Product Documentation
Abstract
The following text describes the structure of messages that are returned by an accelerator if the state of the hardware changes or if problems are encountered. These messages start with the prefix or qualifier DSNX881I.
Content
General information
When an accelerator has been connected successfully to a Db2 subsystem, and the accelerator has been started by the -START ACCEL command or the corresponding function in IBM Db2 Analytics Accelerator Studio, a heartbeat connection is established between the accelerator and that particular Db2 subsystem. Status information about the accelerator is sent to the DB2 subsystem every 30 seconds.
You can view most of this information by using the -DIS ACCEL DB2 commands. Other information cannot be viewed in this way, but is written to the z/OS system log (SYSLOG).
IBM Db2 Analytics Accelerator is a solution that consists of various hardware and software components. Each of these components might issue a DSNX881I message.
If the message indicates a hardware or software problem, open a service request (PMR) with component ID (CompID) 5697AQT00.
Never open a service request for Netezza, the IBM PureSystems for Analytics, or the IBM Integrated Analytics System . Always use the IBM Db2 Analytics Accelerator CompID, even if the problem is related to Db2 for z/OS or to the attached accelerator hardware.
Your service request will be routed internally to the proper support request queue. Make sure the request contains an IBM Db2 Analytics Accelerator trace file that was obtained by using the Save Trace function in IBM Db2 Analytics Accelerator Studio.
Such a trace file does not only contain software trace messages, but also a complete set of diagnostic hardware information.
DSNX881I message structure
Each DSNX881I message (For details see: IBM Knowledge Center) is made up of the following parts, which appear in the order as is shown in the following lines:
DSNX881I -<SSID> <MESSAGE-ID> <SEVERITY> <ACCELERATOR_MESSAGE_COUNTER> (<ACCELERATOR-TIMESTAMP>) ACCELERATOR-NAME(ACCELERATOR-IP) <MESSAGE-TEXT>
The placeholders have the following meaning:
SSID
- Is the Db2 subsystem ID (SSID)
MESSAGE-ID
- A numeric ID for the specific error message. This ID can be used for system monitoring.
SEVERITY
- I
- Information message
- Warning message
- Error message
- An internal counter that increases with every additional error on the accelerator.
If the text after the DSNX881I qualifier is longer than 255 characters, another DSNX881I message is issued.
All messages belonging together will have the same <ACCELERATOR_MESSAGE_COUNTER> value.
The <MESSAGE-TEXT> block of the each subsequent message contains a sequel to the information in the previous message.
- The time when the error occurred on the accelerator. The internal clock of the accelerator is synchronized with the first Db2 subsystem that was connected to the accelerator.
ACCELERATOR-NAME
- The name of the accelerator where the error occurred.
ACCELERATOR-IP
- The IP address of the accelerator where the error occurred.
The field can be empty if no IP address can be determined. However, the parenthesis will appear.
MESSAGE
- A textual description of the error.
The length of a DSNX881I message does not exceed 255 characters. If more characters are needed, additional DSNX881I messages are written to the SYSLOG.
If an LPAR contains multiple Db2 subsystems that are connected to the same physical accelerator, error messages are issued for every subsystem. That is, you see the same messages multiple times in the log, each time with a different subsystem ID (SSID).
If an accelerator is paired with a data sharing group (DSG), all members of the group can write messages to group's system logs (SYSLOGs), provided that the -START ACCEL command has been issued for all members.
In this case, make sure that applications are in place monitoring the SYSLOGs. If all members of the DSG are located in the same logical partition (LPAR), there is only one SYSLOG to monitor.
However, if the members are located in different LPARs, you need to monitor the SYSLOGs of all LPARs involved. See the following diagrams:
Figure 1:
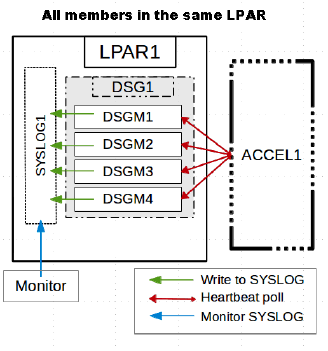 Figure 2:
Figure 2: 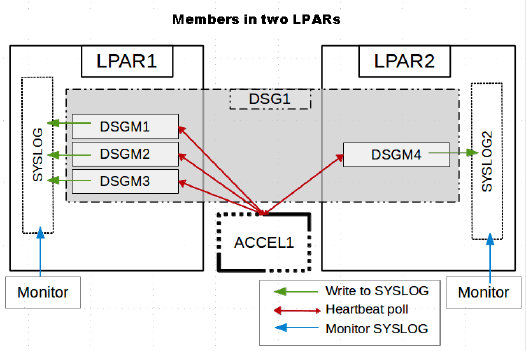
Note: It might look as if only one member writes messages to the SYSLOG, but this is actually a synchronization issue.
If one member is always the first to issue a heartbeat request, then this member will receive all the messages and write these to the SYSLOGs. After that, the messages are deleted from the accelerator queue.
The other members that send their heartbeat requests later, will not receive these messages because the queue is empty.
You might also see that only a few members write messages to the SYSLOG. This just means that the first member to send a heartbeat request is (always) found among this subset of members. The underlying mechanism is the same.
An error can occur although accelerator is in the Stopped state. In this case, the -STOP ACCEL command was issued before an error message could be stored on the accelerator.
As soon as the accelerator becomes available again in Db2, the stored error messages are sent to the Db2 subsystem, provided that -START ACCEL has been issued for the subsystem, or, in case of a data sharing group, for at least one member of the group.
It might happen that a DSNX881I message reports a past problem that has already been fixed.
