Backing up data
A backup system for disaster recovery is a copy of the production environment. The goal of any disaster recovery system is to create a mirror image of the data from the primary data center in a secondary data center. There are several ways to manage a backup system. Each method imposes some constraints on the production environment, and each presents some advantages and disadvantages.
When you are thinking about disaster recovery, focus on this question: "What is the best way to build a disaster recovery solution for the organization’s business process applications?" Base your infrastructure design decisions on the real needs of your business. Before you start to consider how you want to configure a disaster recovery system, make sure that you clearly define your priorities.
- Managed by the operating system
- You can use the operating system to manage the data replication.
Operating system techniques rely on capabilities that are provided
by the operating system to copy data from one location to another.
The operating system approach captures the state of a running production
system at a specific point in time.
This system is simple to set up if you are just backing up a single server. If you are backing up a distributed production environment, you must set up a shared file system, such as the network file system (NFS) on UNIX.
- Managed by a storage area network (SAN)
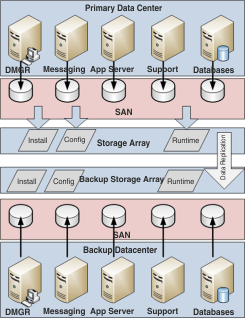
- A storage system such as storage area network (SAN) can be used
to provide a central repository of production environment data. The
picture shows a typical system in which the deployment manager, messaging
engine, application server, support, and database data are all mirrored
on a backup system through a storage area network.
 Managed by the database
Managed by the database- Databases that are designed for enterprise use have features that support high availability scenarios. You can use those features to manage runtime resources such as transaction logs and compensation logs. You can configure your system to store these logs in the database rather than in operating system files. You can use database features such as DB2 HADR or Oracle Data Guard to provide high availability for runtime logs and to automatically replicate transaction logs and compensation logs to a disaster recovery system.
Each backup method has its own constraints, advantages, and disadvantages, as described in the accompanying table.
| Type of replication | Constraints | Advantages | Disadvantages |
|---|---|---|---|
| Managed by the operating system | This type of replication ensures a coherent state across all data that is being replicated. For runtime data, this requirement means that no work can occur throughout the entire production environment during the replication. Business Process Manager servers must be quiesced and stopped. | This system is inexpensive and simple to maintain. | This approach requires a maintenance window, which imposes limits on the server availability and on the recovery point objective. Therefore, it might not be appropriate for business-critical production servers. To minimize your recovery point objective, determine the ideal backup frequency by considering the business requirements and resources to take and maintain your backups. |
| Managed by a storage area network (SAN) | The production system can write to only one file system. The SAN must provide the capability to define a single consistency group that contains all replicated volumes, including those volumes that host the database and the shared file system for the transaction and compensation logs. | This replication type is the classic technique for disaster recovery. SAN replication capability is robust and well documented. Depending on the sophistication of the SAN being used, replication points can be very short. This method can be used to manage consistent replication across various managed resources. Most SAN systems support both periodic snapshots and synchronous replication of data to a remote site. |
Requires extra hardware (the SAN), which is not available for all environments. |
| Managed by the database Note: The feature that
supports this approach is introduced in V8.0.1.2 and V8.5.0.1.
|
The database manager must have access to all the data that must be replicated. To use this method, WebSphere Application Server transaction and compensation logs must be stored within the database. | Database replication solutions like DB2 HADR and Oracle Data Guard are familiar to many infrastructure teams. Various synchronous and asynchronous qualities of service are possible. | Configuring all managed resources in to the same database can be problematic, depending on the amount of integration present in the application. |