 z/OS DFSMS Using Data Sets
z/OS DFSMS Using Data Sets
z/OS DFSMS Using Data Sets
z/OS DFSMS Using Data Sets
|
Previous topic |
Next topic |
Contents |
Contact z/OS |
Library |
PDF
Organizing Data Sets z/OS DFSMS Using Data Sets SC23-6855-00 |
|
|
The organization of an indexed sequential data set allows you much flexibility in the operations you can perform. The data set can be read or written sequentially, individual records can be processed in any order, records can be deleted, and new records can be added. The system automatically locates the proper position in the data set for new records and makes any necessary adjustments when records are deleted. The records in an indexed sequential data set are arranged according to collating sequence by a key field in each record. Each block of records is preceded by a key field that corresponds to the key of the last record in the block. An indexed sequential data set resides on direct access storage
devices and can occupy as many as three different areas:
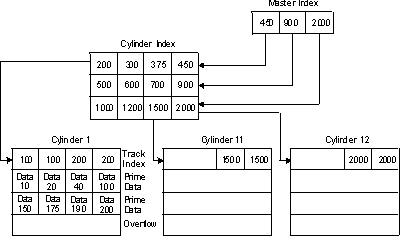
The track indexes of an indexed sequential data set are similar to the card catalog in a library. For example, if you know the name of the book or the author, you can look in the card catalog and obtain a catalog number that enables you to locate the book in the book files. You then go to the shelves and go through rows until you find the shelf containing the book. Then you look at the individual book numbers on that shelf until you find the particular book. ISAM uses the track indexes in much the same way to locate records in an indexed sequential data set. As the records are written in the prime area of the data set, the system accounts for the records contained on each track in a track index area. Each entry in the track index identifies the key of the last record on each track. There is a track index for each cylinder in the data set. If more than one cylinder is used, the system develops a higher-level index called a cylinder index. Each entry in the cylinder index identifies the key of the last record in the cylinder. To increase the speed of searching the cylinder index, you can request that a master index be developed for a specified number of cylinders, as shown in Figure 1. Rather than reorganize the entire data set when records are added, you can request that space be allocated for additional records in an overflow area. Figure 1. Indexed Sequential Data Set Organization

|
 Copyright IBM Corporation 1990, 2014 Copyright IBM Corporation 1990, 2014 |