List of MESSAGE-IDs, SEVERITY and MESSAGE-TEXT
The following numbers might be displayed in a DSNX881I message as values of the MESSAGE-ID, SEVERITY and MESSAGE-TEXT parts:
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 1 | I | HostStateChange | sysStateChanged | 2 |
Expected MESSAGE-TEXT
System <HOST> went from <previousState> to <currentState> at <eventTimestamp> <eventSource>. <notifyMsg> Event: <eventDetail>
ImpactAvailability of the accelerator for query processing. Everything different from Online prevents the accelerator from answering queries.
Note: In contrast to a restart of the database engine on the accelerator, a restart of IBM Db2 Analytics Accelerator itself does not produce a DSNX881I message. However, to find indicators for accelerator restarts in the SYSLOG, look for "TCP/IP Connection loss" messages.
If <currentState> shows a value other than Online, run one of the following functions or commands from the IBM Db2 Analytics Accelerator Console:
- The nzstart command for Netezza systems (Db2 Analytics Accelerator up to version 5.1.0)
- 1) Run Accelerator Functions, then 4) Restart accelerator process for Db2 Analytics Accelerator 7.1.0 and later
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 2 | E | HardwareServiceRequested | hwServiceRequested | 3 |
NPS system <HOST> - Service requested for <hwType> <hwId> at <eventTimestamp> <eventSource>. <notifyMsg> location:<location> error string:<errString> devSerial:<devSerial> event source:<eventSource>
ImpactFor devices such as disks, a hardware failure causes the system to bring a spare disk online, and after an activation period, the spare disk replaces the damaged disk. However, it is important to replace the damaged disk with a working disk so that you can restore the system to its normal state of operation with sufficient spare disks for future failures. In other cases, such as the failure of an entire Snippet Processing Unit (SPU), the system reroutes the work of the defective SPU to other available SPUs. The system performance decreases because the remaining resources take on extra workload. Again, it is critical to obtain service. Any query, table load, or partition move in progress might end abnormally.
ActionContact IBM to replace the faulty component and restore the system to its normal state of operation.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 3 | I | HardwareRestarted | hwRestarted | N/A |
Expected MESSAGE-TEXT
NPS system <HOST> - <hwType> <hwId> restarted at <eventTimestamp>. <notifyMsg> SPA ID: <spaId> SPA Slot: <spaSlot>
ImpactThis notification is sent after rebooting a SPU successfully. Restarts are usually caused by software or hardware failures. A hardware failure might indicate irreparable memory faults or a failed disk driver interaction. Any query, table load, or partition move in progress might end abnormally.
ActionN/A
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 4 | W | Disk80PercentFull | hwDiskFull | N/A |
Expected MESSAGE-TEXT
NPS system <HOST> - <hwType> <hwId> <partition> partition is <value> % full at <eventTimestamp>. <notifyMsg> SPA ID: <spaId> SPA Slot: <spaSlot> Threshold: <threshold> Value: <value>
ImpactThis warning occurs if a hard disk is at least 80 percent, but no more than 85 percent full. If the disk space usage remains within this range, the message will not be sent again. If you receive this message from one or two disks, your data might be unevenly distributed across the data slices or processing nodes (data skew). A full disk might prevent operations.
ActionReclaim space or remove redundant tables from the accelerator. To prevent further notifications, the disk space usage needs to drop below 75 percent. Consider changing the the distribution of data by defining distribution keys in IBM Db2 Analytics Accelerator Studio.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 4 | W | Disk90PercentFull | hwDiskFull | N/A |
Expected MESSAGE-TEXT
URGENT: NPS system <HOST> - <hwType> <hwId> <partition> partition is <value> % full at <eventTimestamp>. <notifyMsg> SPA ID: <spaId> SPA Slot: <spaSlot> Threshold: <threshold> Value: <value>
ImpactThis warning occurs if a hard disk is at least 90 percent, but no more than 95 percent full. If the disk space usage remains within this range, the message will not be sent again. If you receive this message from one or two disks, your data might be unevenly distributed across the data slices or processing nodes (data skew). A full disk might prevent operations.
ActionReclaim space or remove redundant tables from the accelerator. To prevent further notifications, the disk space usage needs to drop below 85 percent. Consider changing the the distribution of data by defining distribution keys in IBM Db2 Analytics Accelerator Studio.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 5 | I | RunAwayQuery | runawayQuery | N/A |
Expected MESSAGE-TEXT
NPS system <HOST> - long-running query detected at <eventTimestamp>. <notifyMsg> sessionId: <sessionId> planId: <planId> duration: <duration> seconds
ImpactThis information hints at a long-running query that occupies resources claimed by other processes or operations.
ActionView the query monitoring section in the Accelerator view of IBM Db2 Analytics Accelerator Studio. Click Show Plan to view the access plan graph of the query. Try to find the reason for the long execution time. If the graph shows broadcasts or redistributions, try to eliminate these by using distribution keys. Organizing keys might help to speed up table scans.
For information on how to read an access plan graph, see: Nodes in an access plan graph
For a better understanding of distribution keys, watching the following videos might be helpful
(playing time for both roughly 10 min.):
If you cannot determine the reason, proceed as follows:
- If the query runs to completion, switch on tracing. Select all options including the history log and core dumps. Then rerun the query and send the trace file to IBM support.
- If the query hangs, take one of the following actions:
- Cancel the query, but save its SQL code to submit it to IBM support for investigation.
