At any time, a high availability disaster recovery (HADR) standby database is in one of five states: local catchup, remote catchup pending, remote catchup, peer, or disconnected peer. The states are defined by the log shipping status. Regardless of the state, log replay of all available logs occurs.
If a standby is connected to the primary, its is reported in the HADR_STATE field of the MON_GET_HADR table function and the db2pd command output. (If it is not connected, it reports DISCONNECTED.)
Figure 1 shows the progression through the different standby database states.
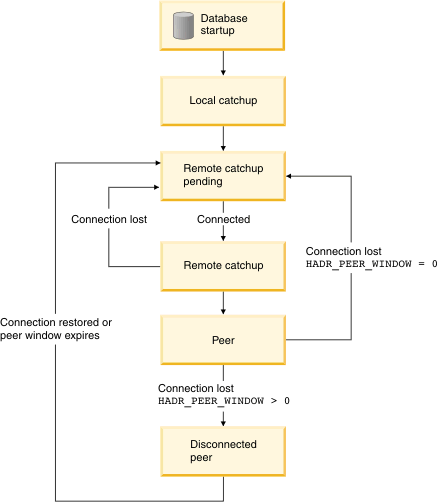
With the HADR feature, when a database is started as a standby, it enters local catchup state, and the log files in its local log path are read to determine what logs are available locally. In this state, logs are not retrieved from the archive even if you configured a log archiving method. Also, in this state, a connection to the primary database is not required; however, if a connection does not exist, the standby database tries to connect to the primary database. When the end of local log files is reached, the standby database enters remote catchup pending state.
When the standby enters remote catchup pending state, if a connection to the primary has not been established, the standby waits for a connection. After a connection is established, the standby obtains the primary's current log chain information. This enables the standby, if you configured a log archive, to retrieve log files from the archive and verify that the log files are valid.
In remote catchup state and peer state, if the standby loses its connection to the primary, it goes back to remote catchup pending state. When the connection is reestablished, the standby tries to retrieve the logs from the archive. Thus, if you configure a shared archive device, the standby might be able to find more logs than would be available if it is using a separate archiving device. As a result, using an archive can have less impact on the primary than shipping from the primary through the HADR connection.
In remote catchup state, the primary database reads log data from its log path or by way of a log archiving method, and the log data is sent to the standby database. The primary and standby databases enter peer state when the standby database receives all the on-disk log data of the primary database. If you are using the SUPERASYNC synchronization mode, the primary and standby never enter peer state. They permanently stay in remote catchup state, which prevents the possibility of blocking primary log writing in peer state.
If the connection between the primary and standby databases is lost when the databases are in remote catchup state, the standby database enters remote catchup pending state.
Assisted remote catchup state is specific to HADR in DB2® pureScale® environments.
A standby replay member might not be able to directly connect to a member on the primary because of network problems or the member on the primary being inactive. In this case, the standby replay member gets the unreachable member's logs through the assistance of another member on the primary that can connect to the standby. This assisting member uses a dedicated TCP connection for each member that it is assisting. Log streams that are in assisted remote catchup state can never enter peer state because indirect connections are used for them. Assisted remote catchup is automatically terminated when the standby replay member can directly connect to the member on the primary.
You can determine whether a member's log stream is in assisted remote catchup state by using the MON_GET_HADR table function or the db2pd command. For a member on the primary, its log stream is shown as being in REMOTE_CATCHUP state, and the HADR_FLAGS field contains the ASSISTED_REMOTE_CATCHUP flag.
In peer state, log data is shipped directly from the primary's log write buffer to the standby whenever the primary flushes its log pages to disk. The HADR synchronization mode specifies whether the primary waits for the standby to send an acknowledgement message that log data was received. The log pages are always written to the local log files on the standby database. This behavior guards against a crash and allows a file to be archived on the new primary in case of takeover, if it was not archived on the old primary. After being written to the local disk, the received log pages can then be replayed on the standby database. If log spooling is disabled, which is the default, log replay reads logs only from the log receive buffer.
If log replay is slow, the receive buffer can fill up, and the standby stops receiving new logs. If this happens, primary log writing is blocked. If you enable log spooling, a part of the log buffer is released even if it was not replayed yet, so primary log writing can continue. Log replay reads the log data from disk later. If the spooling device fills up or the configured spool limit is reached, the standby still stops receiving, and the primary is blocked again.
If the connection between the primary and standby databases is lost when the databases are in peer state and the hadr_peer_window database configuration parameter is set to 0, which is the default, the standby database enters remote catchup pending state. However, if the connection between the primary and standby databases is lost during peer state and you set the hadr_peer_window parameter to a nonzero value (meaning that you configured a peer window), the standby database enters disconnected peer state.
If you configured a peer window and the primary database loses its connection with the standby database while in peer state, the primary database continues to behave as though the primary and standby databases were in peer state. This behavior lasts until the peer window expires or until the standby reconnects, whichever occurs first. When the primary database and standby database are disconnected but behave as though in they were in peer state, this state is called disconnected peer.
The advantage of configuring a peer window is that it lowers the risk of transaction loss during multiple or cascading failures. Without the peer window, when the primary database loses its connection with the standby database, the primary database moves out of peer state immediately and continues transaction processing. These transactions are not replicated to the standby. If the primary server fails shortly after it loses its connection to the standby, the risk of transaction loss is high in a failover. With the peer window enabled, the primary database blocks transaction processing for a certain amount of time after losing its connection to the standby in peer state, guarding against cascading failures. Furthermore, the standby can take over within the peer window time with no risk of data loss.
The disadvantage of configuring a peer window is that transactions on the primary database take longer or even time out while the primary database is in the peer window waiting for the connection with the standby database to be restored or for the peer window to expire. As well, intermittent network failures can cause a severe impact on primary transaction processing.
You can determine the peer window size, which is the value of the hadr_peer_window database configuration parameter, by using the MON_GET_HADR table function or the db2pd command with the -hadr parameter.
One way to synchronize the primary and standby databases is to manually copy the primary database log files into the standby database log path or overflow log path, if configured. Manually copying files can be especially helpful if there is a large log gap between the primary and standby, for example, because the standby database was down for a long time. Manually copying files can reduce the delay of the standby having to retrieve the logs from the archive, or it can reduce the impact on the primary of having to ship these log files, which the primary would likely have to retrieve from the archive.
It is important to do this step before activating the standby database. After you deactivate the standby database,it proceeds with searching local log files, attempting to retrieve from the archive, and engaging the primary for log shipping, as described previously. If you copy the log files to the standby after you have activated it can interfere with the standby's normal operation.