UTFs
A UTF maps each Unicode code point to a unique code unit sequence. A code unit is the minimal bit combination that can represent a character. Each UTF uses a different code unit size. For example, UTF-8 is based on 8-bit code units. Therefore, each character can be 8 bits (1 byte), 16 bits (2 bytes), 24 bits (3 bytes), or 32 bits (4 bytes). Likewise, UTF-16 is based on 16-bit code units. Therefore, each character can be 16 bits (2 bytes) or 32 bits (4 bytes).
All UTFs include the full Unicode character repertoire, or set of characters. Each UTF can represent any Unicode character that you need to represent.
The following UTFs are defined by the Unicode Consortium:
- UTF-8
- UTF-8
is based on 8-bit code units. Each character is encoded as 1 to 4
bytes.
The first 128 Unicode code points are encoded as 1 byte in UTF-8. These code points are the same as those in ASCII CCSID 367. Any other character is encoded with more than 1 byte in UTF-8.
In IBM®, UTF-8 is also known as Unicode CCSID 1208.
DB2® uses UTF-8 to encode data in the following ways:
- DB2 uses UTF-8 to encode data in CHAR, VARCHAR, and CLOB columns in Unicode tables.
- DB2 parses SQL statements and precompiles source code in UTF-8.
- The DB2 catalog tables that have the Unicode encoding scheme are encoded in UTF-8.
- UTF-16
- UTF-16 is based on 16-bit code units. Each character is encoded
as at least 2 bytes. Some characters that are encoded with a 1-byte
code unit in UTF-8 are encoded with a 2-byte code unit in UTF-16.
Characters that are surrogate or supplementary characters use 4 bytes and thus require additional storage. These characters can also be stored in UTF-8 or UTF-32, but, because they always require 4 bytes of storage, neither of these formats provide any space savings.
In IBM, UTF-16 is also known as Unicode CCSID 1200.
DB2 uses UTF-16 to encode data in GRAPHIC, VARGRAPHIC, and DBCLOB columns in Unicode tables.
- UTF-32
- UTF-32 is based on 32-bit code units. Each character is encoded as at least 4 bytes. DB2 does not store data in UTF-32.
The following table shows example UTF encodings for several characters.
| Character | Unicode code point | ASCII | UTF-8 | UTF-16 (Big Endian format)1 | UTF-32 (Big Endian format) |
|---|---|---|---|---|---|
| A | U+0041 | X'41' | X'41' | X'0041' | X'00000041' |
| a | U+0061 | X'61' | X'61' | X'0061' | X'00000061' |
| 9 | U+0039 | X'39' | X'39' | X'0039' | X'00000039' |
| Å | U+00C5 | X'C5' | X'C385'2 | X'00C5' | X'000000C5' |
| 顠 | U+9860 | X'CDDB' (CCSID 939) | X'E9A1A0' | X'9860' | X'00009860' |
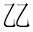 |
U + 200D0 | Does not exist | X'F0A08390' | X'D840DCD0' | X'000200D0' |
Notes:
|
|||||
Notice that for some characters, the UTF encodings are
fairly predictable. For example, the character A,
which is Unicode code point U+0041, is encoded as X'41' in
ASCII and UTF-8, and as X'0041' in UTF-16 and as X'00000041' in
UTF-32. However, the UTF encodings for a character like Å or do
not follow the same pattern.
The process of converting a value from its Unicode code point to its UTF hexadecimal value is called encoding. For example, Unicode code point U+0041 is encoded in UTF-8 as X'41'. The reverse process, converting a UTF hexadecimal value to its Unicode code point, is called decoding. For example, suppose that you see the hexadecimal value X'00C5' in trace output and you know that the data is in UTF-16. You can decode the value to find that it corresponds to Unicode code point U+00C5. You can then look up this Unicode code point on the Unicode character code charts on the Unicode Consortium web site and find that it corresponds to the character Å.
You can find the steps for how to manually encode and decode Unicode data on the Unicode Consortium web site. Alternatively, you can use a converter tool to do the conversion for you.