- Let the query run and contact IBM support immediately.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 6 | E | SystemStuckInState | systemStuckInState | N/A |
Expected MESSAGE-TEXT
NPS system <HOST> - System Stuck in state <currentState> for <duration> seconds. The system is stuck in state change. Duration: <duration> seconds Current State: <currentState> Expected State: <expectedState>
ImpactThe error occurs if the accelerator cannot reach the Online state, which means that it cannot process queries.
ActionStart the IBM Db2 Analytics Accelerator Console and run the following commands:
For Db2 Analytics Accelerator up to version 5.1.0:
- nzstop
- nzstart
- 1) Run Accelerator Functions, then 6) Stop backend database.
- 1) Run Accelerator Functions, then 7) Start backend database.
If the accelerator remains in a state other than Online, contact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 7 | W | SCSIPredictiveFailure | scsiPredictiveFailure | 3 |
Expected MESSAGE-TEXT
NPS system <HOST> - SCSI Predictive Failure value exceeded for disk <diskHwId> at <eventTimestamp>. <notifyMsg> spuHwId:<spuHwId> disk location:<location> scsiAsc:<scsiAsc> scsiAscq:<scsiAscq> fru:<fru> devSerial:<devSerial> diskSerial:<diskSerial> diskModel:<diskModel> diskMfg:<diskMfg> event source:<eventSource>
ImpactThe hard disks that are used to store data slices record performance and reliability data as they perform input and output operations. This is part of Netezza's Self-Monitoring Analysis and Reporting Technology (SMART). When predefined thresholds are exceeded, a disk might begin to perform poorly (that is, it reads or writes data more slowly than before). This affects the speed at which queries are processed. Exceeded thresholds might also indicate that the disk is likely to fail in the near future.
ActionThere is no immediate problem. One or more disks might fail in the future. A permanent disk failure will be reported as a SCSIDiskError.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 8 | W | EccErrorMessage | eccError | N/A |
Expected MESSAGE-TEXT
NPS system <HOST> -<hwType> <hwId> Soft (ECC) memory error recorded at <eventTimestamp>. <notifyMsg> SPA ID:<spaId> SPA Slot:<spaSlot>
ImpactIf a disk fails that is holding data slices, the disk regeneration process mirrors the data on a spare disk. If this process fails, this error message is issued. This condition might prevent a successful data regeneration. Look for other messages that might help identify the problematic disk.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 9 | E | RegenFault | regenFault | 2 |
Expected MESSAGE-TEXT
NPS system <HOST> - regen fault on SPU <hwIdSpu>. <notifyMsg> <hwIdSrc>:<hwIdSrc> source location:<locationSrc> hwIdTgt:<hwIdTgt> target location:<locationTgt> devSerial:<devSerial> error string:<errString> event source:<eventSource>
ImpactIf a disk fails that is holding data slices, the disk regeneration process mirrors the data on a spare disk. If this process fails, this error message is issued. This condition might prevent a successful data regeneration. Look for other messages that might help identify the problematic disk.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 10 | E | SCSIDiskError | scsiDiskError | 4 |
Expected MESSAGE-TEXT
NPS system <HOST> - disk error on disk <diskHwId>. <notifyMsg> spuHwId:<spuHwId> disk location:<location> errType:<errType> errCode:<errCode> oper:<oper> dataPartition:<dataPartition> lba:<lba> dataSliceId:<dataSliceId> tableId:<tableId> block:<block> devSerial:<devSerial> fpgaBoardSerial:<fpgaBoardSerial> diskSerial:<diskSerial> diskModel:<diskModel> diskMfg:<diskMfg> event source:<eventSource>
ImpactThis error is reported in the event of a serious disk error that involves a failover process. In case of such an error, the system skips the faulty disk and uses spare disks instead. This error message notifies you about the event. A failover process is likely to reduce the system performance until the faulty disk is replaced.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 11 | W | ThermalFault | hwThermalFault | N/A |
Expected MESSAGE-TEXT
NPS system <HOST> -<hwType> <hwId> Hardware Thermal Fault at <eventTimestamp> <notifyMsg> label:<label> location:<location> curVal:<curVal> error string:<errString> event source:<eventSource>
ImpactThe system monitors the hardware temperature of key components, such as Snippet Processing Units (SPUs) and disk enclosures, to maintain reliability and to prevent failures due to overheating. This warning occurs if the internal temperature of key components rises above the specified operational threshold. If the components remain in this state, their longevity might be drastically reduced.
Action- Physically investigate the machine room.
- Verify that the ambient temperature is within acceptable limits.
- Make sure that the airflow to and from the system is not occluded.
- Verify that there are no signs of combustion.
- Make sure that the cooling components (fans or blowers) are functioning properly.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 12 | E | SystemHeatThresholdExceededMessage | sysHeatThreshold | N/A |
Expected MESSAGE-TEXT
Urgent: NPS system <HOST> -<hwType> <hwId> System Heat Threshold Exceeded at <eventTimestamp>. <notifyMsg> Error Type:<errType> Error Code:<errCode> Error String:<errString>
ImpactThis error message is issued if three Snippet Processing Units (SPUs) or Switching Fabric Interfaces (SFIs) in a Snippet Processing Array (SPA) reach the "red" threshold. The system will shut down to prevent harm to the hardware.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 13 | W | SpuCore | spuCore | 4 |
Expected MESSAGE-TEXT
NPS History Capture Event from <HOST>' -bodyText 'History data capture error: Configuration Name = <configName> Storage Limit = <storageLimit> Load Min Threshold = <loadMinThreshold> Load Max Threshold = <loadMaxThreshold> Disk Full Threshold = <diskFullThreshold> Load Interval = <loadInterval> Target NPS = <nps> Target Database = <database> Current Batch Size(MB) = <capturedSize> Staged Batches Size(MB) = <stagedSize> Total Data Size(MB) = <storageSize> Batch Directory = <dirName> Error Code = <errCode> Error Message = <errString>
ImpactThis warning might be issued when a query fails. A Snippet Processing Unit (SPU) core is a dump file that helps to troubleshoot query problems. SPU core files are contained in accelerator trace files. A query, table load, or partition move might fail before the event.
