z/OS DFSORT: Getting Started
z/OS DFSORT: Getting Started
z/OS DFSORT: Getting Started
z/OS DFSORT: Getting Started
|
Previous topic |
Next topic |
Contents |
Contact z/OS |
Library |
PDF
Selecting records by field occurrences z/OS DFSORT: Getting Started SC23-6880-00 |
|||||||||
|
You can use ICETOOL's SELECT operator to create an output data set with records selected according to how many times different ON field values occur, sorted by those ON field values. As with the OCCUR operator, values that occur only once are called non-duplicate values, and values that occur more than once are called duplicate values. You can use up to 10 ON fields; all of the ON field values are used for sorting and counting occurrences. For example, if you use ON(1,4,CH), 'ABCD+01' and 'ABCD-01' are sorted in that order (by 1,4,CH,A) and counted two occurrences of ('ABCD'). However, if you use ON(1,4,CH) and ON(5,3,FS), 'ABCD-01' is sorted before 'ABCD+01' (by 1,4,CH,A and 5,3,FS,A) and counted as one occurrence of 'ABCD-01' and one occurrence of 'ABCD+01'. You can select different combinations
of records with duplicate
and non-duplicate values using the following operands:
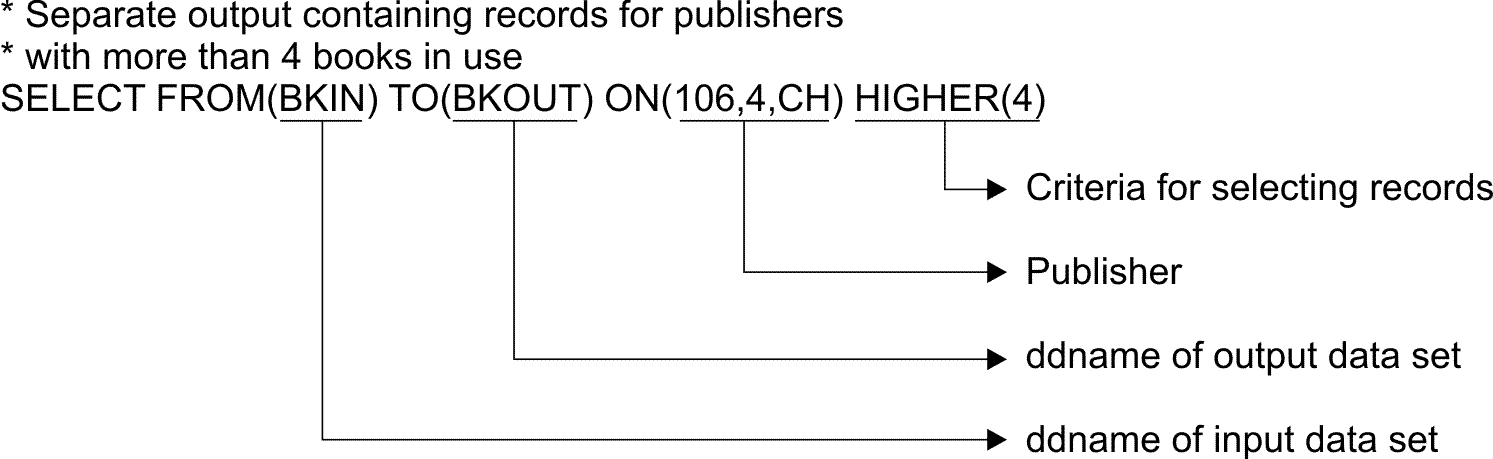
The selected records are written to the output data set identified by the TO operand. If appropriate, you can use the DISCARD operand with any of the other operands shown previously to save the records that are not selected in a separate output data set identified by the DISCARD operand. You can create just the TO data set, just the DISCARD data set, or both. You can use a USING data set to specify DFSORT INCLUDE, OMIT, INREC, and OUTFIL statements for your SELECT operation. INCLUDE or OMIT and INREC statement processing is performed before SELECT processing. OUTFIL statement processing is performed after SELECT processing. To create an output data set containing records for publishers
with more than four different books in use, write the following SELECT
statement: BKIN is the ddname for the sample bookstore data set. BKOUT is the ddname of the output data set that will contain the records for each publisher field value that occurs more than 4 times (all of the records for COR and VALD in this case). Write a DD statement for the A123456.BOOKS1 data sets and place it at the end of the job: Table 1 shows
the Book Title and Publisher
fields for the records in the resulting output data set. The actual
records contain all of the fields.
