Star schema access
DB2® can use special join methods, such as star join and pair-wise join, to efficiently join tables that form a star schema.

You can think of the fact table, which is much larger than the dimension tables, as being in the center. The fact table is surrounded by dimension tables. The result resembles a star formation. The following figure illustrates the star formation that is created by a star schema.

Unlike other join methods, such as nested loop join, merge scan join, and hybrid join, which join only two tables in each step, a single step in the star schema method can involve three or more tables. If the required indexes exist, DB2 might choose special methods such as star join and pair-wise join to process queries on a star schema more efficiently.
The index for the fact table must contain columns of only the following data types:
Example star schema
In this typical example, the star schema is composed of a fact table, SALES, and a number of dimension tables that are connected to it for time, products, and geographic locations.
The TIME table has a column for each month, quarter, and year. The PRODUCT table has columns for each product item, its class, and its inventory. The LOCATION table has columns of geographic data, including city and country.
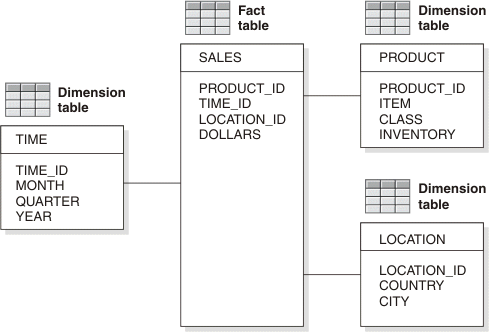
In this scenario, the SALES table contains only three columns with IDs from the dimension tables, TIME, PRODUCT, and LOCATION, instead of three columns for time data, three columns for product data, and two columns for location data. Thus, the size of the fact table is greatly reduced. In addition, when you must change an item, you make only a single change in the dimension table, instead of making many changes in the fact table.
You can create even more complex star schemas by normalizing a dimension table into several tables. The normalized dimension table is called a snowflake. Only one of the tables in the snowflake joins directly with the fact table.
Example star join query with three dimension tables
- A fact table for SALES (S)
- A dimension table for TIME (T) with columns for an ID, month, quarter, and year
- A dimension table for geographic LOCATION (L) with columns for an ID, city, region, and country
- A dimension table for PRODUCT (P) with columns for an ID, product item, class, and inventory
You might write the following query to join the tables:
SELECT *
FROM SALES S, TIME T, PRODUCT P, LOCATION L
WHERE S.TIME = T.ID AND
S.PRODUCT = P.ID AND
S.LOCATION = L.ID AND
T.YEAR = 2005 AND
P.CLASS = 'AUDIO' AND
L.LOCATION = 'SAN JOSE';You would use the following index:
CREATE INDEX XSALES_TPL ON SALES (TIME, PRODUCT, LOCATION);Your EXPLAIN output looks like the following table.
| QUERYNO | QBLOCKNO | METHOD | TNAME | JOIN_
TYPE |
SORTN_
JOIN |
ACCESS
TYPE |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | TIME | S | Y | R |
| 1 | 1 | 1 | PRODUCT | S | Y | R |
| 1 | 1 | 1 | LOCATION | S | Y | R |
| 1 | 1 | 1 | SALES | S | I |
All snowflakes are processed before the central part of the star join, as individual query blocks, and are materialized into work files. A work file exists for each snowflake. The EXPLAIN output identifies these work files by naming them DSN_DIM_TBLX(nn), where nn indicates the corresponding QBLOCKNO for the snowflake.
This next example shows the plan for a star join that contains two snowflakes. Suppose that two new tables MANUFACTURER (M) and COUNTRY (C) are added to the tables in the previous example to break dimension tables PRODUCT (P) and LOCATION (L) into snowflakes:
- The PRODUCT table has a new column MID that represents the manufacturer.
- Table MANUFACTURER (M) has columns for MID and name to contain manufacturer information.
- The LOCATION table has a new column CID that represents the country.
- Table COUNTRY (C) has columns for CID and name to contain country information.
You might write the following query to join all the tables:
SELECT *
FROM SALES S, TIME T, PRODUCT P, MANUFACTURER M,
LOCATION L, COUNTRY C
WHERE S.TIME = T.ID AND
S.PRODUCT = P.ID AND
P.MID = M.MID AND
S.LOCATION = L.ID AND
L.CID = C.CID AND
T.YEAR = 2005 AND
M.NAME = 'some_company';The joined table pairs (PRODUCT, MANUFACTURER) and (LOCATION, COUNTRY) are snowflakes. The EXPLAIN output of this query looks like the following table.
| QUERYNO | QBLOCKNO | METHOD | TNAME | JOIN
TYPE |
SORTN
JOIN |
ACCESS
TYPE |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | TIME | S | Y | R |
| 1 | 1 | 1 | DSN_DIM_TBLX(02) | S | Y | R |
| 1 | 1 | 1 | SALES | S | I | |
| 1 | 1 | 1 | DSN_DIM_TBLX(03) | Y | T | |
| 1 | 2 | 0 | PRODUCT | R | ||
| 1 | 2 | 1 | MANUFACTURER | I | ||
| 1 | 3 | 0 | LOCATION | R | ||
| 1 | 3 | 4 | COUNTRY | I |
- QBLOCKNO=1: The main star join block
- QBLOCKNO=2: A snowflake (PRODUCT, MANUFACTURER) that is materialized into work file DSN_DIM_TBLX(02)
- QBLOCKNO=3: A snowflake (LOCATION, COUNTRY) that is materialized into work file DSN_DIM_TBLX(03)
The joins in the snowflakes are processed first, and each snowflake is materialized into a work file. Therefore, when the main star join block (QBLOCKNO=1) is processed, it contains four tables: SALES (the fact table), TIME (a base dimension table), and the two snowflake work files.
In this example, in the main star join block, the star join method is used for the first three tables (as indicated by S in the JOIN_TYPE column of the plan table) and the remaining work file is joined by the nested loop join with sparse index access on the work file (as indicated by T in the ACCESSTYPE column for DSN_DIM_TBLX(3)).