ActionIf this warning occurs repeatedly, contact IBM support and provide an accelerator trace file that includes SPU core dumps.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 14 | E | VoltageFault | hwVoltageFault | 4 |
Expected MESSAGE-TEXT
NPS system <HOST> -<hwType> <hwId> Hardware Voltage Fault at $eventTimestamp. <notifyMsg> label:<label> location:<location> voltage:<curVolt> error string:<errString> event source:<eventSource>
ImpactThe system monitors the voltages and the power supplies for Snippet Processing Units (SPUs) and disk enclosures. If the voltage sensors detect variations that are outside of the specified operational range, the system issues this error message. The error might indicate a power supply problem.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 15 | I | SpuNetIfChanged | nwIfChanged | N/A |
Expected MESSAGE-TEXT
A network interface on a SPU has changed states.
ImpactThe Network Interface State Change event sends a notification when the state of a network interface on a Snippet Processing Unit (SPU) has changed.
ActionN/A
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 16 | I | SpuCpuCoreChangeEvent | numCpuCoreChanged | N/A |
Expected MESSAGE-TEXT
Num Core Changed. Hardware id = <hwId> Location = <location> Current number of cores = <currNumCore> Changed number of cores = <changedNumCore>
ImpactThis information message is sent when a CPU core of a Snippet Processing Unit (SPU) has gone offline and the SPU is operating at a reduced performance level. If a CPU core of a SPU fails, the system continues processing without that SPU (failover).
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 17 | W | IMMevent | N/A |
Expected MESSAGE-TEXT
HardwareEvent: From (<fromType>) <fromMsg>; Type: <typeOfAlert>; Sev: <severity>'; Msg: <alertValue>
ImpactThis warning is issued when an alert situation is detected by the hardware management module of the host computers or controlling nodes. The message hints at a critical situation, warning, system alert, or event.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 18 | W | HardwareNeedsAttention | hwNeedsAttention | 3 |
Expected MESSAGE-TEXT
Hardware Path Down. Hardware type = <hwType> Hardware ID = <hwId> Location = <location>
ImpactIf the communication between a snippet processing unit (SPU) and a disk does not work, that is, if the state of a storage path has changed from "Up" to "Down", the system notifies you of this error. Blocked communication paths reduce the system performance and the query performance.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 19 | W | HardwareNeedsAttention | hwNeedsAttention | 3 |
Expected MESSAGE-TEXT
Hardware needs attention. Host = <HOST> Hardware type = <hwType> Hardware ID = <hwId> Location = <location>
ImpactThe system monitors the overall health and status of the hardware and can notify you if the system availability, the system manageability, or its performance are impacted negatively. Such events can be:
- Replacement disks with invalid firmware
- Storage configuration changes
- Unavailable or unreachable components
- Disks that have reached an early warning threshold because of accumulated defects
- Unavailable Ethernet switch ports
- Other conditions that might be early indicators of problems.
Contact IBM support to replace the faulty component.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 20 | I, W, E | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
Id: <id> Subscription: <subscription_names> Message: <message> Originator: <originator>
ImpactThe incremental update function has detected an error and needs your attention.
ActionOpen the Replication Event Viewer in IBM Db2 Analytics Accelerator Studio to check the incremental update function and diagnose the problem.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 21 | W | AutoReOrg | N/A | N/A |
Expected MESSAGE-TEXT
Stable transaction ID in backend database does not progress; a restart of the database engine is recommended.
ImpactA hanging session has been encountered. The problem could not be solved automatically. A restart of the system is required to end the hanging session.
ActionRestart the system from the IBM Db2 Analytics Accelerator Console:
For Db2 Analytics Accelerator up to version 5.1.0:
- nzstop
- nzstart
- 1) Run Accelerator Functions, then 6) Stop backend database.
- 1) Run Accelerator Functions, then 7) Start backend database.
Contact IBM to further analyze the problem.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 22 | E | TopologyImbalance | topologyImbalance | 4 |
Expected MESSAGE-TEXT
Topology imbalance on the system detected. Error string: $errString
ImpactThe TopologyImbalance event sends a notification when the system detects an imbalance in the disk topology after a disk regeneration, or when the system transitions to the Online state after re-balancing the system topology.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 23 | I, W, E | NetezzaHealthEvent | N/A | N/A |
Expected MESSAGE-TEXT
<NzHealthCheckEventType><NzHealthCheckEventName> Details: <NzHealthCheckBody>
ImpactThe system monitors the hardware components. To detect possible issues, the system checks resource attributes provided by available device managers. It also analyzes elements or properties of the system. The reports include specific information about each detected issue and a corresponding severity level.
ActionLook at the message bodies and the severity of the messages in the report. Messages whose severity is "Information" or "Warning" are usually indications of looming problems that will manifest themselves soon. Handle these problems as described. For messages with a severity of "Error", contact IBM support and provide an accelerator trace file that includes detailed diagnostics.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 24 | E | FileSystemTooFullEvent | N/A | N/A |
Expected MESSAGE-TEXT
File system mounted at '<MountPoint>' has only <PercentageFree>% free space; critical situation reached
ImpactThe system monitors the storage resources by scanning all mounted file systems and checking the amount of free space. If disk space becomes scarce in one of these systems, an event is generated and propagated to all client database management systems.
