Component overview
SPL standard and specialized toolkits > com.ibm.streams.teda 1.0.2 > Application framework > Architecture > Lookup Manager application > Component overview
This page gives a high level overview about the internal structure of the Lookup Manager application.
The diagram shows the functional components of the Lookup Manager and the data paths between the components. The Lookup Manager application is fully customizable by adapting an XML file. There is no need to write any SPL code for customization, so this chapter with implementation details is only for your reference.
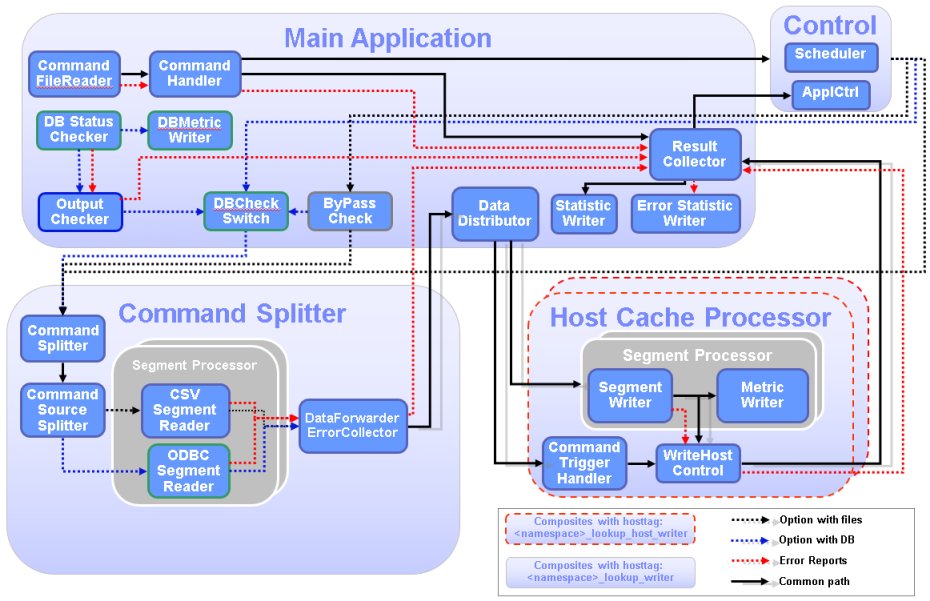
The most important components are described below. The order roughly reflects the flow of commands and data through the Lookup Manager application. From Main Application to Control and back to main. Than the data flows through the Command Splitter, the Host Cache Processor, and back to the Main Application and the Control.
Command File Reader and Command Handler
The entry point of the Lookup Manager application is the command file reader that scans the input directory for new command files and forwards the commands in the file to the Command Handler. The command handler notifies the Result Collector about the number of commands, so the result collector knows how many results to expect, before the command file is considered to be completely processed. In case of any error, it reports the fault to the Result Collector.
Control
The Control function queues the commands and initiates a stop request to all known ITE applications, to ensure that the following modification of the lookup repositories will not interfere with read operations from the ITE applications. Once all ITE applications have acknowledged the request the commands are forwarded to the ByPass Check, the DB Check Switch or the Command Splitter. Which path is chosen depends on the data source configuration of the Lookup Manager.
ByPass Check
In case the Lookup Manager uses CSV files and databases as data sources, the ByPass Check determines the type of data source for this command and either forwards it directly to the command splitter for CSV input or the DB Status Switch for database input.
DB Status Checker and DB Check Switch
If the received command uses a database as source, the DB Check Switch forwards the command to the splitter only if the database is available and can be connected. The DB Status Checker checks the status of the database periodically and it reports the result to the DB Check Switch. In case of any error, it reports the fault to the Result Collector.
Command Splitter
The Command Splitter selects the appropriate Segment Reader, based on the data source (CSV or database) and the segment name given in the command and forwards the command to the Segment Reader. The segment readers start to retrieve data from the data sources. The tuples containing the lookup repository entries are send to the Data Distributor.
Segment Reader
The segment readers are retrieving the enrichment data from the sources, either by processing a SQL statement on a database or by parsing CSV files. For each configured segment one CSV reader and one ODBC reader may exist, depending on the configuration. In case of any error, it reports the fault to the Result Collector.
Data Distributor
The Data Distributor sends the output from the segment readers to all hosts. The data is sent in parallel to allow the hosts to update their lookup repositories at the same time.
Host Cache Processor
The Host Cache Processor is responsible for the write processing on one host, for collecting all results and for reporting the status to the result collector. All segments are written in parallel to improve performance. You need to add certain Streams host tags to the hosts, which should receive the lookup data. The host cache processor instances run on these hosts only. ITE applications, which need to access the enrichment data must run on hosts where the enrichment data is made available. In case of any error, it reports the fault to the Result Collector.
Result Collector
The Result Collector collects the status of the write operations from the host cache processors, creates statistics for the statistics writer and reports command process completion to the application control. If all commands are processed, the result collector moves the command file to its archive directory. Afterwards the application control sends start requests to all ITE applications, so the file processing in the ITE applications can resume. If any component reports an error, then the Result Collector creates the error statistic for the error statistic writer and it moves the command file to its failed directory.