When DB2 uses star schema access
To access the data in a star schema, you often write SELECT statements that include join operations between the fact table and the dimension tables, but no join operations between dimension tables. DB2 uses star schema processing as the join type for the query if the following conditions are true:
- The number of tables in the star schema query block, including the fact table, dimensions tables, and snowflake tables, is greater than or equal to the value of the SJTABLES subsystem parameter.
- The value of subsystem parameter STARJOIN is 1, or the cardinality of the fact table to the
largest dimension table meets the requirements that are specified by the value of the subsystem
parameter. The values of STARJOIN and cardinality requirements are:
- DISABLED
- Star schema processing is disabled. This is the default.
- ENABLED
- Star schema processing is enabled if the cardinality of the fact table is at least 25 times the cardinality of the largest dimension that is a base table that is joined to the fact table.
- 1
- Star schema processing is enabled. The one table with the largest cardinality is the fact table. However, if more than one table has this cardinality, star join is not enabled.
- n, where 2 ≤ n ≤ 32768.
- Star schema processing is enabled if the cardinality of the fact table is at least n times the cardinality of the largest dimension that is a base table that is joined to the fact table.
In addition to the settings of SJTABLES and STARJOIN, the following conditions must also be met:
- The query references at least two dimensions.
- All join predicates are between the fact table and the dimension tables, or within tables of the same snowflake. If a snowflake is connected to the fact table, only one table in the snowflake (the central dimension table) can be joined to the fact table.
- All join predicates between the fact table and dimension tables are equijoin predicates.
- All join predicates between the fact table and dimension tables are Boolean term predicates.
- None of the predicates consist of a local predicate on a dimension table and a local predicate on a different table that are connected with an OR logical operator.
- No correlated subqueries cross dimensions.
- No single fact table column is joined to columns of different dimension tables in join predicates. For example, fact table column F1 cannot be joined to column D1 of dimension table T1 and also joined to column D2 of dimension table T2.
- After DB2 simplifies join operations, no outer join operations exist.
- The data type and length of both sides of a join predicate are the same.
- The index on the fact table contains columns that have only the following
data types:

- CHARACTER
- DATE
- DECIMAL
- DOUBLE
- INTEGER
- SMALLINT
- REAL
- TIME
- TIMESTAMP
- VARCHAR

Star join, which can reduce bind time significantly, does not provide optimal performance in all cases. The performance of star join depends on the availability of indexes on the fact table, the cluster ratio of the indexes, and the selectivity of local and join predicates, among other factors. Follow these general guidelines for setting the value of SJTABLES:
- If you have queries that reference fewer than 10 tables in a star schema database and you want
to make the star join method applicable to all qualified queries, set the value of SJTABLES to the
minimum number of tables that are used in queries that you want to be considered for star join.
For example, suppose that you query a star schema database that has one fact table and three dimension tables. Set SJTABLES to 4.
- If you want to use star join for relatively large queries that reference a star schema database but are not necessarily suitable for star join, use the default. The star join method is considered for all qualified queries that have 10 or more tables.
- If you have queries that reference a star schema database but, in general, do not want to use star join, consider setting SJTABLES to a higher number, such as 15, if you want to drastically cut the bind time for large queries and avoid a potential bind time -101 SQL return code for large qualified queries.