Whether it is planned system maintenance or an extreme circumstance, such as when multiple components fail simultaneously, the IBM® DB2® pureScale® Feature is designed to continue processing incoming database requests without interruption. Automatic load balancing across all active members means optimal resource utilization at all times, which helps to keep application response times low.
Robust heartbeat detection ensures that failed components are identified and isolated rapidly. Recovery from component failures is fully automatic and requires no intervention.
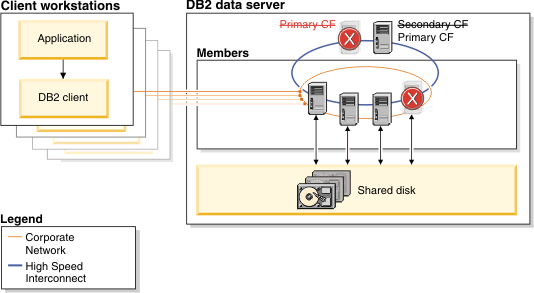
If a member fails while processing database requests, it is immediately fenced off from the rest of the system. During the failure, most of your data on the shared disk storage remains available to active members processing database requests. Only the data that was inflight on the failed member is temporarily held by a retained lock until the DB2 pureScale Feature completes the automated member crash recovery.
After a software failure, the member is restarted on its home host, and recovery is performed. The member resumes transaction processing as soon as recovery is complete. After a hardware failure, the member restarts on another host (a process known as restart light) so that the data can be recovered. As soon as its home host is available again, the member fails back to that host, restarts, and resumes processing.
After a software or hardware failure on the primary cluster caching facility, a secondary, duplexed cluster caching facility automatically takes over the primary role. This takeover is transparent to applications and causes only minimal delay because of the continuous duplexing of locking and caching information between cluster caching facilities. The instance remains available.
System maintenance in a DB2 pureScale environment is designed to cause as little disruption as possible. You can roll out system upgrades without stopping the DB2 pureScale instance or affecting database availability.
To perform system maintenance on a member, you quiesce it. After existing transactions on the member are completed (drained), you take the member offline and perform the system maintenance. During the maintenance period, new transaction requests are automatically directed to other, active members, a process that is transparent to applications.
After the maintenance is complete and you restart the member, it begins processing database transactions again as soon as it rejoins the instance.