ActionIf "/nz" is the mount point of a file system reported to have reached a critical stage, use the "Remove Software Versions" function in IBM Db2 Analytics Accelerator Studio to free up disk space in this file system. In other cases, contact IBM support and provide an accelerator trace file that includes detailed diagnostics.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 25 | E | InvalidMemoryConfigurationForReplicationProcess | N/A | N/A |
Expected MESSAGE-TEXT
Maximum memory configuration for running CDC process dmts64-java is not greater than or equal to 8192 MB. Process configuration must be updated manually by IBM support
ImpactThe memory for the CDC Java process is insufficient or the memory configuration is invalid.
ActionContact IBM support to update the configuration.
| DSNX881I-ID | Severity | Accelerator Event Category | Event Category | Call-Home PMR Severity |
| 26 | E | HistCaptureEvent | histCaptureEvent | N/A |
Expected MESSAGE-TEXT
History data capture error. Host = $HOST Configuration Name =$configName Storage Limit =$storageLimit Load Min Threshold =$loadMinThreshold Load Max Threshold =$loadMaxThreshold Disk Full Threshold =$diskFullThreshold Load Interval =$loadInterval Target NPS =$nps Target Database =$database Current Batch Size(MB) =$capturedSize Staged Batches Size(MB) =$stagedSize Total Data Size(MB) =$storageSize Batch Directory =$dirName Error Code =$errCode Error Message = $errString
ImpactA problem prevented the history-data collection process (alcapp) from writing history data files to the staging area. Different error codes indicate the cause of the problem more accurately:
97: History Storage Limit exceeded
99: History Capture Failure. This message hints at a disk I/O error or an internal problem.
Contact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 27 | E | HistLoadEvent | histLoadEvent | N/A |
Expected MESSAGE-TEXT
History data load error. Host = $HOST Configuration Name =$configName Storage Limit =$storageLimit Load Min Threshold =$loadMinThreshold Load Max Threshold =$loadMaxThreshold Disk Full Threshold =$diskFullThreshold Load Interval =$loadInterval Target NPS =$nps Target Database =$database Loaded Batch Size(MB) =$batchSize Staged Batches Size(MB) =$stagedSize Batch Directory =$dirName Error Code =$errCode Error Message = $errString"
ImpactThe loader process (alcloader) cannot load data into the history database. The different error codes explain the cause of the problem more accurately:
101 History Load Config Info Not Found. This message indicates that the configuration specified to collect the data cannot be found in the system. The configuration might have been dropped or renamed before the load process was started. In this case, many fields in the event rule might be set to _UNKNOWN_ (for string fields) or -1 (for integer fields).
102 History Load Failure. This message might indicate an Open Database Connectivity (ODBC) failure, such as damaged configuration data or an internal problem.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 28 | W | TransactionLimitEvent | transactionLimitEvent | N/A |
Expected MESSAGE-TEXT
The TransactionLimitEvent triggers an e-mail notification when the number of outstanding transaction objects exceeds 90% of the available objects. The maximum number of available objects is near 65000 objects. New transactions are blocked with a notification, which includes information about the oldest transaction. This repeats every three hours if the number of outstanding transactions does not drop below the 90% threshold.
ImpactThe TransactionLimitEvent triggers an e-mail notification when the number of outstanding transaction objects exceeds 90% of the available objects. The maximum number of available objects is near 65000 objects. New transactions are blocked with a notification, which includes information about the oldest transaction. This repeats every three hours if the number of outstanding transactions does not drop below the 90% threshold.
ActionTo clean up the transactions array, start the IBM DB2 Analytics Accelerator Console and run the following commands:
- nzstop
- nzstart
If the accelerator remains in a state other than Online, contact IBM support
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 29 | W | AEKSecurityEvent | aekSecurityEvent | N/A |
Expected MESSAGE-TEXT
Changes to the AEK Security configuration detected. Error string: $errString
ImpactThe AekSecurityEvent monitors and reports issues with the self-encrypting disks (SEDs) if one of the following events occurs:
- The system is in the 'Down' state because of a SPU AEK operation failure.
- A SPU AEK operation has occurred, such as the creation or change of the SPU key.
- A labelError has been detected for a SPU key on a disk. A labelError occurs if the new SPU key is not applied to a disk and the disk still uses the former key for authentication.
- A fatal disk error has been detected in connection with the SPU key. A fatal error occurs when neither the current SPU key, nor the previous SPU key can be used to authenticate the drive.
- A 'key repair' state has been detected for a disk during the creation or change of the SPU key. A key repair state is set when the key operation is deferred because a fatal key error was detected on a partner disk of the RAID.
- A key repair operation has been started on one of the disks.
Analyze the message report carefully. Conditions b and fcan be omitted. If the message indicates that an error or problem has been detected, contact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 2000 | W | Missing Reference Times | N/A | N/A |
Expected MESSAGE-TEXT
Current reference times are not available and system time cannot by synchronized
ImpactThe accelerator has not received SQL statements for processing from the DB2 subsystem that acts as the time reference system. For that reason, the system time on the accelerator cannot be properly synchronized.
ActionUse a different time reference system. If you continue to receive warnings, contact IBM support and send the queries from the time reference system to the support team.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 2001 | W | Long Running SQL Statement | N/A | N/A |
Expected MESSAGE-TEXT
SQL statement with task ID <task-id> is running for more than <age> seconds
ImpactThe execution of a single SQL statement takes a very long time. The SQL statement might hang, or the result set cannot be received by the DB2 client application.
