Nested loop join (METHOD=1)
In nested loop join DB2® scans the composite (outer) table. For each row in that table that qualifies (by satisfying the predicates on that table), DB2 searches for matching rows of the new (inner) table.

DB2 concatenates any matching rows that it finds with the current row of the composite table. If no rows match the current row, then:
- For an inner join, DB2 discards the current row.
- For an outer join, DB2 concatenates a row of null values.
Stage 1 and stage 2 predicates eliminate unqualified rows during the join. (For an explanation of those types of predicate, see Stage 1 and stage 2 predicates.) DB2 can scan either table using any of the available access methods, including table space scan.

Performance considerations for nested loop join
A nested loop join repetitively scans the inner table of the join.
That is, DB2 scans the outer table once, and scans the inner table as many times as the number of qualifying rows in the outer table. Therefore, the nested loop join is usually the most efficient join method when the values of the join column passed to the inner table are in sequence and the index on the join column of the inner table is clustered, or the number of rows retrieved in the inner table through the index is small.
When nested loop join is used
DB2 often uses a nested loop join in the following situations.
- The outer table is small.
- Predicates with small filter factors reduce the number of qualifying rows in the outer table.
- Either an efficient, highly clustered index exists on the join columns of the inner table, or DB2 can dynamically create a sparse index on the inner table, and use that index for subsequent access.
- The number of data pages that are accessed in the inner table is small.
- No join columns exist. Hybrid and sort-merge joins require join columns; nested loop joins do not.
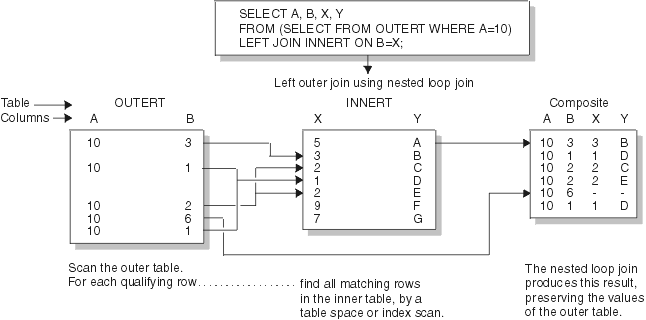
Example: left outer join
The following figure illustrates a nested loop for a left outer join. The outer join preserves the unmatched row in OUTERT with values A=10 and B=6. The same join method for an inner join differs only in discarding that row. The following figure illustrates a nested loop join.
Example: one-row table priority
For a case like the following example, with a unique index on T1.C2, DB2 detects that T1 has only one row that satisfies the search condition. DB2 makes T1 the first table in a nested loop join.
SELECT * FROM T1, T2
WHERE T1.C1 = T2.C1 AND
T1.C2 = 5;Example: Cartesian join with small tables first
SELECT * FROM T1, T2, T3
WHERE T1.C1 = T3.C1 AND
T2.C2 = T3.C2 AND
T3.C3 = 5;Join predicates are between T1 and T3 and between T2 and T3. No predicate joins T1 and T2.
Assume that 5 million rows of T3 have the value C3=5. Processing time is large if T3 is the outer table of the join and tables T1 and T2 are accessed for each of 5 million rows.
However, if all rows from T1 and T2 are joined, without a join predicate, the 5 million rows are accessed only six times, once for each row in the Cartesian join of T1 and T2. It is difficult to say which access path is the most efficient. DB2 evaluates the different options and could decide to access the tables in the sequence T1, T2, T3.
Sorts on the composite table
- The join columns in the composite table and the new table are not in the same sequence.
- The join column of the composite table has no index.
- The index is poorly clustered.
Nested loop join with a sorted composite table has the following performance advantages:
- Uses sequential detection efficiently to prefetch data pages of the new table, reducing the number of synchronous I/O operations and the elapsed time.
- Avoids repetitive full probes of the inner table index by using
the index look-aside.
Nested loop join with sparse index access
A value of PRIMARY_ACCESSTYPE = T indicates that DB2 dynamically creates a sparse index on the inner table and uses the sparse index to search the work file that is built on the inner table.
Nested loop join with sparse index has the following performance advantages:
- Access to the inner table is more efficient when the inner has no efficient index on the join columns.
- A sort of the composite table is avoided when composite table is relatively large.
 Memory allocation
for sparse index is controlled by the value of the MXDTCACH subsystem parameter. However, if the
available storage is insufficient when the query executes, DB2 might be unable to build the sparse index,
degrading performance. The solution is to resolve the memory shortage. However, if you cannot do so,
reduce the MXDTCACH setting.
Memory allocation
for sparse index is controlled by the value of the MXDTCACH subsystem parameter. However, if the
available storage is insufficient when the query executes, DB2 might be unable to build the sparse index,
degrading performance. The solution is to resolve the memory shortage. However, if you cannot do so,
reduce the MXDTCACH setting.
