Informix Warehouse Accelerator internal architecture
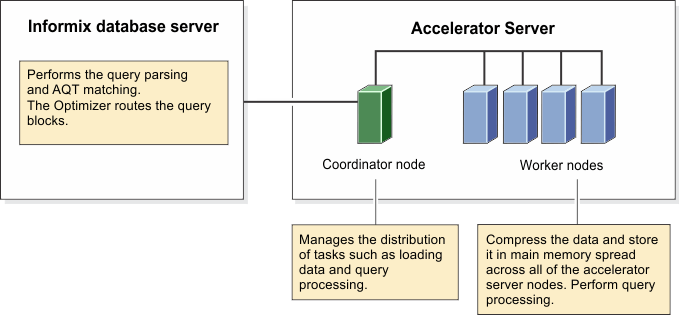
The accelerator server consists of two or more nodes, which are processes that run in the Linux operating system.
The nodes use main memory and disk space. By default, the accelerator server has one coordinator node and one worker node. The main memory is divided into shared memory for the coordinator node, shared memory for the worker node, and private memory that is used by the processes and their threads on an as-needed basis.
The coordinator node manages the requests from the database server such as loading data and running queries. The database server and the ondwa utility connect to the coordinator node. The coordinator node communicates with the worker node. The worker node has all of the data in main memory in a compressed format and processes the queries. You can configure more worker nodes to obtain higher parallelism for certain environments.
The processes are multithreaded so parallelization is in effect even when there is only one coordinator and one worker node. You use the ondwa utility to start the accelerator server nodes.
 Release date: March 2015
Release date: March 2015