ActionIdentify the running DB2 applications and cancel these together with the SQL statement. Submit the statement once more. If it hangs again, try to simplify the statement and isolate the section that causes the issue. Contact IBM support with the collected information.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 2002 | W | Long Running Transaction | N/A | N/A |
Expected MESSAGE-TEXT
SQL transaction with task ID <task-id> is running for more than <age> seconds
ImpactA SQL transaction is being processed endlessly in the Netezza database. The cause might be the execution of a SQL statement. However, long-running transactions might as well indicate a message-21-problem (see description above).
ActionIdentify the running DB2 applications and cancel these together with the SQL statement. Submit the statement once more. If it hangs again, try to simplify the statement and isolate the section that causes the issue. Contact IBM support with this information.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 2003 | E | Netezza Health Check Failure | N/A | N/A |
Expected MESSAGE-TEXT
Netezza health check did not complete in the allotted time of <n> seconds.
ImpactA health check of the Netezza system could not be completed, and no health check events were reported. Therefore, potential problems could not be detected.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 2004 | W | Netezza Zone Maps Layout Inconsistency Failure | N/A | N/A |
Expected MESSAGE-TEXT
Not all zone map records are consistent with the expected layout.
ImpactInconsistent zone map layout needs your attention.
ActionContact IBM support.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3000 | W | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
The current replication latency of <seconds> s on DB2 location <location> (subscription <subscription>) has exceeded the threshold of <threshold> s
ImpactThe incremental update function has detected a problem and needs your attention.
ActionCheck the replication latency. If a high latency persists for a longer time, check for factors that may contribute to the increased latency. Such factors are the size and the number of committed and uncommitted database transactions, delays when writing changes to the log, and the utilization of the accelerator.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3001 | I | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
Query acceleration was disabled for the <table> table on the <accelerator> accelerator. The origin of the table is the DB2 subsystem or data sharing group <location>. Query acceleration was disabled because the table was previously suspended from the incremental update process.
ImpactNotice saying that query acceleration was disabled for faulty tables.
ActionN/A
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3002 | E | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
Query acceleration could not be disabled for the < table> on the <acc_name> accelerator (origin of the table <location>). The action was attempted to prevent queries against obsolete data because the table was previously suspended from the incremental update process.
ImpactQuery acceleration could not be disabled for faulty tables.
ActionDisable query acceleration for these tables manually from IBM DB2 Analytics Accelerator Studio.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3003 | E | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
The replication status for DB2 location <location> (subscription <subscription> is missing, check that the replication capture agent: is running, has valid credentials, is attached to DB2 and is reachable under <ip><port> from the Accelerator network.
ImpactThe incremental update function has detected an error and needs your attention.
ActionMake sure that the CDC Capture Agent is running, uses valid credentials, is attached to DB2 and is reachable.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3004 | E | Incremental Update | N/A | n/A |
Expected MESSAGE-TEXT
The target database is offline. Replication is stopped. Check the target system.
ImpactThe incremental update function has detected a problem and needs your attention.
ActionCheck if the Netezza database (Netezza Platform Server, NPS) is running (from the IBM DB2 Analytics Accelerator Console, select 'Run Netezza Commands', then 'Get Netezza status'. The status must be online.)
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3005 | E | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
The target database is online again. Replication will be re-started if it was active prior to the outage.
ImpactInformation about the recovery of the target database.
ActionN/A
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3006 | E | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
The replication status for DB2 location <locationname> is '<status>' and replication could not be restarted. Unsuccessful restart attempts: <number>. Check the incremental update components (Access Server, Replication Engine). Consider a restart from the IBM DB2 Analytics Accelerator Console. Contact IBM support if the problem persists.
ImpactThe incremental update function has detected an error and needs your attention.
ActionCheck the incremental update components (Access Server, Replication Engine). Consider a restart from the IBM DB2 Analytics Accelerator Console. Contact IBM support if the problem persists.
| DSNX881I-ID | Severity | Accelerator Event Category | NPS Event Category | Call-Home PMR Severity |
| 3007 | E | Incremental Update | N/A | N/A |
Expected MESSAGE-TEXT
The replication status for DB2 location <locationname> is 'STARTED' again. Replication was restarted successfully.
ImpactInformation about the recovery of the incremental update components.
ActionN/A
All of these MESSAGE-IDs are used by version 2.1.x, version 3.1.x, version 4.1.x and version 5.1.x of IBM DB2 Analytics Accelerator for z/OS, with the following exceptions:
- MESSAGE-IDs 20 and 21 are not used by version 2.1.x
- MESSAGE-IDs 23 and 24 become available starting with version 4.1.0 PTF-2
- MESSAGE-IDs 26, 27, 28, 29, 2001 and 2002 become available starting with version 4.1.0 PTF-5
- MESSAGE-ID 2003 becomes available starting with version 4.1.0 PTF-6
- MESSAGE-ID 2004 becomes available starting with version 5.1.0 PTF-1a
- MESSAGE_IDs 3000, 3001, 3002, 3003, 3004, 3005, 3006 and 3007 become available starting with version 5.1.0 PTF-2
The diagnostic information in a message with MESSAGE-ID 23 comes from the System HealthCheck Tool.
For more information, see the official documentation of this tool.
IMPORTANT: A false MESSAGE-ID 23 alarm regarding a missing configuration of RPC hosts has been reported for IBM PureData System for Analytics N1001-3 (TwinFin 3).
An example of such a message can be seen in Example 4: False alarm in TF3 Systems further down in this article.
The message can be ignored if the system is running and in a healthy state. Otherwise, contact IBM Support and provide an accelerator trace file that includes detailed Netezza diagnostics.
