDM Workbench
You use the MDM Workbench to set up your initial data load.
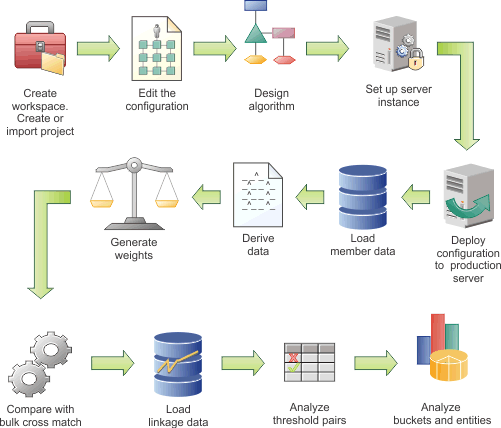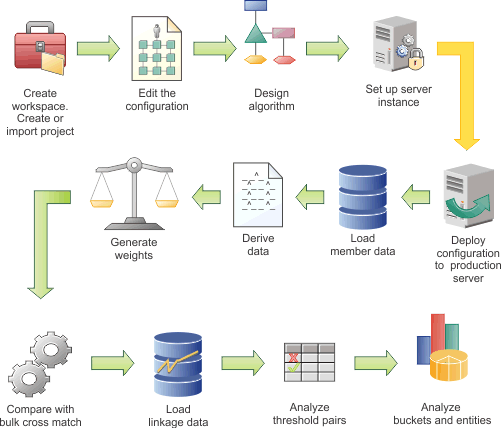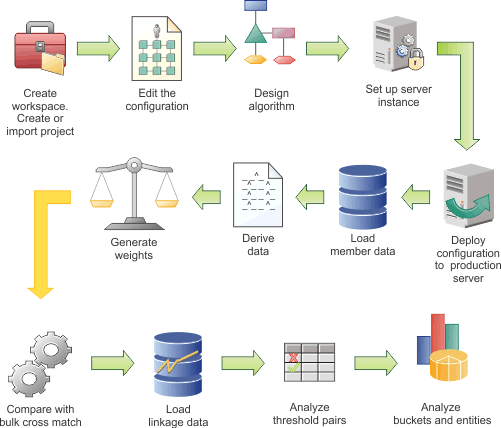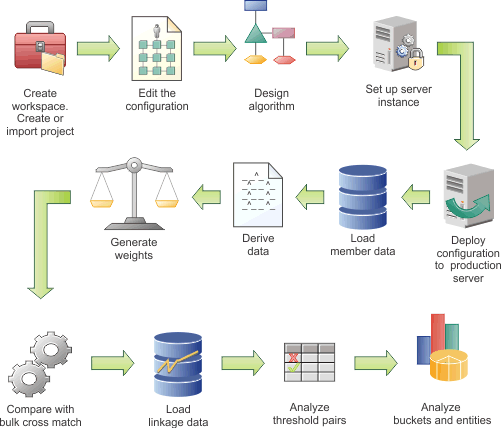
In the following diagram, the example workflow shows the high-level tasks for configuring the data load. Some tasks are iterative and are repeated until you achieve the results that you require. The diagram is provided only as an example. Your team might use a different work flow. In addition, the diagram implies that each task follows sequentially, whereas in reality tasks might be performed simultaneously.
Hover and click the icons, or replay the animation.
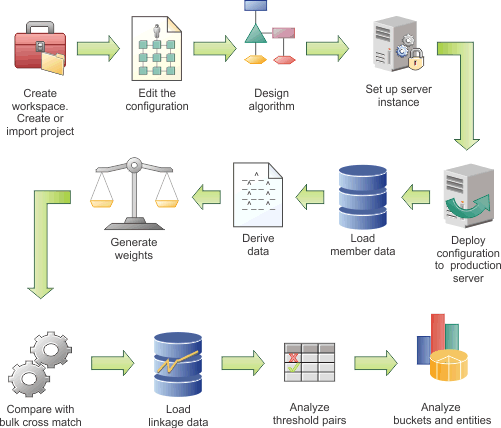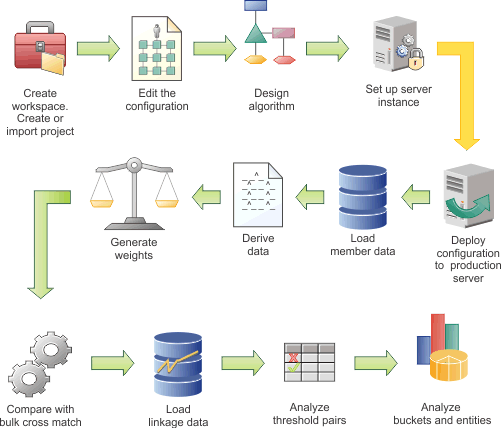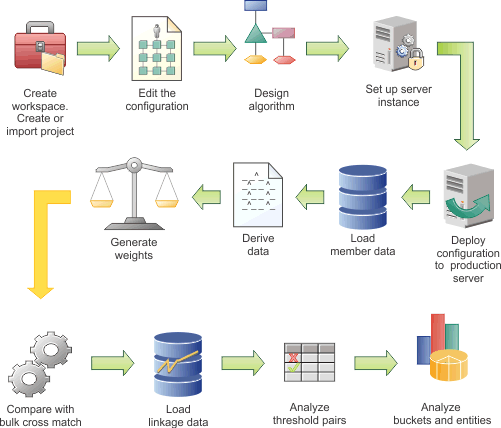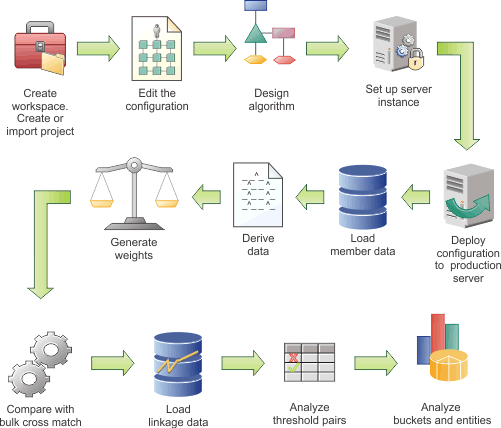{kind=link}
- Introduction to the InfoSphere MDM Workbench
The InfoSphere MDM Workbench application enables implementers and administrators to easily manage the operational server. Use this application to manage algorithms, create composite views, edit dictionary data tables, and to develop member logical models, flows, and mappings to data sources. - Overview of how OSGi changes to the MDM Workbench impact virtual MDM configurations
Version 11 of InfoSphere MDM introduces a modular OSGi framework to the development and deployment of the InfoSphere MDM application. - Managing configuration projects
In InfoSphere MDM Workbench, a configuration project is a container that holds the operational server configuration and its associated files. You can add servers in the Servers view. - Jobs and job sets
A job is a task or utility performed by the operational server. Job sets are groupings of one or more jobs. - Configuration editor
Use the Configuration editor to define and manage configuration settings. The options available differ depending on whether you are using the Basic or Expert editor view. - Algorithms
The algorithm is the brain of certain configurations in the InfoSphere MDM software, therefore, the proper data elements must be in place before you can fully develop the algorithm. - Weight generation
The operational server enables you to generate weights for attributes associated with a particular entity type by setting values on the InfoSphere MDM Workbench Algorithm view and then running a job set which includes the Generate Weights utility. - Analytics