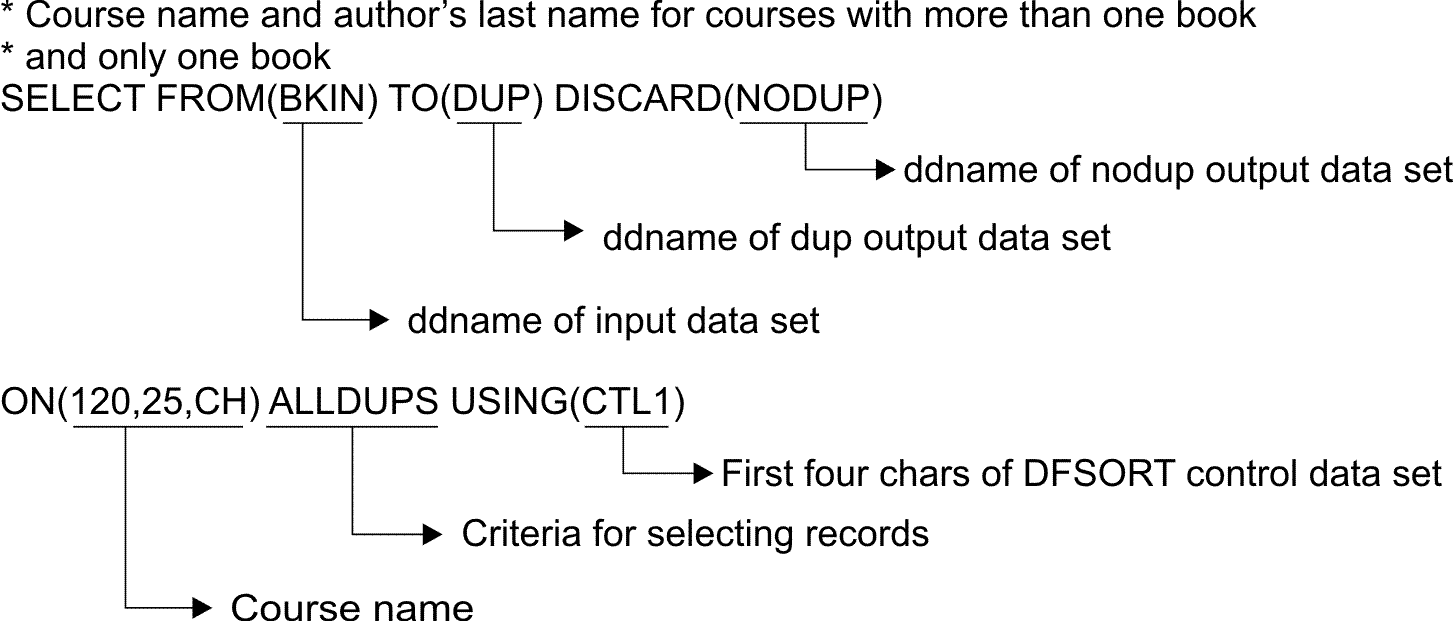
To create
separate output data sets containing records with only
the course name and author's last name, both for courses that use
more than one book, and for courses that use only one book, write
the following SELECT statement: BKIN is the ddname for the sample bookstore data set. DUP is the ddname of the output data set to contain the records for courses with more than one book. NODUP is the ddname of the output data set to contain the records for courses with only one book. Here is
the complete JCL for the job, including control statements:
The OMIT statement removes records with a blank course name before SELECT processing. The OUTFIL statement for DUP reformats the selected records for courses with more than one book to have just the course name and author's last name. The OUTFIL statement for NODUP reformats the selected records for courses with only one book to have just the course name and author's last name. Here are the DUP records
exactly as they would appear:
Here are the
NODUP records exactly as they would appear:
Note that "TECHINCAL EDITING" and "TECHNICAL EDITING" are both included in the NODUP data set because they are different ("TECHINCAL" is spelled incorrectly). Suppose you want to use
the SORT.BRANCH data set
to display the three branches in each state with the highest number
of employees. Write the following ICETOOL statement:
Include the following DFSORT statements in HIGHCNTL:
The
SORT statement orders the records ascending by
state and descending by number of employees. This brings the records
for each state with the highest number of employees to the top. The
intermediate result would be:
The FIRST(3) operand tells SELECT to keep the first 3 records for each ON field (the state). Finally, the OUTFIL statement extracts the state and employees values from the selected records. The output records would look like this:


|
 Copyright IBM Corporation 1990, 2014 Copyright IBM Corporation 1990, 2014 |