Question & Answer
Question
What is the maximum number of connections to a database with IBM Rational Integration Tester (RIT) and how do you estimate the necessary value required?
Answer
Configuring the Maximum Number of Connections
When creating a database connection from RIT in Architecture School Physical View there is a setting "Maximum Number of Connections" which determines the number of connections to the given database which will be available in the database connection pool.
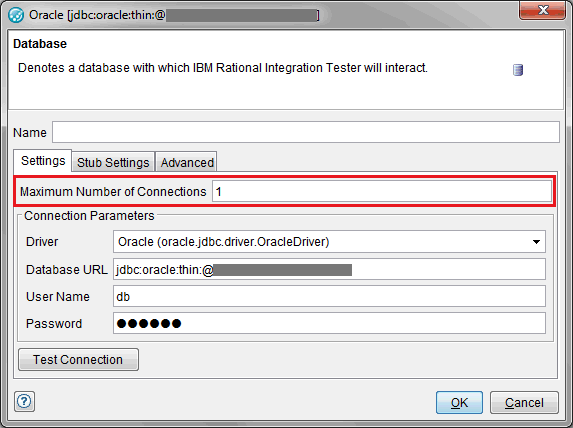
The default setting of 1 is suitable in the most common case where SQL Query, SQL Command and Stored Procedure Actions (which use the database connection) are executed in series in tests and are located in tests which are themselves executed in series.
However a higher setting will almost always be required where these Actions are used in stubs or in tests which execute in parallel. (N.B. Tests in a test suite may be configured to run in parallel.)
What error is seen if this value is too low?
By setting the value to 0 and running your test or invoking your stub you can see the error which will occur when no database connection is available to the run-time environment.. For example attempting to run an SQL Query Action in a test and using an Oracle database connection run within RIT gives this error in the RIT console:
[Error] SQL Query:"select * from mytable", Cell assertions disabled, Column assertions disabled [CRRIT8792E] Error obtaining a database connection. Timeout fetch Connection from pool 7500ms
Note: The "test connection" button will still work with the maximum number of connections set to zero since the test connection does not use a connection from the connection pool.
Parallel Execution and Stubs
Most stubs are single threaded.
It is possible to spawn additional threads by using the Run Tests Action (with the "Run process in parallel" flag set). If your stubs do this to call tests which run database Actions then you will need to factor this into your calculations. It is beyond the scope of this document.
It is also possible to spawn additional threads by using the Action Group Action, but the additional threads will not make use of database connections. (Any database actions will still execute in the original thread.)
Even where the stub is single threaded it does not mean that only one instance of the thread is executing at a given time. For example a stub which is invoked via an HTTP request and takes four seconds to complete could have two invocations running in parallel if two HTTP requests are received just one second apart. Another way to cause stubs to run in parallel is to define more than one stub which responds to a given input.
It can easily be that during development of a stub two invocations are never run in parallel, but when deployed for real use parallel invocations quickly occur. Tip: Before deploying a stub write a tests which will invoke the stub a number of times in parallel.
How to calculate the number of connections
The number of connections required is equal to the maximum number of concurrent database actions which will actually take place. An estimate for this figure must be calculated.
For tests containing database actions this must be done on a case by case basis. For stubs we can define a more rigorous method for estimating the required pool size.
First we should estimate the maximum stub invocations per minute. This requires some knowledge of the system under test. We should consider if the stub is invoked by a user action, or by a computer program running in a batch style. Are there likely to be peak times in the system. Is the workflow to the stub smoothed by the receipt of messages via a message queue (which consequently enables a backlog of requests to build up and then be processed once resources are available). Keep this estimate as accurate as possible (and don't build in a margin or error yet).
Then we need to figure out how long each invocation of the stub will take (or to be more precise how long the database actions will take to execute during the stub invocation). An initial value for this can be done by invoking the stub and timing it. This value may increase when the system is under heavy load and so ideally it would be reviewed later.
If we take the time each invocation will take and multiply it by the number of invocations per minute and then divide by one minute (and round up to a whole number) we get a value for the number of database connections which will be required if the load is perfectly smoothed.
We also need to take account of the fact that in the real world the load will be spiky and not smooth. As a rule of thumb for a reasonably smooth system we can multiply by three. For a spiky system this factor may need to be far higher.
Can we limit the maximum number of concurrent invocations?
Yes.
This is done by opening the stub editor, and on the properties tab in the concurrency group specifying the number of workers and selecting either of the "one-to-one" execution styles. The default is 10.
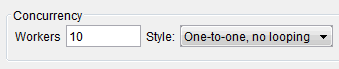
This is a good solution if the stub is being invoked via a message queue, but if we are receiving requests via an HTTP transport then all we have done is to move the problem back to the point where the stub invocation is attempted. We should consider carefully whether this accurately emulates the system under test we are attempting to stub.
An example calculation
Given the following starting assumptions:
- The maximum invocations per minute is 70.
- The stub execution time is typically 15 seconds.
- The load is reasonably smooth.
Then we can calculate:
- 70 invocations * 15 seconds = 7 minutes and 30 seconds of computer time.
- So (rounding 7 minutes 30 seconds upwards) 8 workers will be required under a perfectly smooth load.
- Applying our rule of thumb for smooth load then 8 workers times 3 is 24 workers.
- So 24 workers will require up to 24 database connections.
Where the number of workers (or concurrency) has been throttled then the throttled number of workers can be used instead, where it is lower than the above calculation would suggest.
Why not just define a pool size of 1,000,000 ?
The down-side to increasing the number of connections is that it will increase memory usage on both the RIT Agent and on the database server.
To protect the database server the relational database management system will also a configurable maximum number of total connections (from all clients combined) which the DBA may configure.
Was this topic helpful?
Document Information
Modified date:
11 July 2019
UID
swg21696360