InfoSphere MDM Workbench 11.4 provides a set of analysis tools for analyzing various aspects of the configuration, such as buckets and entities. - Overview of handlers
Handlers are code extensions that enable notifications or API calls to be sent from the InfoSphere MDM to external systems when certain events (such as entity linking or unlinking, member attribute updates, or member searches) occur within the operational server. - Address standardization with IBM InfoSphere QualityStage
You can standardize addresses in your virtual MDM configuration by using IBM® InfoSphere QualityStage®. The address standardization features that are provided by InfoSphere QualityStage ensure that your address data is in a uniform structure to meet your business standards. - Source Sequence Identifiers
Currently, this view contains only one tab, Source Sequence Identifiers. - InfoSphere MDM Pair Manager
As part of the weight generation process, you ran the Generate Threshold Analysis Pairs job to create one or more .xls files containing pairs of members. - InfoSphere MDM Inspector Configuration
Use the InfoSphere MDM Inspector configuration editor in InfoSphere MDM Workbench to define and manage your custom InfoSphere MDM Inspector configuration. - Master Data Policy Monitoring
You can use the InfoSphere MDM to set the configuration properties that are required to use policy monitoring. - Weight table names
InfoSphere MDM uses a number of database tables to manage weights used for comparison and scoring. The name given to these tables represent the weight type associated with the table. - Globalization
InfoSphere MDM Workbench can be viewed in alternate languages. - Creating cheat sheets for Workbench tools
As an Eclipse-based application, MDM Workbench supports the use of cheat sheets. - MPXDATA configuration file
The mpxdata configuration file is used as a map for reading the customer extract file and as a legend for converting the data to the InfoSphere MDM database table layout. The configuration file is used by the Derive Data and Create UNLs (mpxdata) job, the mpxdata.exe utility, and when you use InfoSphere DataStage® jobs in MpxData mode. - Domain templates
A domain template is a pre-configured bundle of sample data, weights, an algorithm, and a configuration file. Domain templates provide a sample project that is easy to implement. The project can be used for training or demonstration purposes, and can also be used as a starting point for a production implementation.
Last updated: 27 Jun 2018