The "Call-Home PMR Severity" column of the previous table shows the severity levels for PMRs opened by the call-home function of IBM DB2 Analytics Accelerator for z/OS.
That is, these events lead to an automatic creation of a PMR and an automatic event notification if the call-home function is properly configured and enabled.
In case the cluster state indicates that the IBM DB2 Analytics Accelerator for z/OS appliance is in an unhealthy state, the severity level will automatically be raised to severity 2 at the time of the PMR generation.
In addition, if the current database management system state is offline or down, the severity increases to level 1, correctly reflecting the outage of the system in the PMR. The call-home function became available with product version 4, PTF-4.
The "NPS Event Category" column of the previous table uses the names of template event rules as described in the "IBM Netezza System Administrator's Guide".
This guide is included in every "IBM Netezza NPS Software and Clients" fix pack that is available on IBM Fix Central.
The fix packs contain the IBM Netezza System Administrator's Guide" in PDF format.
If the "NPS Event Category" column is empty, this only means that the source of the event is different from the event rules of the Netezza Performance Server.
Examples
Example 1: System messages for a failover from accelerator host 1 to host 2
SDSF SYSLOG
Command ===>
Date Time Message ID ----+----1----+----2----+----3----+----4----+----5----+----6----+----7
***** ******** ********** ******************************************** TOP OF MESSAGES ********
17OCT 00:05:59 DSNX809I DSNX809I -DA35 DSNX8TER ACCELERATOR PROCESSING STOP COMPLETE
17OCT 00:09:04 DSNX922I DSNX922I -DA12 DSN3AMT3 BEGINNING DISCONNECTION OF
17OCT 00:09:04 DSNX922I STORED PROCEDURE ADDRESS SPACES FROM DB2
17OCT 00:09:14 DSNX923I DSNX923I -DA12 DSN3AMT3 ALL STORED PROCEDURE ADDRESS
17OCT 00:09:14 DSNX923I SPACES ARE NOW DISCONNECTED FROM DB2
17OCT 00:09:28 DSNX809I DSNX809I -DA12 DSNX8TER ACCELERATOR PROCESSING STOP COMPLETE
17OCT 00:31:50 DSNX801I DSNX801I -DA12 DSNX8INI ACCELERATOR PROCESSING STARTING
17OCT 00:33:19 DSNX801I DSNX801I -DA35 DSNX8INI ACCELERATOR PROCESSING STARTING
17OCT 00:33:22 DSNX891I DSNX891I -DA35 DSNX8CTG DSNACCEL OBJECT DSNACCEL DOES NOT EXIST
17OCT 00:33:22 DSNX895I DSNX895I -DA35 DSNX8IN2 DSNACCEL IS UNAVAILABLE
17OCT 00:33:22 DSNX800I DSNX800I -DA35 DSNX8IN2 ACCELERATOR FUNCTION IS NOT AVAILABLE
17OCT 10:51:47 DSNX881I DSNX881I -DA12 1 I 1 (17-Oct-12, 10:41:59 EDT) NPS
17OCT 10:51:47 DSNX881I system netezza1 went from online to offliningNow at 17-Oct-12,
17OCT 10:51:47 DSNX881I 10:41:59 EDT User initiated. Event: eventType: sysStateChanged
17OCT 10:51:47 DSNX881I eventTimestamp: 17-Oct-12, 10:41:59 EDT eventArgs:
17OCT 10:51:47 DSNX881I previousState=online, currentState=offlin
17OCT 10:51:47 DSNX881I DSNX881I -DA12 1 I 2 (17-Oct-12, 10:42:01 EDT) NPS
17OCT 10:51:47 DSNX881I system netezza1 went from offliningNow to offlineNow at 17-Oct-12,
17OCT 10:51:47 DSNX881I 10:42:01 EDT User initiated. Event: eventType: sysStateChanged
17OCT 10:51:47 DSNX881I eventTimestamp: 17-Oct-12, 10:42:01 EDT eventArgs:
17OCT 10:51:47 DSNX881I previousState=offliningNow, currentSt
17OCT 10:51:47 DSNX881I DSNX881I -DA12 1 I 3 (17-Oct-12, 10:50:35 EDT) NPS
17OCT 10:51:47 DSNX881I system netezza2 went from discovering to initializing at 17-Oct-12,
17OCT 10:51:47 DSNX881I 10:50:35 EDT User initiated. Event: eventType: sysStateChanged
17OCT 10:51:47 DSNX881I eventTimestamp: 17-Oct-12, 10:50:35 EDT eventArgs:
17OCT 10:51:47 DSNX881I previousState=discovering, currentSt
17OCT 10:51:47 DSNX881I DSNX881I -DA12 1 I 4 (17-Oct-12, 10:51:02 EDT) NPS
17OCT 10:51:47 DSNX881I system netezza2 went from initializing to initialized at 17-Oct-12,
17OCT 10:51:47 DSNX881I 10:51:02 EDT User initiated. Event: eventType: sysStateChanged
17OCT 10:51:47 DSNX881I eventTimestamp: 17-Oct-12, 10:51:02 EDT eventArgs:
17OCT 10:51:47 DSNX881I previousState=initializing, currentS
17OCT 10:51:47 DSNX881I DSNX881I -DA12 1 I 5 (17-Oct-12, 10:51:04 EDT) NPS
17OCT 10:51:47 DSNX881I system netezza2 went from initialized to preOnlining at 17-Oct-12,
17OCT 10:51:47 DSNX881I 10:51:04 EDT User initiated. Event: eventType: sysStateChanged
17OCT 10:51:47 DSNX881I eventTimestamp: 17-Oct-12, 10:51:04 EDT eventArgs:
