Delimited message format for Event Publishing
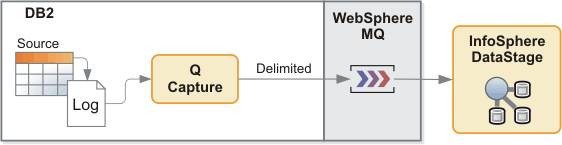
The delimited message format for Event Publishing provides a structure for source table changes that is similar to delimited sequential files, but with the high throughput advantage of IBM® MQ queues.
Changes to DB2® tables are read from the recovery log and transformed into MQ messages that use delimiters to separate the column data, records, and other information.
The default delimiter format is compatible with comma-separated value (CSV) format. So, for example, you can use InfoSphere® DataStage® to read the messages from queues and process CSV messages for feeding a data warehouse.
The delimited message format for Event Publishing includes the following features:
- You can specify that each message contains a single row operation (INSERT, UPDATE, or DELETE), or an entire transaction.
- Large-object data is supported.
- Delimited data can be published in a code page that you specify.
- You can specify your own delimiters for separating column data, character string data, records, and the fractional portion of decimal numbers.
- Event Publishing allows you to filter data at the row level by using a WHERE clause.
The following sections provide more detail about the delimited message format:
- Characteristics of delimited messages
- Specifying delimiters
- Specifying code pages for messages
- Large-object (LOB) data
Characteristics of delimited messages
Delimited messages are comprised of one or more change-data records. Each change-data record contains a header and the results of a row operation at the source table.
For example, the following change-data record contains an INSERT operation for a source table TEST.EMPLOYEE. The table has the following columns: First Name, Last Name, Position, Department, Salary, and Commission:
- DB2 for z/OS V10 with replication V10.2.1
10,"IBM","2006030","182318000005","TEST","EMPLOYEE","ISRT", "0000:0000:0388:4642:0000","0000:0000:0000:0271:000c:0000:0000", "2006-06-30-18.00.52","ASNQC910",0000, ,,,,,,"John","Doe","MGR","SALES",120000,12000- DB2 for z/OS V11 with replication V10.2.1
10,"IBM","2006030","182318000005","TEST","EMPLOYEE","ISRT", "0000:0000:0388:4642:0000:0000","0000:0000:0000:0271:000c:0000:0000", "2006-06-30-18.00.52","ASNQC910",0000, ,,,,,,"John","Doe","MGR","SALES",120000,12000
The example uses commas (,) for column delimiters, and double quotation marks (") to surround character string data. The first 12 positions of the change-data record are the header and describe the source table, sending time, and other information. The actual column data from the source table begins in the 13th position, in this example ,,,,,,"John". (Because this is an INSERT operation, the six commas before "John" signify null before values for the six columns in TEST.EMPLOYEE.)
The following list describes other characteristics of delimited messages that are used in Event Publishing:
- Change-data records always include both before and after values. The before values for an INSERT are always null, and the after values for a DELETE are always null. The BEFORE_VALUES field in the IBMQREP_SUBS table must be set to Y. The before values for LOB columns are always NULL.
- All of the columns are published for all subscribed rows. The CHANGED_COLS_ONLY column in the IBMQREP_SUBS table must be set to N.
- The columns for a change-data record are ordered by column ID, not by the order from the IBMQREP_SRC_COLS table. On z/OS, the column ID comes from the COLNO column of the SYSIBM.SYSCOLUMNS system catalog table.
- A single change-data record cannot be larger than the MAX_MESSAGE_SIZE attribute of the publishing queue map. If transactions are larger than the maximum messages size, the transaction is segmented into multiple messages.
- The Q Capture program does not send heartbeat messages, schema messages, or control messages with delimited format.
Specifying delimiters
If you choose to specify your own delimiters, each of the four delimiter types (column, record, string, and decimal) must be different, and no alphanumeric characters (0 to 9 or Aa to Zz) or double-byte characters are allowed.
When you specify a delimiter, you can type a single character or use a hexadecimal value that represents the character. The following table shows the default delimiters and their hexadecimal values in EBCDIC and ASCII.
| Delimiter type | Character | EBCDIC hex value | ASCII hex value |
|---|---|---|---|
| Column | Comma (,) | X'6B' | X'2C' |
| Character string | Double quotation mark (") | X'7F' | X'22' |
| Change-data record | New line character | X'25' | X'0A' |
| Decimal point | Period (.) | X'4B' | X'2E' |
Specifying code pages for messages
By default, the Q Capture program writes delimited messages in Unicode (code page 1208). You can specify that messages be written in a different code page when you use the Replication Center to create the publishing queue map for the messages. The code page is stored in the MESSAGE_CODEPAGE field of the IBMQREP_SENDQUEUES control table.
Large-object (LOB) data
You can publish LOB data in delimited format. Character large object (CLOB), double-byte character large object (DBCLOB, Oracle NCLOB), and binary large object (BLOB) data is represented by character strings that are enclosed by string delimiters. BLOB column values are converted to hexadecimal-encoded character strings.
For example, the following character string is a hex encoding for the integer 1024: “0400”