Merge scan join (METHOD=2)
Merge scan join is also known as merge join or sort merge join. For this method, there must be one or more predicates of the form TABLE1.COL1=TABLE2.COL2, where the two columns have the same data type and length attribute.

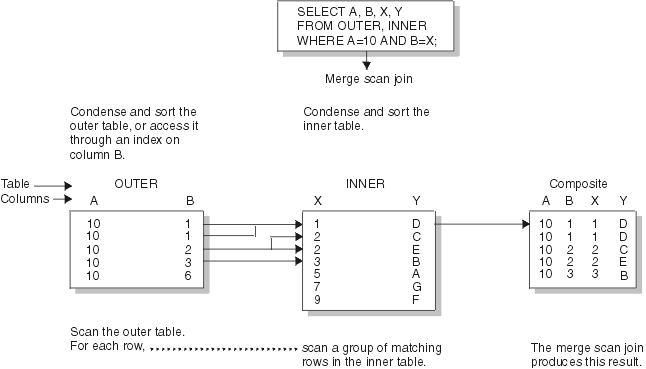
DB2® scans both tables in the order of the join columns. If no efficient indexes on the join columns provide the order, DB2 might sort the outer table, the inner table, or both. The inner table is put into a work file; the outer table is put into a work file only if it must be sorted. When a row of the outer table matches a row of the inner table, DB2 returns the combined rows.
DB2 then reads another row of the inner table that might match the same row of the outer table and continues reading rows of the inner table as long as a match is found. When a match is no longer found, DB2 reads another row of the outer table.
- If that row has the same value in the join column, DB2 reads again the matching group of records from the inner table. Thus, a group of duplicate records in the inner table is scanned one time for each matching record in the outer table.
- If the outer row has a new value in the join column, DB2 searches
ahead in the inner table. It can find any of the following rows:
- Unmatched rows in the inner table, with lower values in the join column.
- A new matching inner row. DB2 then starts the process again.
- An inner row with a higher value of the join column. Now the row
of the outer table is unmatched. DB2 searches
ahead in the outer table, and can find any of the following rows:
- Unmatched rows in the outer table.
- A new matching outer row. DB2 then starts the process again.
- An outer row with a higher value of the join column. Now the row of the inner table is unmatched, and DB2 resumes searching the inner table.
- For an inner join, DB2 discards the row.
- For a left outer join, DB2 discards the row if it comes from the inner table and keeps it if it comes from the outer table.
- For a full outer join, DB2 keeps the row.
Performance considerations for merge scan join
A full outer join by this method uses all predicates in the ON clause to match the two tables and reads every row at the time of the join. Inner and left outer joins use only stage 1 predicates in the ON clause to match the tables. If your tables match on more than one column, it is generally more efficient to put all the predicates for the matches in the ON clause, rather than to leave some of them in the WHERE clause.
For an inner join, DB2 can derive extra predicates for the inner table at bind time and apply them to the sorted outer table to be used at run time. The predicates can reduce the size of the work file needed for the inner table.
If DB2 has used an efficient index on the join columns, to retrieve the rows of the inner table, those rows are already in sequence. DB2 puts the data directly into the work file without sorting the inner table, which reduces the elapsed time.
You cannot use RANDOM order index columns as part of a sort merge join. If a join is between one table with that has an ASC index on the join column and a second table that has a RANDOM index, the indexes are in completely different orders, and cannot be merged.
When merge scan join is used
- The qualifying rows of the inner and outer table are large, and the join predicate does not provide much filtering; that is, in a many-to-many join.
- The tables are large and have no indexes with matching columns.
- Few columns are selected on inner tables. This is the case when a DB2 sort is used. The fewer the columns to be sorted, the more efficient the sort is.