17OCT 10:51:47 DSNX881I previousState=initialized, currentSta
17OCT 10:51:47 DSNX881I DSNX881I -DA12 1 I 6 (17-Oct-12, 10:51:08 EDT) NPS
17OCT 10:51:47 DSNX881I system netezza2 went from preOnlining to resuming at 17-Oct-12,
17OCT 10:51:47 DSNX881I 10:51:08 EDT User initiated. Event: eventType: sysStateChanged
17OCT 10:51:47 DSNX881I eventTimestamp: 17-Oct-12, 10:51:08 EDT eventArgs:
17OCT 10:51:47 DSNX881I previousState=preOnlining, currentState=
17OCT 10:51:47 DSNX881I DSNX881I -DA12 1 I 7 (17-Oct-12, 10:51:10 EDT) NPS
17OCT 10:51:47 DSNX881I system netezza2 went from resuming to online at 17-Oct-12, 10:51:10
17OCT 10:51:47 DSNX881I EDT User initiated. Event: eventType: sysStateChanged eventTimestamp:
17OCT 10:51:47 DSNX881I 17-Oct-12, 10:51:10 EDT eventArgs: previousState=resuming,
17OCT 10:51:47 DSNX881I currentState=online,
***** ******** ********** ******************************************* BOTTOM OF MESSAGES *******
Example 2: System message for a problem with the incremental update function on one accelerator
00000010 DSNX881I -DA12 20 W 1 250
00000010 (2012-08-14T15:43:12.569+02:00) Id: 4631 Subscription:
00000010 ACCEL_TF3_DWDDA11 Message: The IBM Tivoli License Manager agent is
00000010 not installed. IBM InfoSphere Change Data Delivery has been allowed
00000010 to start. Originator: com.datamirror.ts.engine.Replicati
Example 3: System message of an accelerator whose internal state changes
00000010 DSNX881I -D911 1 I 15 (01-Feb-13, 16:11:06 CET) NPS 328
00000010 system dwavmnps50.boeblingen.de.ibm.com went from online to
00000010 offliningNow at 01-Feb-13, 16:11:06 CET User initiated. Event:
00000010 eventType: sysStateChanged eventTimestamp: 01-Feb-13, 16:11:06 CET
00000010 eventArgs: previousState=on
00000010 DSNX881I -D911 1 I 15 (01-Feb-13, 16:11:06 CET) 329
00000010 line, currentState=offliningNow, eventSource=user eventSource: User
00000010 initiated event
00000010 DSNX881I -D911 1 I 16 (01-Feb-13, 16:11:07 CET) NPS 330
00000010 system dwavmnps50.boeblingen.de.ibm.com went from offliningNow to
00000010 offlineNow at 01-Feb-13, 16:11:07 CET User initiated. Event:
00000010 eventType: sysStateChanged eventTimestamp: 01-Feb-13, 16:11:07 CET
00000010 eventArgs: previousStat
00000010 DSNX881I -DA11 1 I 15 (01-Feb-13, 16:11:06 CET) NPS 331
00000010 system dwavmnps50.boeblingen.de.ibm.com went from online to
00000010 offliningNow at 01-Feb-13, 16:11:06 CET User initiated. Event:
00000010 eventType: sysStateChanged eventTimestamp: 01-Feb-13, 16:11:06 CET
00000010 eventArgs: previousState=on
00000010 DSNX881I -D911 1 I 16 (01-Feb-13, 16:11:07 CET) 332
00000010 e=offliningNow, currentState=offlineNow, eventSource=user
00000010 eventSource: User initiated event
00000010 DSNX881I -DA11 1 I 15 (01-Feb-13, 16:11:06 CET) 333
00000010 line, currentState=offliningNow, eventSource=user eventSource: User
00000010 initiated event
00000010 DSNX881I -DA11 1 I 16 (01-Feb-13, 16:11:07 CET) NPS 334
00000010 system dwavmnps50.boeblingen.de.ibm.com went from offliningNow to
00000010 offlineNow at 01-Feb-13, 16:11:07 CET User initiated. Event:
00000010 eventType: sysStateChanged eventTimestamp: 01-Feb-13, 16:11:07 CET
00000010 eventArgs: previousStat
00000010 DSNX881I -DA11 1 I 16 (01-Feb-13, 16:11:07 CET) 335
00000010 e=offliningNow, currentState=offlineNow, eventSource=user
00000010 eventSource: User initiated event
Example 4: False alarm in TF3 Systems
00000010 DSNX881I +DA11 23 E 373 (2014-05-21 11:45:21 UTC) 352
00000010 ACCELQ(10.10.10.61) SHC038 Misconfigured hostname in RPCs
00000010 Details: rack1.host1.system°NZ81349-H1é (from ibm_host) -
00000010 RPC outlets for host NZ81349-H1 is misconfigured
00000010 rack1.host2.system°NZ81299-H2é (from ibm_host) -
00000010 DSNX881I +DB2BBG 23 E 373 (2014-05-21 11:45:22 UTC) 353
00000010 ACCELQ(10.10.10.61) ets for host NZ81349-H2 is misconfigured
00000010 RPC outl Expert's Advice : Reconfigure RPC outlet using script
00000010 /nzlocal/scripts/rpc/rpcconfigure
The examples above show messages form multiple test systems (ACCEL_TF3_DWADA11and netezzaare names of accelerators;
DA11, DA12 and DA35 are the subsystem IDs (SSIDs) of connected DB2 subsystems).
Original Publication Date
11 February 2013
Product Synonym
IDAA
Was this topic helpful?
Document Information
Modified date:
15 September 2023
UID
swg27037905